勘误:《面经手册》,第3篇《HashMap核心知识》 关于扰动函数图像对比的比较
问题:原文中指出:从这两种的对比图可以看出来,在使用了扰动函数后,数据分配的更加均匀了
答案:其实不然,因为对比的坐标系不同,见下图
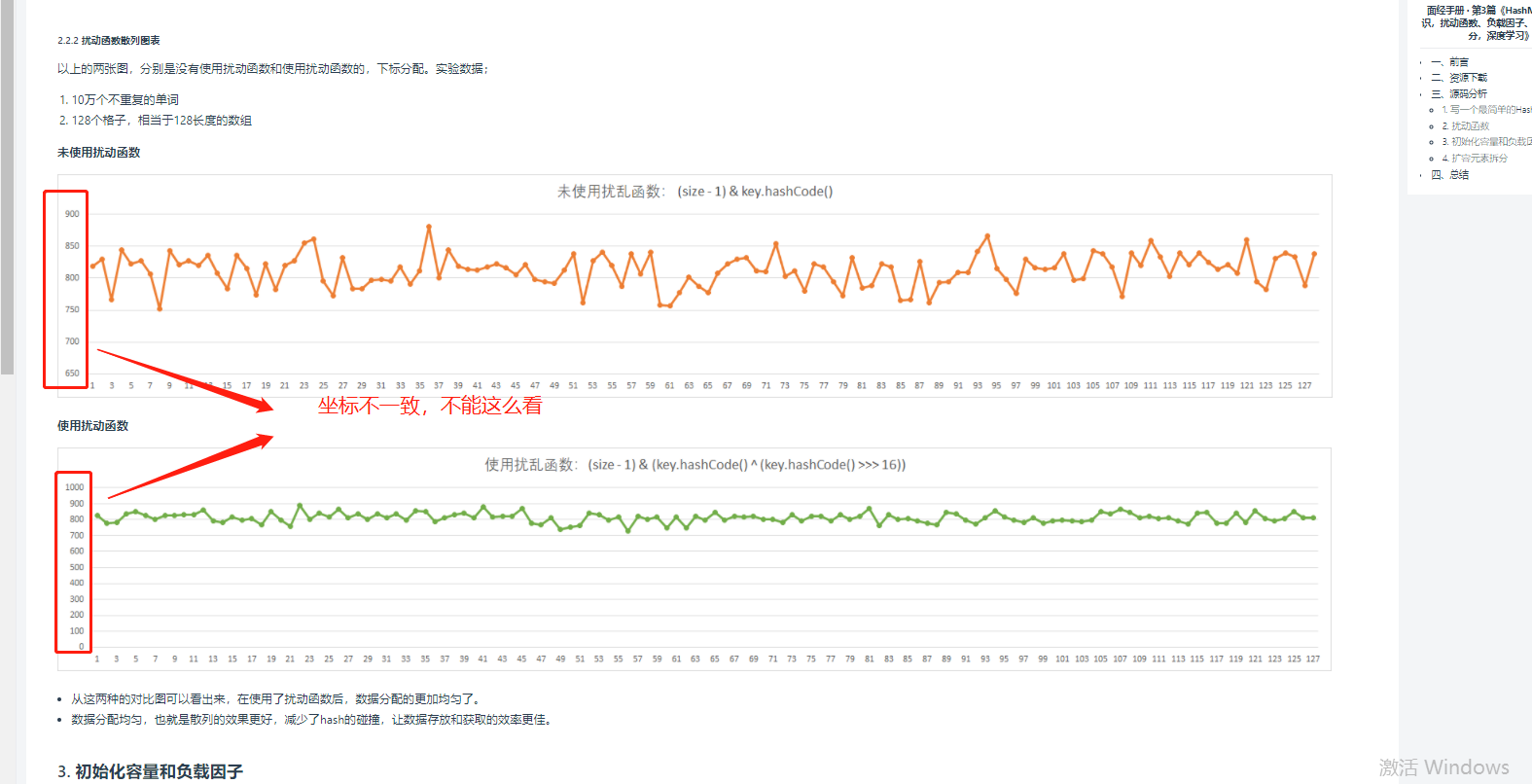
 总结:至少从上述数据看,扰动函数并不能使数据分配的更加均匀
疑惑:那扰动函数的作用到底是啥呢?单个数据能否认作者数据分配的更加均匀的观点么?以后还需要继续考究
总结:至少从上述数据看,扰动函数并不能使数据分配的更加均匀
疑惑:那扰动函数的作用到底是啥呢?单个数据能否认作者数据分配的更加均匀的观点么?以后还需要继续考究
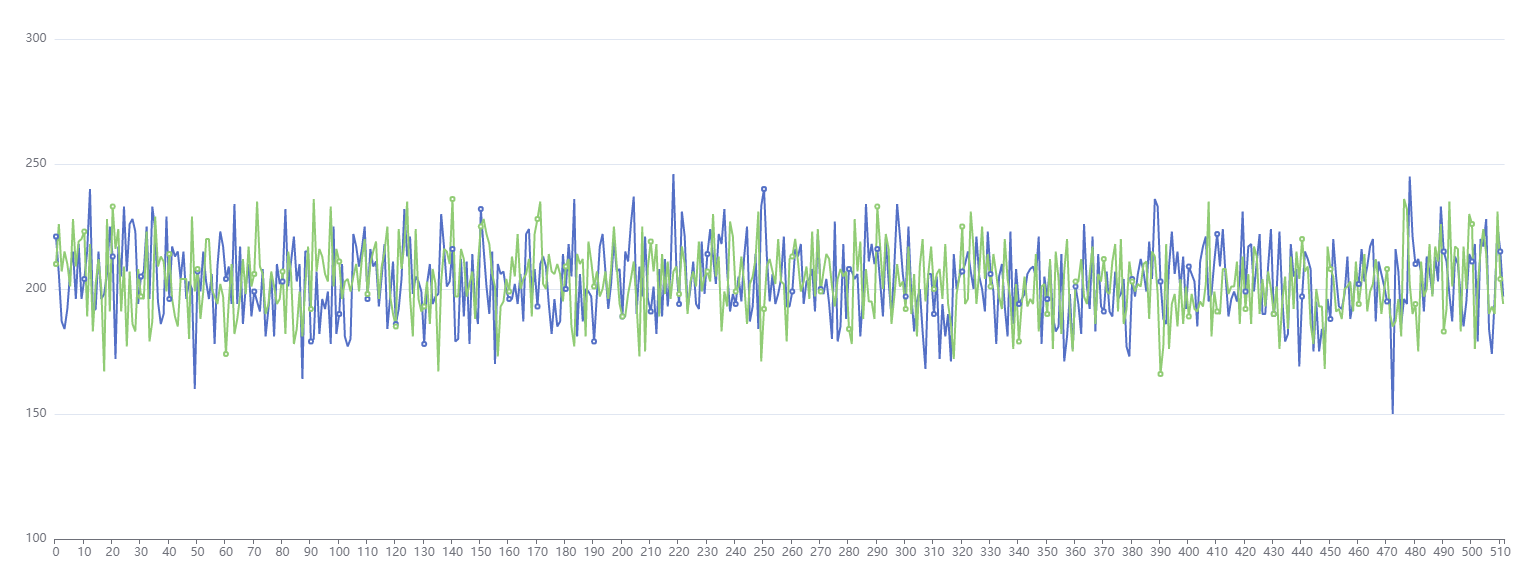
谢谢回复,我都快忘了这件事了。。。看到回复我又看了下官方文档,找到了这么一段注释 Because many common sets of hashes are already reasonably distributed (so don't benefit from spreading) 因为许多常见的散列集已经被合理地分配(所以不能从传播中受益)
因此:我觉得最初确实是为了解决hash分布更均匀的问题,但是目前大多数的hash计算已经很均匀了,因此其结果扰动后,影响不大(甚至就会出现和原来相比,略微不均匀的情况), 举个例子(不一定很恰当): 磨东西:以前hash之后的,不是很平,加上磨砂纸(扰动函数)会把物件磨得很平;但是呢,现在的hash已经把物件磨得很平,很均匀了,就像镜子一样,然后你又用了磨砂纸(扰动函数),把镜子就糊了。。。 源码如下: /** * Computes key.hashCode() and spreads (XORs) higher bits of hash * to lower. Because the table uses power-of-two masking, sets of * hashes that vary only in bits above the current mask will * always collide. (Among known examples are sets of Float keys * holding consecutive whole numbers in small tables.) So we * apply a transform that spreads the impact of higher bits * downward. There is a tradeoff between speed, utility, and * quality of bit-spreading. Because many common sets of hashes * are already reasonably distributed (so don't benefit from * spreading), and because we use trees to handle large sets of * collisions in bins, we just XOR some shifted bits in the * cheapest possible way to reduce systematic lossage, as well as * to incorporate impact of the highest bits that would otherwise * never be used in index calculations because of table bounds. */ static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }