小鹤音形词库问题
醯 这个字的定位可能有问题,想了解一下flypy_zrmfast.dict.yaml 这个文件是怎么生成的。

这个字明明读xi,但每次输入hd这个字总在第一个


从.yaml文件里把这行删除也不行
我的码表是从朙月拼音的码表转换来的,那里面把“醯”当成多音字,同时有 hai, xi 两个读音。这部分的问题或许可以直接和朙月拼音的码表维护者反馈一下(虽然我目前也不知道该找谁…)。为了保持使用体验尽可能与 Rime 的自带拼音一致,我倾向于不在自己的项目里直接进行码表修改,而是先等待上游的更新。
通常情况下不需要删字,只需要在空格上屏某个字/词之前,按 Ctrl+Delete 清零这个字/词的输入记录,就可以让它不要继续排到候选列表的前面了。
如果非要在固态字典里删字的话,部署前可能还需要从用户字典里也把它删掉。默认的用户字典保存为二进制格式、不便直接编辑,可以考虑先在 flypy_zrmfast.custom.yaml 里开启“用户词典记录为文本格式”、部署,然后用户字典会保存成 flypy_zrmfast.txt,从里面也删除要删的字以后再重新部署,确认删除成功后可以重新使用二进制格式的用户字典。(不排除直接修改 sync/ 下的用户字典也可以,不过我对这方面不熟。)
源头应该是这个,提了issue了,不过看起来之前也有人提类似的issue,佛振都没有处理。不知道他这个字典库是从哪里搞来的 https://github.com/rime/rime-luna-pinyin/issues/48
你好,我也有对 flypy_zrmfast.dict.yaml 这个文件是怎么生成的比较感兴趣,我想扩充词库,实现能在使用辅助码的同时可用外部大词库,主要困难是怎么生成辅助形码, 可否提供工具,参考链接,谢谢
你好,我也有对 flypy_zrmfast.dict.yaml 这个文件是怎么生成的比较感兴趣,我想扩充词库,实现能在使用辅助码的同时可用外部大词库,主要困难是怎么生成辅助形码, 可否提供工具,参考链接,谢谢
我的转换程序主要是用 Vim Script 写的,对别人来说估计既难读又难用,因此没有公开……简单描述一下我的实现方式吧,如果你(或者别人)写了一个更好用的转换程序也可以告诉我,我可以在 README 里指个路。
从 luna_pinyin.dict.yaml 开始,以这行为例:
三觭龍 san ji long
步骤 1:把全拼改成小鹤双拼
三觭龍 sj ji ls
步骤 2:用 opencc 改简体
三觭龙 sj ji ls
。这一步需要放在步骤 3 之前完成,因为 opencc 会根据词组信息进行转化,比如不会把“乾坤”转化成“干坤”。
步骤 3:把文字放到对应的拼音后
sj三 ji觭 ls龙
。这一步要小心有 安娜·卡列尼娜 这样的词。可以先把文件里的特殊符号先都去掉,我用的 Vim 命令是
:%s/[;·,。;:“”‘’《》()!?、…—]//ge
步骤 4:把文字转换成形码
sj[hh ji觭 ls[yp
。这步我用 Lua 脚本完成,运行脚本时从 stdin 输入整个文件,把结果输出到 stdout。脚本大概长这样:
local map_dict={
['〇']='[vv',
['一']='[hh',
---- 此处省略 7k+ 行
['龠']='[rh',
[' ']=' '}
res=io.read('*a'):gsub('[\0-\x7F\xC2-\xF4][\x80-\xBF]+', map_dict)
print(res)
其中文字与形码的对应关系来自 蓝天双拼+自然快手 这个文件,用正则表达式可以改写成上面这个 Lua 脚本中的形式。
步骤 5:处理没有对应形码的文字
sj[hh ji[[ ls[yp
。其实只要把非 ASCII 字符都换成 [[ 就好了,我用的 Vim 命令是
:%s/[^\x0-\x7f]/[[/g
步骤 6:把字典里原来的繁体词组加上
三觭龍 sj[hh ji[[ ls[yp
。我用了 bash 的 paste 命令,把繁体词组放在另一个文件(去掉拼音)以后,和之前一直在编辑的(双拼双形)文件合并。当然用其他办法合并也不难。
步骤 7:细节问题,“乾”这个字在转简体的时候还是有一些被搞错了,误转成了“干”。把所得码表里出现的 qm[hu 都改成 qm[ur(如果是小鹤形码,qm[au 改 qm[uq)。不过似乎把这步放在步骤 3、4 之间做更安全一点,那里可以直接把 qm干 改成 qm乾。
感谢楼上 @functoreality 耐心实例讲解, 看起来确实有点小复杂, 大概尝试了一下,也确实遇到一些您提到的需要注意的问题。目前我主要使用小鹤双拼和它的的形码, 在网络上没搜到它的形码单字文件,您那边有吗,可否方便提供,谢谢。 另外我基于您的项目增加了双拼词库(没有形码),目前使用起来也还可以,在这里感谢您的付出🙏🏻,👍
这个好像是有版权的,估计得逆向,可以看看openfly里面有没有。http://react.xhup.club/search 这里可以查
我找到了一个带形码的单字文件,也看到了 openfly 。 附上链接: https://github.com/zhuangzhemin/Rime/blob/master/flypy_chars.dict.yaml
目前我主要使用小鹤双拼和它的的形码, 在网络上没搜到它的形码单字文件,您那边有吗,可否方便提供,谢谢。
我的小鹤形码是贴吧吧友给的(当时是 贴吧帖子 10 楼,文件现在应该是失效了)。如果这份码表有版权的话,我其实现在不太确定我是否被授权转发了…… 另外 lu输入法 往期(1.5.2 及以前)release 有 Rime 挂接方案,我记得里面也有带小鹤形码的码表,只是字比别人给我的那份少一些。并且有的字形码不唯一,如果要用它的话,可能需要自己去重。
另外我基于您的项目增加了双拼词库(没有形码),目前使用起来也还可以
我似乎记得外挂的码表可以只有文字部分,不写拼音,Rime 会根据单字的编码自动生成词组的编码,这样就不需要做复杂的码表转换。不过对有多音字的词组来说可能会稍微有些不方便。
我似乎记得外挂的码表可以只有文字部分,不写拼音,Rime 会根据单字的编码自动生成词组的编码,这样就不需要做复杂的码表转换。不过对有多音字的词组来说可能会稍微有些不方便。
好的,谢谢, 目前还在学习rime配置中,还在研究比较合适的方案
如果你(或者别人)写了一个更好用的转换程序也可以告诉我 https://github.com/boomker/rime-flypy-xhfast/blob/15664c597644bd41410ec4595cece88a6452a1bf/scripts/flypy_dict_generator_new.py https://github.com/boomker/rime-flypy-xhfast/blob/15664c597644bd41410ec4595cece88a6452a1bf/scripts/xhxm_map.py 目前支持 全拼拼音转小鹤双拼 、简拼,常见汉字转小鹤形码。 自然码我不用(没看到过官网,教程不全的样子), 我暂时不支持了,后面要用自然码方案的时候,再支持吧 脚本如果有bug ,可以联系我修
目前支持 全拼拼音转小鹤双拼 、简拼,常见汉字转小鹤形码。 自然码我不用(没看到过官网,教程不全的样子), 我暂时不支持了,后面要用自然码方案的时候,再支持吧 脚本如果有bug ,可以联系我修
感谢,已更新 README。 我还没有完整地读一遍这份代码。里面似乎没有用到 opencc,不过如果外挂码表很多都是纯简体的码表的话,也确实不需要做繁简转换这一步。 PS:自然码双拼我是靠 Rime 拼写运算支持的,这部分不需要写到码表里面。如果是自然快手形码的话,我对它的规则的了解也仅限于 README 里的那张图😂
@boomker 老哥真有执行力,不过这个码表似乎有问题,我用了几个非小鹤官方的方案发现的。

威 这个字在小鹤官网查到的形码是 wwxn,而很多其他的方案给的确是你这个码表,我都不知道哪个是对的了
@boomker 老哥真有执行力,不过这个码表似乎有问题,我用了几个非小鹤官方的方案发现的。
威 这个字在小鹤官网查到的形码是 wwxn,而很多其他的方案给的确是你这个码表,我都不知道哪个是对的了
这个发现很有意思, 官网查到应该是正确的。可以参考其他例字:

 严格来说,上图(来自小鹤官方)种“咸”的形码是
严格来说,上图(来自小鹤官方)种“咸”的形码是wk, “戌” 里面的一横是连接的,“威, 咸”这两字里面的 '-'(横)是两端有空隙的
感谢,已更新 README。 我还没有完整地读一遍这份代码。里面似乎没有用到 opencc,不过如果外挂码表很多都是纯简体的码表的话,也确实不需要做繁简转换这一步。 PS:自然码双拼我是靠 Rime 拼写运算支持的,这部分不需要写到码表里面。如果是自然快手形码的话,我对它的规则的了解也仅限于 README 里的那张图😂
感谢大佬,暂时还没考虑繁体转简体, 我转换的词库来源雾凇拼音项目的词典文件,内容基本上是简体的
这个发现很有意思, 官网查到应该是正确的。可以参考其他例字:
wk, “戌” 里面的一横是连接的,“威, 咸”这两字里面的 '-'(横)是两端有空隙的
所以可能是这些衍生的码表来自比较早期的鹤形,而官方鹤形一直在更新。
所以可能是这些衍生的码表来自比较早期的鹤形,而官方鹤形一直在更新
有可能, 也有可能是其他人在整理码表时,自己加上的形码 其实用什么形码,以及形码是否与官方一致不是那么重要,只要使用者对形码的编码能熟练使用,达到快速筛字上屏的目的即可
如果你(或者别人)写了一个更好用的转换程序也可以告诉我 https://github.com/boomker/rime-flypy-xhfast/blob/15664c597644bd41410ec4595cece88a6452a1bf/scripts/flypy_dict_generator_new.py https://github.com/boomker/rime-flypy-xhfast/blob/15664c597644bd41410ec4595cece88a6452a1bf/scripts/xhxm_map.py 目前支持 全拼拼音转小鹤双拼 、简拼,常见汉字转小鹤形码。 自然码我不用(没看到过官网,教程不全的样子), 我暂时不支持了,后面要用自然码方案的时候,再支持吧 脚本如果有bug ,可以联系我修
win10上运行转换脚本出错, 麻烦大佬看下
win10上运行转换脚本出错, 麻烦大佬看下
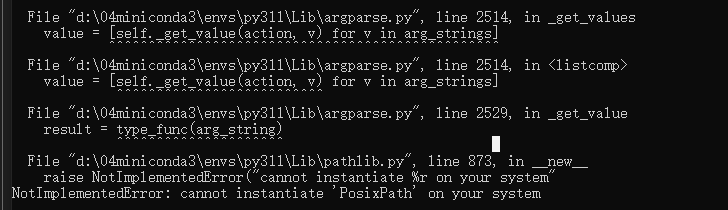
我自己又新开一个仓库, 新仓库的脚本有更新, 我贴一下地址: 新仓库地址 flypy_dict_generator_new.py xhxm_map.py
你那边先尝试用一下我的新脚本跑一下, 如果还有问题的话, 麻烦你在我的项目提 issue . 这样方便点, 这里的反馈我也会持续关注的.
然后的话, 脚本执行需要确保: 你的 python 版本是3 以上, 最好是3.11吧, 还需要安装依赖包 pypinyin
最后 window 系统, 你可能需要修改这个脚本的第一行 #!/usr/local/bin/python3.11 为你 python3 可执行程序的所在路径, 最好 python 安装目录放到环境变量里
希望能帮到你, 愉快~
在windows上是好的 ,但是安卓最新版V3.2.11上,老是打出来繁体字,比如输入单字艳的小鹤双拼码yj[fb] 会看到 豔 艳两个候选,繁体的在前面;如果是输入词语,比如终于的码vsyu,则出来的就是繁体的終於,在前五个候选里都看不到简体的终于,甚至翻了两三页都看不到简体的,请教下,这可能是什么 问题; 用的小鹤辅助码,设置了直接辅助码 @functoreality
在windows上是好的 ,但是安卓最新版V3.2.11上,老是打出来繁体字,比如输入单字艳的小鹤双拼码yj[fb] 会看到 豔 艳两个候选,繁体的在前面;如果是输入词语,比如终于的码vsyu,则出来的就是繁体的終於,在前五个候选里都看不到简体的终于,甚至翻了两三页都看不到简体的,请教下,这可能是什么 问题; 用的小鹤辅助码,设置了直接辅助码 @functoreality
是不是没调成简体输入?Rime 有区分简体繁体模式,安卓版本我这里可以看到切换键(没输入的时候在输入栏的第 3 个按键),但不太清楚新版本的键盘布局有没有修改
感谢,已更新 README。 我还没有完整地读一遍这份代码。里面似乎没有用到 opencc,不过如果外挂码表很多都是纯简体的码表的话,也确实不需要做繁简转换这一步。 PS:自然码双拼我是靠 Rime 拼写运算支持的,这部分不需要写到码表里面。如果是自然快手形码的话,我对它的规则的了解也仅限于 README 里的那张图😂
感谢大佬,暂时还没考虑繁体转简体, 我转换的词库来源雾凇拼音项目的词典文件,内容基本上是简体的 这位大哥 想请教一下你做的简体词库能调用吗?我把雾凇词库的文字词组文本直接复制进lypy_zrmfast.dict.yaml里面发现无法调用,你方便分享一下你扩充的词库吗?
这位大哥 想请教一下你做的简体词库能调用吗?我把雾凇词库的文字词组文本直接复制进lypy_zrmfast.dict.yaml里面发现无法调用,你方便分享一下你扩充的词库吗?
我用的时小鹤双拼,如果你用的是自然码,是没法直接套用的哈
不建议直接拷到flypy_zrmfast.dict.yaml文件里,一是编码不一样,没法用;二是后续更新维护不方便
使用雾凇词库来作为扩展词库的话,有两种方式:
- 写拼音运算规则,达到纯全拼到双拼的转换,这个雾凇的仓库已经带有各种双拼的方案了,这种最容易,成本低
- 将雾凇的词库的所有词条转为双拼的,我项目仓库里词库都是这种,但只适配小鹤双拼。 另外,我仓库里简体词库转双拼词库,也只适配了小鹤双拼了,如果要适配其他双拼,得改代码(全拼到双拼的映射)
你好,我也有对 flypy_zrmfast.dict.yaml 这个文件是怎么生成的比较感兴趣,我想扩充词库,实现能在使用辅助码的同时可用外部大词库,主要困难是怎么生成辅助形码, 可否提供工具,参考链接,谢谢
我的转换程序主要是用 Vim Script 写的,对别人来说估计既难读又难用,因此没有公开……简单描述一下我的实现方式吧,如果你(或者别人)写了一个更好用的转换程序也可以告诉我,我可以在 README 里指个路。 从
luna_pinyin.dict.yaml开始,以这行为例:三觭龍 san ji long步骤 1:把全拼改成小鹤双拼
三觭龍 sj ji ls步骤 2:用 opencc 改简体
三觭龙 sj ji ls。这一步需要放在步骤 3 之前完成,因为 opencc 会根据词组信息进行转化,比如不会把“乾坤”转化成“干坤”。步骤 3:把文字放到对应的拼音后
sj三 ji觭 ls龙。这一步要小心有安娜·卡列尼娜这样的词。可以先把文件里的特殊符号先都去掉,我用的 Vim 命令是:%s/[;·,。;:“”‘’《》()!?、…—]//ge步骤 4:把文字转换成形码
sj[hh ji觭 ls[yp。这步我用 Lua 脚本完成,运行脚本时从 stdin 输入整个文件,把结果输出到 stdout。脚本大概长这样:local map_dict={ ['〇']='[vv', ['一']='[hh', ---- 此处省略 7k+ 行 ['龠']='[rh', [' ']=' '} res=io.read('*a'):gsub('[\0-\x7F\xC2-\xF4][\x80-\xBF]+', map_dict) print(res)其中文字与形码的对应关系来自 蓝天双拼+自然快手 这个文件,用正则表达式可以改写成上面这个 Lua 脚本中的形式。
步骤 5:处理没有对应形码的文字
sj[hh ji[[ ls[yp。其实只要把非 ASCII 字符都换成[[就好了,我用的 Vim 命令是:%s/[^\x0-\x7f]/[[/g步骤 6:把字典里原来的繁体词组加上
三觭龍 sj[hh ji[[ ls[yp。我用了 bash 的paste命令,把繁体词组放在另一个文件(去掉拼音)以后,和之前一直在编辑的(双拼双形)文件合并。当然用其他办法合并也不难。步骤 7:细节问题,“乾”这个字在转简体的时候还是有一些被搞错了,误转成了“干”。把所得码表里出现的
qm[hu都改成qm[ur(如果是小鹤形码,qm[au改qm[uq)。不过似乎把这步放在步骤 3、4 之间做更安全一点,那里可以直接把qm干改成qm乾。
我用 Python 重写了这个转换的脚本,放到 generate_dict/ 这个目录下面了。