wav2letter
 wav2letter copied to clipboard
wav2letter copied to clipboard
Help to solve training error
Hello,
I was training a new model. But after around 100000 iterations (maybe still in the first epoch), I got the fallowing error message.
*** Aborted at 1590963336 (unix time) try "date -d @1590963336" if you are using GNU date *** PC: @ 0x7f4bfeb7707d cuda::evalNodes<>() *** SIGFPE (@0x7f4bfeb7707d) received by PID 24362 (TID 0x7f4c29fed380) from PID 18446744073688019069; stack trace: *** @ 0x7f4c223ba390 (unknown) @ 0x7f4bfeb7707d cuda::evalNodes<>() @ 0x7f4bfeb77cbf cuda::evalNodes<>() @ 0x7f4bfe6bcaea cuda::Array<>::eval() @ 0x7f4bfd02f851 _ZN4cuda10reduce_allIL7af_op_t5EccEET1_RKNS_5ArrayIT0_EEbd @ 0x7f4bff585783 af_any_true_all @ 0x7f4bff75d584 af::anyTrue<>() @ 0x493640 _ZZ4mainENKUlSt10shared_ptrIN2fl6ModuleEES_IN3w2l17SequenceCriterionEES_INS3_10W2lDatasetEES_INS0_19FirstOrderOptimizerEES9_ddblE3_clES2_S5_S7_S9_S9_ddbl.constprop.12679 @ 0x41c3b7 main @ 0x7f4bdf447830 __libc_start_main @ 0x48e5d9 _start @ 0x0 (unknown) Floating point exception (core dumped)
The trainlogs only showed the evaluation results: epoch: 1 | nupdates: 20000 | lr: 0.000100 | lrcriterion: 0.000100 | runtime: 02:00:07 | bch(ms): 360.38 | smp(ms): 197.40 | fwd(ms): 110.20 | crit-fwd(ms): 99.57 | bwd(ms): 27.02 | optim(ms): 2.31 | loss: 292.35750 | train-TER: 155.29 | train-WER: 100.00 | lists/dev_step2.csv-loss: 71.22854 | lists/dev_step2.csv-TER: 100.00 | lists/dev_step2.csv-WER: 100.00 | avg-isz: 1600 | avg-tsz: 129 | max-tsz: 545 | hrs: 355.60 | thrpt(sec/sec): 177.61 epoch: 1 | nupdates: 40000 | lr: 0.000100 | lrcriterion: 0.000100 | runtime: 02:00:14 | bch(ms): 360.74 | smp(ms): 201.06 | fwd(ms): 107.46 | crit-fwd(ms): 97.10 | bwd(ms): 27.18 | optim(ms): 2.29 | loss: 67.33223 | train-TER: 100.00 | train-WER: 100.00 | lists/dev_step2.csv-loss: 66.89943 | lists/dev_step2.csv-TER: 100.00 | lists/dev_step2.csv-WER: 100.00 | avg-isz: 1568 | avg-tsz: 126 | max-tsz: 627 | hrs: 348.47 | thrpt(sec/sec): 173.88 epoch: 1 | nupdates: 60000 | lr: 0.000100 | lrcriterion: 0.000100 | runtime: 02:00:18 | bch(ms): 360.93 | smp(ms): 202.52 | fwd(ms): 106.80 | crit-fwd(ms): 96.50 | bwd(ms): 26.63 | optim(ms): 2.29 | loss: 63.93924 | train-TER: 100.00 | train-WER: 100.00 | lists/dev_step2.csv-loss: 64.13627 | lists/dev_step2.csv-TER: 100.00 | lists/dev_step2.csv-WER: 100.00 | avg-isz: 1556 | avg-tsz: 125 | max-tsz: 393 | hrs: 345.85 | thrpt(sec/sec): 172.48 epoch: 1 | nupdates: 80000 | lr: 0.000100 | lrcriterion: 0.000100 | runtime: 02:00:09 | bch(ms): 360.50 | smp(ms): 197.16 | fwd(ms): 110.90 | crit-fwd(ms): 100.26 | bwd(ms): 27.35 | optim(ms): 2.29 | loss: 62.70409 | train-TER: 100.00 | train-WER: 100.00 | lists/dev_step2.csv-loss: 61.74130 | lists/dev_step2.csv-TER: 100.00 | lists/dev_step2.csv-WER: 100.00 | avg-isz: 1597 | avg-tsz: 129 | max-tsz: 440 | hrs: 355.06 | thrpt(sec/sec): 177.29 epoch: 1 | nupdates: 100000 | lr: 0.000100 | lrcriterion: 0.000100 | runtime: 02:00:10 | bch(ms): 360.51 | smp(ms): 190.87 | fwd(ms): 115.64 | crit-fwd(ms): 104.50 | bwd(ms): 28.64 | optim(ms): 2.30 | loss: 62.32267 | train-TER: 100.00 | train-WER: 100.00 | lists/dev_step2.csv-loss: 59.90308 | lists/dev_step2.csv-TER: 100.00 | lists/dev_step2.csv-WER: 100.00 | avg-isz: 1679 | avg-tsz: 135 | max-tsz: 567 | hrs: 373.16 | thrpt(sec/sec): 186.32
Could you please help me to figure out where I was doing wrong? Thanks a lot!
Best, Ling
Could you send your train config? How many GPUs do you use to run? What is the dataset size?
The following is the train config: --datadir=/media/ubuntu/HDD2/wav2letter/Proj --rundir=/media/ubuntu/HDD2/wav2letter/Proj/models --archdir=/media/ubuntu/HDD2/wav2letter/Proj --train=lists/train_step2.csv --valid=lists/dev_step2.csv --input=wav --arch=network.arch --tokens=/media/ubuntu/HDD2/wav2letter/Proj/am/tokens2.txt --lexicon=/media/ubuntu/HDD2/wav2letter/Proj/am/lexicon2.txt --criterion=ctc --lr=0.0001 --lrcrit=0.0001 --maxgradnorm=1.0 --replabel=1 --surround=| --onorm=target --sqnorm=true --mfsc=true --filterbanks=40 --nthread=4 --batchsize=4 --runname=trainlogs --iter=1196042 --reportiters=20000
I used only one GPU (titanXP). The training set has 478415 samples.
Thanks!
your learning rate is too small for sgd (from my experience), try larger. About the corruption - try to run on, say, 1000 samples, probably the problem in the validation set. Do you see the same error?
Probably this, https://github.com/facebookresearch/wav2letter/issues/709#issue-641807070
@viig99 the gamma is not used here (by default it is 1), so no lr decaying happening here.
I am getting the same error trying to train TDS with CTC. I run the training command and after a few seconds it is interrupted, reporting said problem. I think it's worth noting I'm running on docker and the image passes all 31 tests.
Here is my train configuration:
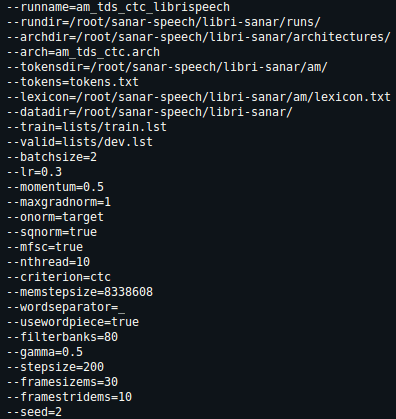
And here is my nvidia-smi output:
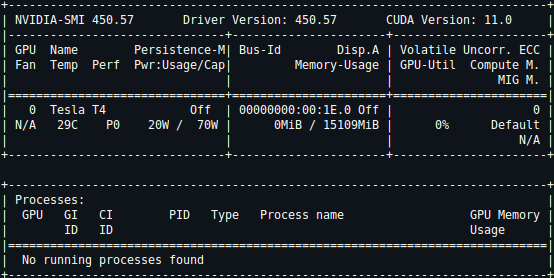
This is the first time I had the problem. Already tried LexFree and Transformer models and no such error appeared.
Any suggestions?
@Bernardo-Favoreto what exactly error do you have? Could you post here your log?
Sure @tlikhomanenko, here it is: *** Aborted at 1590963336 (unix time) try "date -d @1590963336" if you are using GNU date ***
PC: @ 0x7f4bfeb7707d cuda::evalNodes<>()
*** SIGFPE (@0x7f4bfeb7707d) received by PID 24362 (TID 0x7f4c29fed380) from PID 18446744073688019069; stack trace: ***
@ 0x7f4c223ba390 (unknown)
@ 0x7f4bfeb7707d cuda::evalNodes<>()
@ 0x7f4bfeb77cbf cuda::evalNodes<>()
@ 0x7f4bfe6bcaea cuda::Array<>::eval()
@ 0x7f4bfd02f851 _ZN4cuda10reduce_allIL7af_op_t5EccEET1_RKNS_5ArrayIT0_EEbd
@ 0x7f4bff585783 af_any_true_all
@ 0x7f4bff75d584 af::anyTrue<>()
@ 0x493640 _ZZ4mainENKUlSt10shared_ptrIN2fl6ModuleEES_IN3w2l17SequenceCriterionEES_INS3_10W2lDatasetEES_INS0_19FirstOrderOptimizerEES9_ddblE3_clES2_S5_S7_S9_S9_ddbl.constprop.12679
@ 0x41c3b7 main
@ 0x7f4bdf447830 __libc_start_main
@ 0x48e5d9 _start
@ 0x0 (unknown)
Floating point exception (core dumped)
Please try any combination of the following to get details about the root cause:
export AF_PRINT_ERRORS=1 export AF_TRACE=mem #export AF_TRACE=mem,unified export AF_MAX_BUFFERS=100 #export AF_JIT_KERNEL_TRACE=stdout
export CUDNN_LOGINFO_DBG=1 export CUDNN_LOGDEST_DBG=stderr