[FT][ERROR] CUDA runtime error: operation not supported
I am using a T4 gpu, host machine's cuda is 11.0 and driver is 450.102.04. When running launch.sh, got such error. Detail log:
fauxpilot-triton-1 | W0812 03:06:40.864778 92 libfastertransformer.cc:620] Get output name: cum_log_probs, type: TYPE_FP32, shape: [-1]
fauxpilot-triton-1 | W0812 03:06:40.864782 92 libfastertransformer.cc:620] Get output name: output_log_probs, type: TYPE_FP32, shape: [-1, -1]
fauxpilot-triton-1 | [FT][WARNING] Custom All Reduce only supports 8 Ranks currently. Using NCCL as Comm.
fauxpilot-triton-1 | I0812 03:06:41.156692 92 libfastertransformer.cc:307] Before Loading Model:
fauxpilot-triton-1 | after allocation, free 6.56 GB total 8.00 GB
fauxpilot-triton-1 | [WARNING] gemm_config.in is not found; using default GEMM algo
fauxpilot-triton-1 | terminate called after throwing an instance of 'std::runtime_error'
fauxpilot-triton-1 | what(): [FT][ERROR] CUDA runtime error: operation not supported /workspace/build/fastertransformer_backend/build/_deps/repo-ft-src/src/fastertransformer/utils/allocator.h:181
fauxpilot-triton-1 |
fauxpilot-triton-1 | [5f61fab36b85:00092] *** Process received signal ***
fauxpilot-triton-1 | [5f61fab36b85:00092] Signal: Aborted (6)
fauxpilot-triton-1 | [5f61fab36b85:00092] Signal code: (-6)
fauxpilot-triton-1 | [5f61fab36b85:00092] [ 0] /usr/lib/x86_64-linux-gnu/libpthread.so.0(+0x14420)[0x7f3a7ef7e420]
This looks similar to https://github.com/moyix/fauxpilot/issues/14 – the T4 is not that old (although you will have trouble running some of the models with only 8GB of RAM), and the compute capability is listed as 7.5, so I'm surprised it doesn't work. Could you try upgrading the version of CUDA to something more recent?
This looks similar to #14 – the T4 is not that old (although you will have trouble running some of the models with only 8GB of RAM), and the compute capability is listed as 7.5, so I'm surprised it doesn't work. Could you try upgrading the version of CUDA to something more recent?
I have already tried using cuda 10.0, 11.0, 11.2 and 11.7 in host machine. None of them works.
Did that include upgrading the NVIDIA driver? 450.102.04 seems to be fairly old (it came out in January 2021).
terminate called after throwing an instance of 'std::runtime_error' fauxpilot-triton-1 | what(): [FT][ERROR] CUDA runtime error: operation not supported /workspace/build/fastertransformer_backend/build/_deps/repo-ft-src/src/fastertransformer/utils/allocator.h:181 fauxpilot-triton-1 |
The source contents of ./utils/allocator.h:181 are as follows.
virtual ~Allocator()
{
FT_LOG_DEBUG(__PRETTY_FUNCTION__);
while (!pointer_mapping_->empty()) {
free((void**)(&pointer_mapping_->begin()->second.first));
}
delete pointer_mapping_;
}
In other words, the error seems to occur because the GDDR memory capacity of the Nvidia GPU card required to run the selected model is insufficient.
- https://github.com/NVIDIA/FasterTransformer/blob/main/src/fastertransformer/utils/allocator.h#L181
Therefore, I interpret this issue as follows:
You had 6.56 GB of free space out of the total of 8 GB before running the model of your choice. However, to execute CUDA's GEMM (General Matrix Multiply) algorithm, In the process of allocating the required memory by the CUDA runtime, due to insufficient free memory capacity, The process was killed on receiving the "aborted" signal.
The same issue.

Driver Version: 515.65.01 CUDA Version: 11.7. MODEL=codegen-350M-multi
I convert the model on my machine. I use the old Tesla M60. Maybe the operation is not supported by the card?
terminate called after throwing an instance of 'std::runtime_error' fauxpilot-triton-1 | what(): [FT][ERROR] CUDA runtime error: operation not supported /workspace/build/fastertransformer_backend/build/_deps/repo-ft-src/src/fastertransformer/utils/allocator.h:181 fauxpilot-triton-1 |
The source contents of ./utils/allocator.h:181 are as follows.
virtual ~Allocator() { FT_LOG_DEBUG(__PRETTY_FUNCTION__); while (!pointer_mapping_->empty()) { free((void**)(&pointer_mapping_->begin()->second.first)); } delete pointer_mapping_; }In other words, the error seems to occur because the GDDR memory capacity of the Nvidia GPU card required to run the selected model is insufficient.
- https://github.com/NVIDIA/FasterTransformer/blob/main/src/fastertransformer/utils/allocator.h#L181
Therefore, I interpret this issue as follows:
You had 6.56 GB of free space out of the total of 8 GB before running the model of your choice. However, to execute CUDA's GEMM (General Matrix Multiply) algorithm, In the process of allocating the required memory by the CUDA runtime, due to insufficient free memory capacity, The process was killed on receiving the "aborted" signal.
Indeed I think the code that causes this issue is https://github.com/NVIDIA/FasterTransformer/blob/a44c38134cefe17a81c269b6ec23d91cfe4e7216/src/fastertransformer/utils/allocator.h#L181
I guess some old gpus, like tesla M60, don't support 'Async cudaMalloc/Free' even with cuda version higher than 11.2. Unfortunately, Fasttransformer don't know this. Evidence is ./launch.sh does not show log like https://github.com/NVIDIA/FasterTransformer/blob/a44c38134cefe17a81c269b6ec23d91cfe4e7216/src/fastertransformer/utils/allocator.h#L126 or https://github.com/NVIDIA/FasterTransformer/blob/f73a2cf66fb6bb4595277d0d029ac27601dd664c/src/fastertransformer/utils/allocator.h#L149 .
As for @karlind, you changed the cuda version to 11.0 on host machine, but in triton_with_ft container it is still cuda 11.7.
So i think maybe we could downgrade the cuda version in triton_with_ft docker image to 11.1 to avoid this issue. And wait Fasttransformer to fix it.
Now i don't know how to rebuild the triton_with_ft image. So i can't test the case. Can anyone help me and give some suggestions? @moyix @leemgs
I rebuilt the triton_with_ft image by changing ft code like https://github.com/NVIDIA/FasterTransformer/issues/263#issuecomment-1195117403 .
Now it works. You can just use luanshaotong/triton_with_ft:22.06 instead of moyix/triton_with_ft:22.09.
~~however when I put requests, the server always returns errors.~~
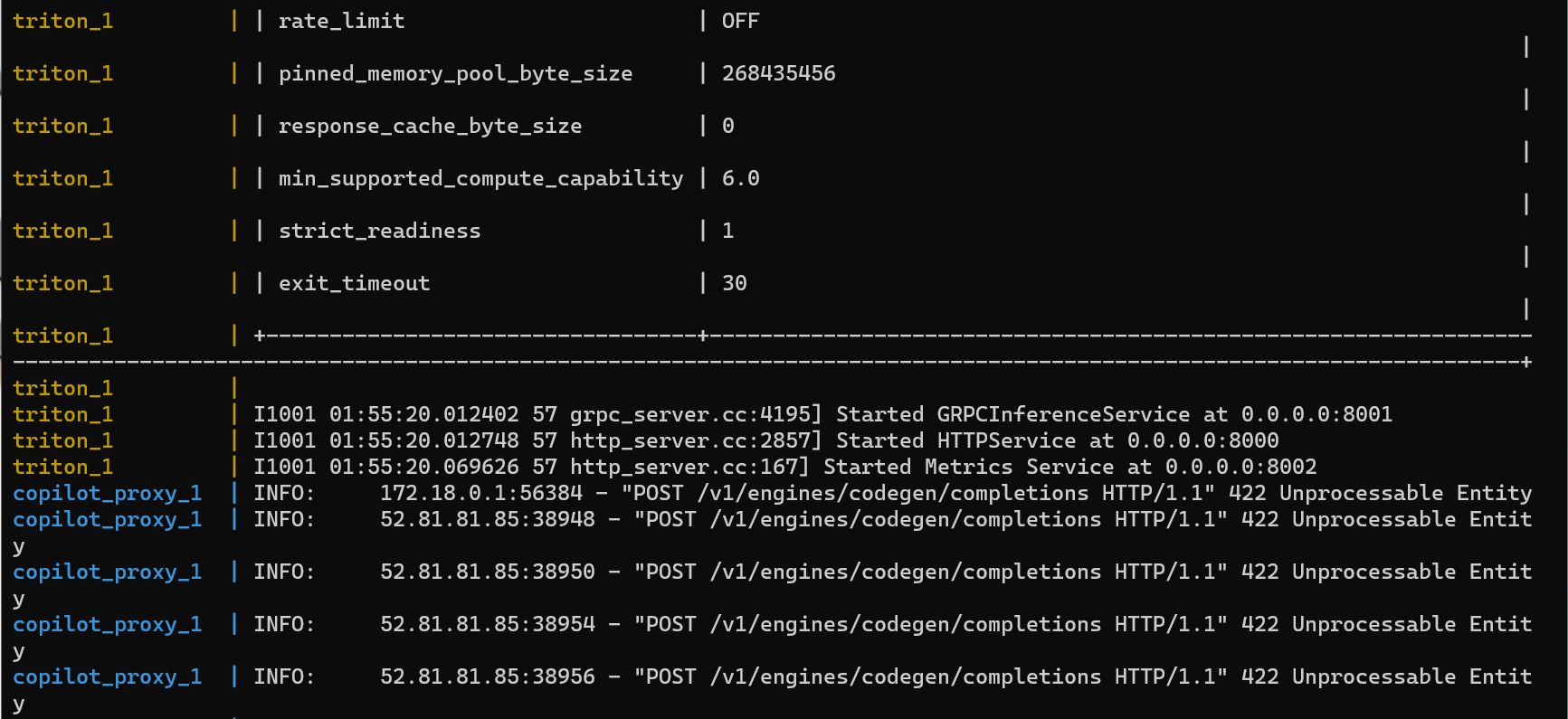
~~Details about openai api:~~
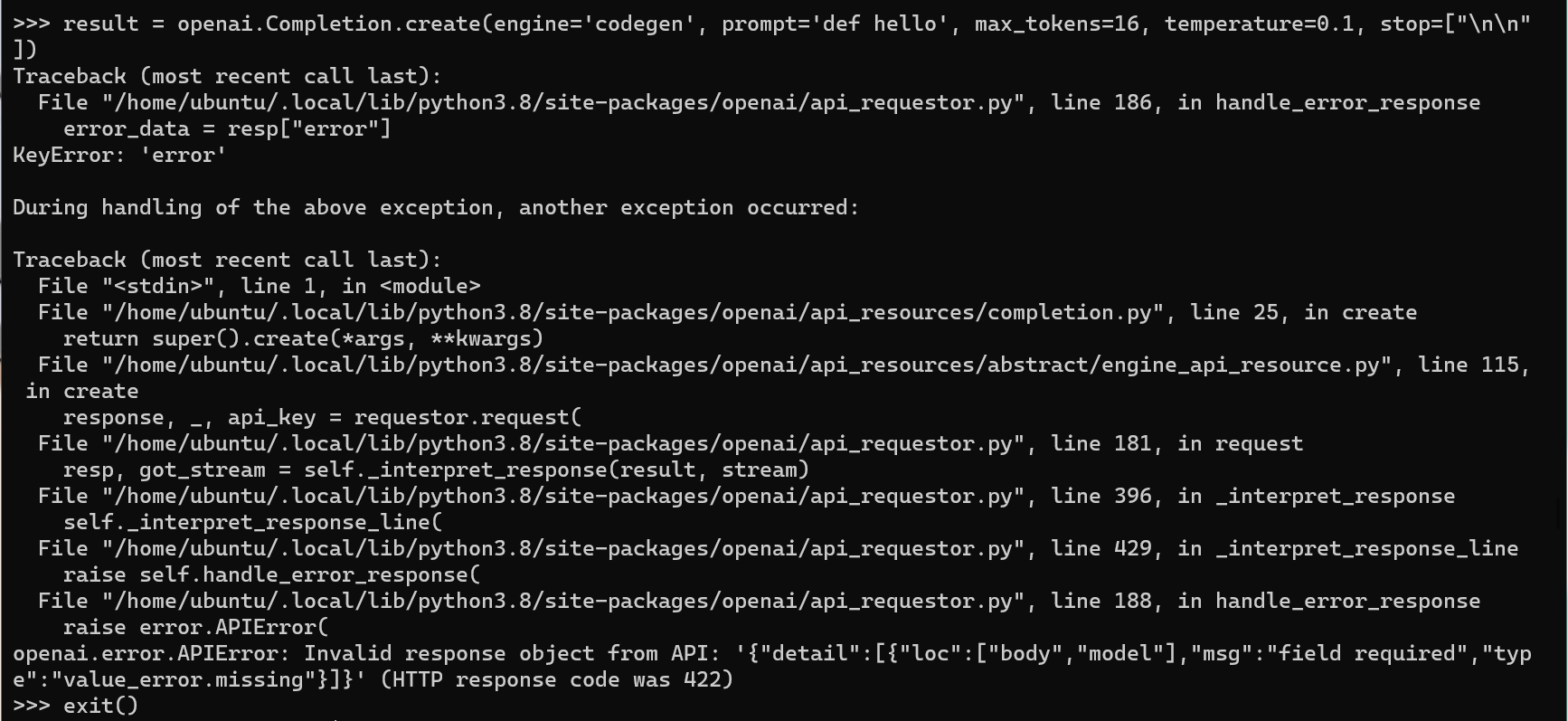
~~And the same error for vscode copilot extension.~~
~~When stoped the triton container, copilot proxy still returns error code 422. It seems like a different issue.~~
Already solved.
Sorry, I forgot to check the GPU compute capability. It's imposible to run FT on M60 which has compute capability of 5.2.
Though, I think my method will work for T4.
BTW, can I run fauxpilot on P40?
BTW, can I run fauxpilot on P40?
Could you tell me the execution result (e.g., CC, Compute Capability) of deviceQuery?
- https://github.com/NVIDIA/cuda-samples/tree/master/Samples/1_Utilities/deviceQuery
And, please, refer to the https://github.com/moyix/fauxpilot/wiki/GPU-Support-Matrix
@leemgs I tested fauxpilot on my tesla p40 using main branch, and it works well( a little bit slow ). And I'm happy that I can use 6B model on it. The compute capability of p40 is 6.1. I'll test the deviceQuery later.
And I'm happy that I can use 6B model on it.
Congrats. I think that a major reaon is a video memory capacity of your GPU on virtual ~Allocator() issue.
I am using a T4 gpu, host machine's cuda is 11.0 and driver is 450.102.04. When running launch.sh, got such error. Detail log:
fauxpilot-triton-1 | W0812 03:06:40.864778 92 libfastertransformer.cc:620] Get output name: cum_log_probs, type: TYPE_FP32, shape: [-1] fauxpilot-triton-1 | W0812 03:06:40.864782 92 libfastertransformer.cc:620] Get output name: output_log_probs, type: TYPE_FP32, shape: [-1, -1] fauxpilot-triton-1 | [FT][WARNING] Custom All Reduce only supports 8 Ranks currently. Using NCCL as Comm. fauxpilot-triton-1 | I0812 03:06:41.156692 92 libfastertransformer.cc:307] Before Loading Model: fauxpilot-triton-1 | after allocation, free 6.56 GB total 8.00 GB fauxpilot-triton-1 | [WARNING] gemm_config.in is not found; using default GEMM algo fauxpilot-triton-1 | terminate called after throwing an instance of 'std::runtime_error' fauxpilot-triton-1 | what(): [FT][ERROR] CUDA runtime error: operation not supported /workspace/build/fastertransformer_backend/build/_deps/repo-ft-src/src/fastertransformer/utils/allocator.h:181 fauxpilot-triton-1 | fauxpilot-triton-1 | [5f61fab36b85:00092] *** Process received signal *** fauxpilot-triton-1 | [5f61fab36b85:00092] Signal: Aborted (6) fauxpilot-triton-1 | [5f61fab36b85:00092] Signal code: (-6) fauxpilot-triton-1 | [5f61fab36b85:00092] [ 0] /usr/lib/x86_64-linux-gnu/libpthread.so.0(+0x14420)[0x7f3a7ef7e420]
do you have solved this problem? and finally how do you do? thanks. my gpu is T4-8C, can i load codegen-350M-mono model and build a server?