Issue running metaseq-api-local for blenderbot3_30B model
🐛 Bug
I have sharded the checkpoints into 4 parts according to the number of GPU nodes I have (4 GPUs 15gb each) and also set the TOTAL_WORLD_SIZE=4, MODEL_PARALLEL=4. but I am facing this error of "intra layer model parallel group is not initialized". I have checked the earlier issues and tried various combinations of TOTAL_WORLD_SIZE & MODEL_PARALLEL eg. (2, 2) (2, 4) (4, 4) but the same error keeps popping. Please suggest any solution.
To Reproduce
- shard blenderbot3_30B checkpoints into 4 parts.
- set the path of model path, bpe file path, and MODEL_PARALLEL
- execute metaseq-api-local
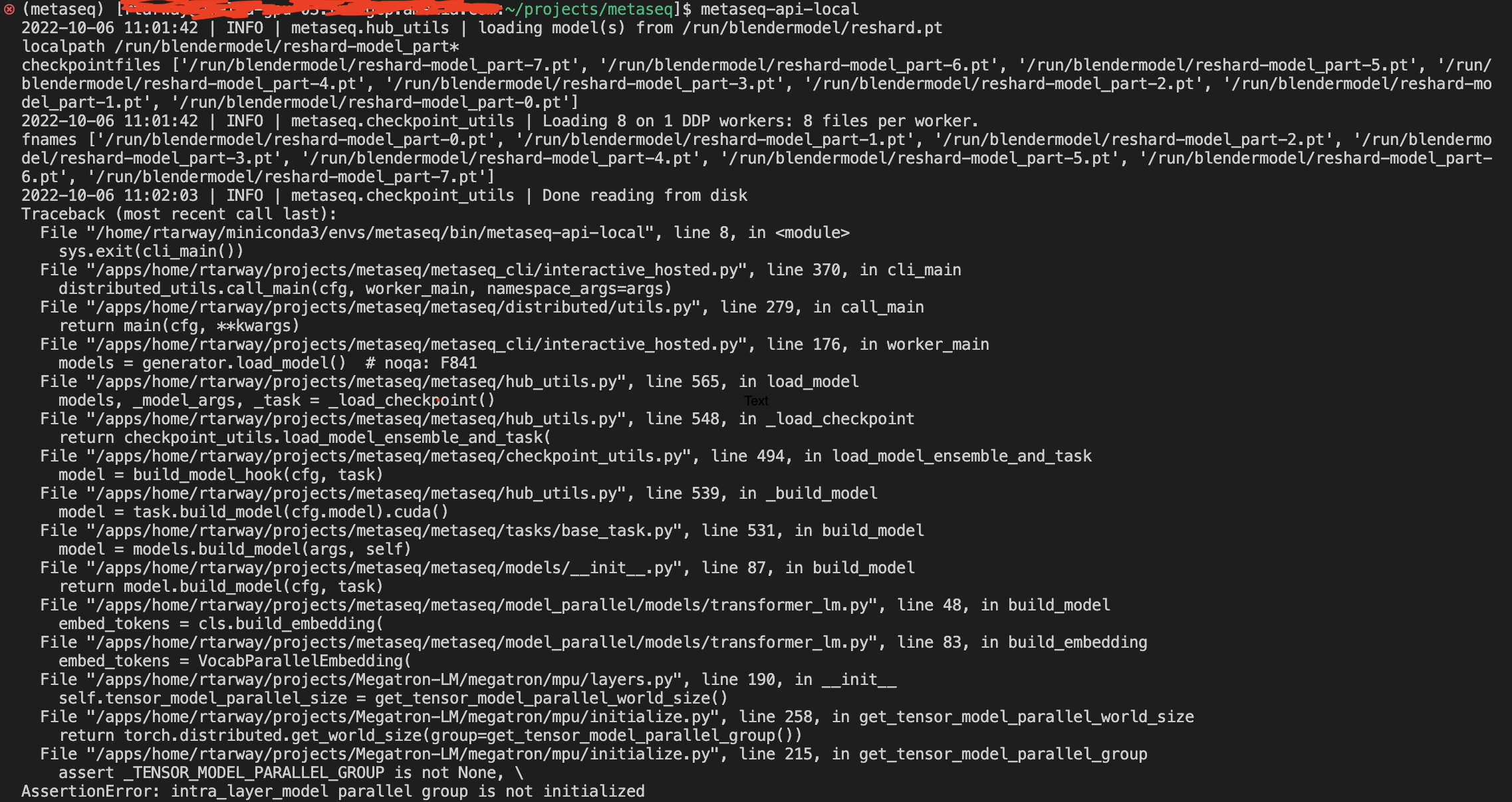
Hi @klshuster any help regarding this, I am waiting for the resolution.
@Tacacs-1101 Would you mind sharing your configs defined in constants.py? From the logs you've shared, it looks like the distributed process groups might not have been initialized properly.
sure, Here is my constant.py content:
Copyright (c) Meta Platforms, Inc. and affiliates. All Rights Reserved.
This source code is licensed under the MIT license found in the
LICENSE file in the root directory of this source tree.
import os
MAX_SEQ_LEN = 2048 BATCH_SIZE = 2048 # silly high bc we dynamically batch by MAX_BATCH_TOKENS MAX_BATCH_TOKENS = 3072 DEFAULT_PORT = 6010 MODEL_PARALLEL = 1 TOTAL_WORLD_SIZE = 1 MAX_BEAM = 16
try: # internal logic denoting where checkpoints are in meta infrastructure from metaseq_internal.constants import CHECKPOINT_FOLDER except ImportError: # CHECKPOINT_FOLDER should point to a shared drive (e.g. NFS) where the # checkpoints from S3 are stored. As an example: # CHECKPOINT_FOLDER = "/example/175B/reshard_no_os" # $ ls /example/175B/reshard_no_os # reshard-model_part-0.pt # reshard-model_part-1.pt # reshard-model_part-2.pt # reshard-model_part-3.pt # reshard-model_part-4.pt # reshard-model_part-5.pt # reshard-model_part-6.pt # reshard-model_part-7.pt CHECKPOINT_FOLDER = "/home/arahul/blenderbot3/bb3_30B/reshard"
tokenizer files
BPE_MERGES = os.path.join(CHECKPOINT_FOLDER, "gpt2-merges.txt") BPE_VOCAB = os.path.join(CHECKPOINT_FOLDER, "gpt2-vocab.json") MODEL_FILE = os.path.join(CHECKPOINT_FOLDER, "reshard-model_part-0.pt")
print("checkpoint folder ", CHECKPOINT_FOLDER)
LAUNCH_ARGS = [ f"--model-parallel-size {MODEL_PARALLEL}", f"--distributed-world-size {TOTAL_WORLD_SIZE}", "--ddp-backend pytorch_ddp", "--task language_modeling", f"--bpe-merges {BPE_MERGES}", f"--bpe-vocab {BPE_VOCAB}", "--bpe hf_byte_bpe", f"--merges-filename {BPE_MERGES}", # TODO(susanz): hack for getting interactive_hosted working on public repo f"--vocab-filename {BPE_VOCAB}", # TODO(susanz): hack for getting interactive_hosted working on public repo f"--path {MODEL_FILE}", "--beam 1 --nbest 1", "--distributed-port 13000", "--checkpoint-shard-count 1", f"--batch-size {BATCH_SIZE}", f"--buffer-size {BATCH_SIZE * MAX_SEQ_LEN}", f"--max-tokens {BATCH_SIZE * MAX_SEQ_LEN}", "/tmp", # required "data" argument. ]
I am using a single node server having single gb of 81 GB memory.
@Tacacs-1101 Can you try removing the --distributed-port option from your LAUNCH_ARGS? I suspect your distributed process groups might not have been initialized correctly due to Slurm environment variables (see #407 for some discussion).
Also, if you have 4 model parallel parts (e.g. reshard-model_part-0.pt, reshard-model_part-1.pt, reshard-model_part-2.pt, reshard-model_part-3.pt) after running the resharding script, your config should look like (notice the changes to MODEL_FILE, MODEL_PARALLEL, TOTAL_WORLD_SIZE, and LAUNCH_ARGS).
import os
MAX_SEQ_LEN = 2048
BATCH_SIZE = 2048 # silly high bc we dynamically batch by MAX_BATCH_TOKENS
MAX_BATCH_TOKENS = 3072
DEFAULT_PORT = 6010
MODEL_PARALLEL = 4
TOTAL_WORLD_SIZE = 4
MAX_BEAM = 16
# tokenizer files
CHECKPOINT_FOLDER = "/home/arahul/blenderbot3/bb3_30B/reshard"
BPE_MERGES = os.path.join(CHECKPOINT_FOLDER, "gpt2-merges.txt")
BPE_VOCAB = os.path.join(CHECKPOINT_FOLDER, "gpt2-vocab.json")
MODEL_FILE = os.path.join(CHECKPOINT_FOLDER, "reshard.pt")
LAUNCH_ARGS = [
f"--model-parallel-size {MODEL_PARALLEL}",
f"--distributed-world-size {TOTAL_WORLD_SIZE}",
"--ddp-backend pytorch_ddp",
"--task language_modeling",
f"--bpe-merges {BPE_MERGES}",
f"--bpe-vocab {BPE_VOCAB}",
"--bpe hf_byte_bpe",
f"--merges-filename {BPE_MERGES}", # TODO(susanz): hack for getting interactive_hosted working on public repo
f"--vocab-filename {BPE_VOCAB}", # TODO(susanz): hack for getting interactive_hosted working on public repo
f"--path {MODEL_FILE}",
"--beam 1 --nbest 1",
"--checkpoint-shard-count 1",
f"--batch-size {BATCH_SIZE}",
f"--buffer-size {BATCH_SIZE * MAX_SEQ_LEN}",
f"--max-tokens {BATCH_SIZE * MAX_SEQ_LEN}",
"/tmp", # required "data" argument.
]
If your model weights remain flattened after the resharding script, please try to change the --ddp-backend option to fully_sharded and append the tag --use-sharded-state, i.e. the LAUNCH_ARGS should look like:
LAUNCH_ARGS = [
f"--model-parallel-size {MODEL_PARALLEL}",
f"--distributed-world-size {TOTAL_WORLD_SIZE}",
"--ddp-backend fully_sharded",
"--use-sharded-state",
"--task language_modeling",
f"--bpe-merges {BPE_MERGES}",
f"--bpe-vocab {BPE_VOCAB}",
"--bpe hf_byte_bpe",
f"--merges-filename {BPE_MERGES}", # TODO(susanz): hack for getting interactive_hosted working on public repo
f"--vocab-filename {BPE_VOCAB}", # TODO(susanz): hack for getting interactive_hosted working on public repo
f"--path {MODEL_FILE}",
"--beam 1 --nbest 1",
"--checkpoint-shard-count 1",
f"--batch-size {BATCH_SIZE}",
f"--buffer-size {BATCH_SIZE * MAX_SEQ_LEN}",
f"--max-tokens {BATCH_SIZE * MAX_SEQ_LEN}",
"/tmp", # required "data" argument.
]
Thanks for the reply @tangbinh . I tried your suggestions but its throwing exactly the same error. These were the log info before actual error occured.
2022-11-02 16:23:15 | INFO | metaseq.hub_utils | loading model(s) from /home/arahul/blenderbot3/bb3_30B/reshard/reshard.pt 2022-11-02 16:23:15 | INFO | torch.distributed.distributed_c10d | Added key: store_based_barrier_key:2 to store for rank: 0 2022-11-02 16:23:15 | INFO | torch.distributed.distributed_c10d | Rank 0: Completed store-based barrier for key:store_based_barrier_key:2 with 1 nodes. 2022-11-02 16:23:34 | INFO | metaseq.checkpoint_utils | Done reading from disk
Also i want to mention that I have a single gpu server with 81GB of RAM. so i am keeping MODEL_PARALLEL=1 & TOTAL_WORLD_SIZE=1
@Tacacs-1101 Indeed, the resharded checkpoints would not work with 1 GPU because the model parallel parts require at least 4 GPUs to start the distributed process groups (the config suggestions above might still be relevant, though).
If you only have one GPU, then you would need to merge all model parallel parts into a singleton checkpoint. The script consolidate_fsdp_shards.py might be helpful here. Note that the singleton checkpoint might not fit into your single GPU (that's why we often keep model parallel parts).
It's been a while without any update, so I'm closing the issue now. Please let us know if you need further help.