Question about replicating bert ranker
Hi, Currently, I try to pretrain bert-ranker-model of blenderbot 2.0 using to convai2(personachat dataset, version both_original ) which is the purpose of replicating the results.
- My script
!python -m parlai.scripts.train_model -t convai2:both -m bert_ranker/bi_encoder_ranker --batchsize 20 -vtim 30 \
--init-model zoo:bert/model \
--model-file content/drive/MyDrive/bi_encoder --data-parallel True
- Q1 Train_accuary is weird. The link said that it accuracy is 0.8686, but I am getting strange output as 0.06167. Can I simply train more? I'm not sure what mistake I made. Could you please help?
06:57:42 | time:3765s total_exs:34820 total_steps:1741 epochs:0.26
clen : 136, clip : 1, ctpb : 2751, ctps : 7214, ctrunc : .008333
ctrunclen : .4633, exps : 52.44, exs : 600, gnorm : 47.02, gpu_mem : .6626
llen : 14.08, lr : 5e-05, ltpb : 281.6, ltps : 738.5, ltrunc : 0, ltrunclen : 0
mean_loss : 3.738, mrr : .1876, rank : 10.45, total_train_updates : 1741
train_accuracy : .06167, tpb : 3033, tps : 7952, ups : 2.623
-
Q2 In order to make bb2's bi-encoder, is it only necessary to fine-tune the base bert with convai2:normalized? And is the script code I wrote for doing that right?
-
Q3 Would the result be much different if I use convai2 both version instead of self version? I saw #4581 and found out which version of bb2-ranker-bert was used in this issue.
Thank you for your kindly reply.
Q1: You've specified the incorrect --init-model --> try doing the following:
--init-model zoo:pretrained_transformers/bi_model_huge_reddit/model -m transformer/ranker
q2: I'm not sure I fully understand - BB2 is a generative model, and does not employ BERT
q3: It's up to you - both may yield slightly better results but we generally use self (as it more accurately reflects real applications)
Thank you for your kindle answer. I fully understood Q1 and Q3.
I'm not familiar with English, so the question was not accurate.
Question 2 means that please review whether the dataset required to pretrain the bert marked with the orange box is convai2 or reddit & convai2.
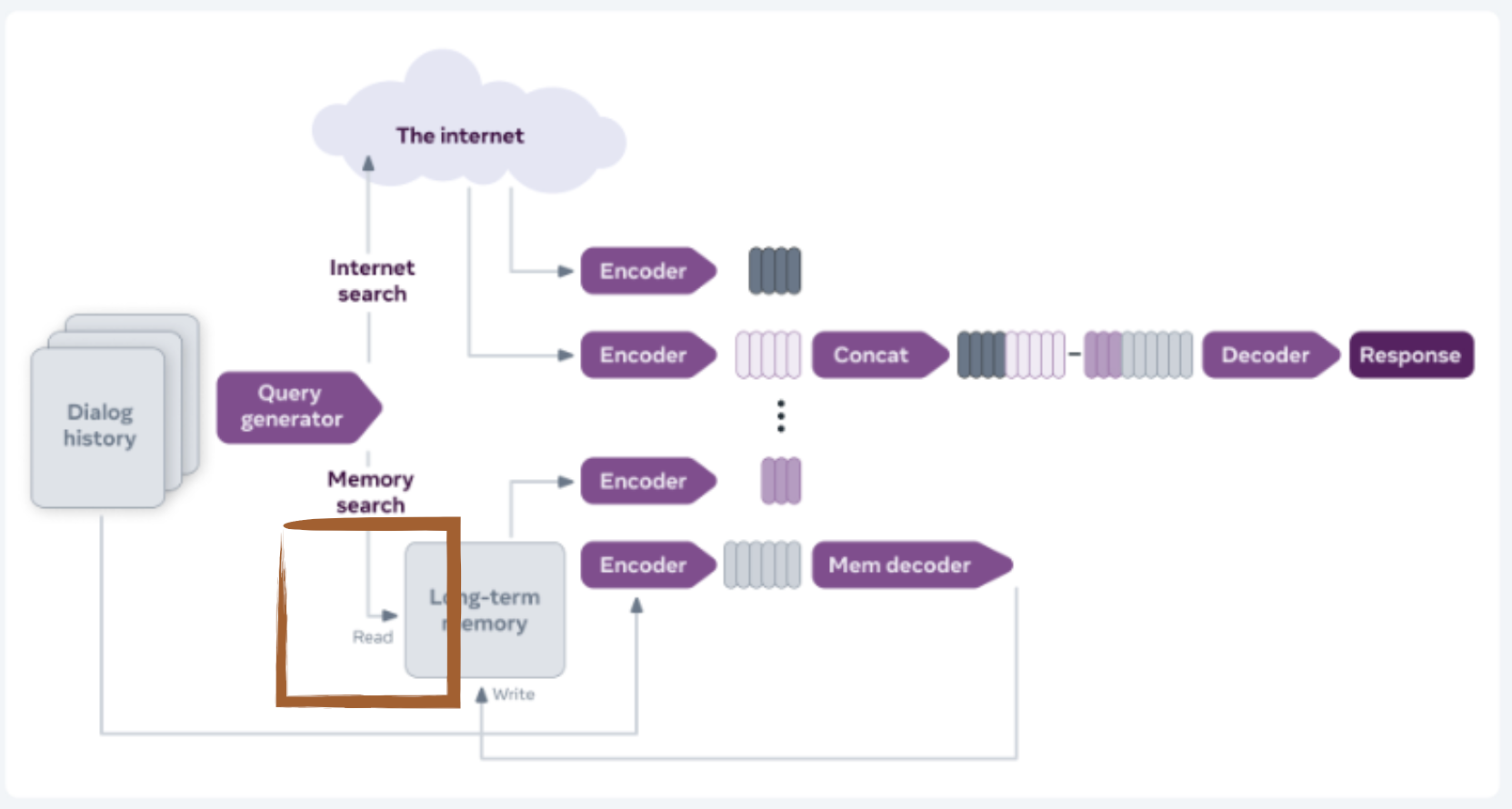
We use a DPR model that is pre-trained on a suite of knowledge-intensive QA tasks, and is fine-tuned in a RAG setup on wizard of wikipedia. so, no reddit training involved
Um,, Am I understanding correctly?
-
Blenderbot2
- Ready
No component pre-training model dataset 1 query generator O BART Wizard_of_Internet(wizlnt) 2 Long Term memory reader O bert Wizard_of_Wikipedia(WoW) 3 Long Term memory writer X bert X 4 Long Term memory decoder X gpt2 X - fine-tuning : Blenderbot2(MSC, Wizlnt, safety(BAD)
-
Blenderbot1
- Ready
No component pre-training model dataset 1 Poly-Encoder O transformers encoder Reddit(~2017.09, comment) - fine-tuning : Blenderbot1(BST,WoW,convai2:normalized,empathetic_dialogues)
I read almost all the issues, and there were a lot of questions asking about the bb2 component, structure, required dataset, and script command. I want to help you. I made the table about bb2 and bb1 so you get less questions like this. I hope I understand correctly and this table is helpful for those new to blenderbot. Thank you so much for always providing good papers and open sources.
sincerely Thank you!
BlenderBot 1 is an encoder-decoder transformer, not a poly-encoder
BlenderBot 2's long term memory decoder is also BART and was trained on MSC. everything else looks to be correct
I made a terrible mistake.
- Blenderbot2
| No | component | pre-training | model | dataset |
|---|---|---|---|---|
| 1 | query generator | O | BART | Wizard_of_Internet(wizlnt) |
| 2 | Long Term memory reader | O | bert | Wizard_of_Wikipedia(WoW) |
| 3 | Long Term memory writer | X | bert | X |
| 4 | Long Term memory decoder | X | bart | X |
- Blenderbot1
| No | component | pre-training | model | dataset |
|---|---|---|---|---|
| 1 | Poly-Encoder, bart(decoder) | O | customized transformers | Reddit(~2017.09, comment) |
Now I have some understanding of this project. Every time I see you, I feel great. Thank you so much..!!
BlenderBot 1 does not use BART, it uses a different architecture with a different pre-training objective; the original paper outlines in depth what these are. it's simply a transformer seq2seq model
BlenderBot 1 does not use BART, it uses a different architecture with a different pre-training objective; the original paper outlines in depth what these are. it's simply a transformer seq2seq model
With this structure, I understood, and I wanted to talk about this structure. Maybe I misunderstood?
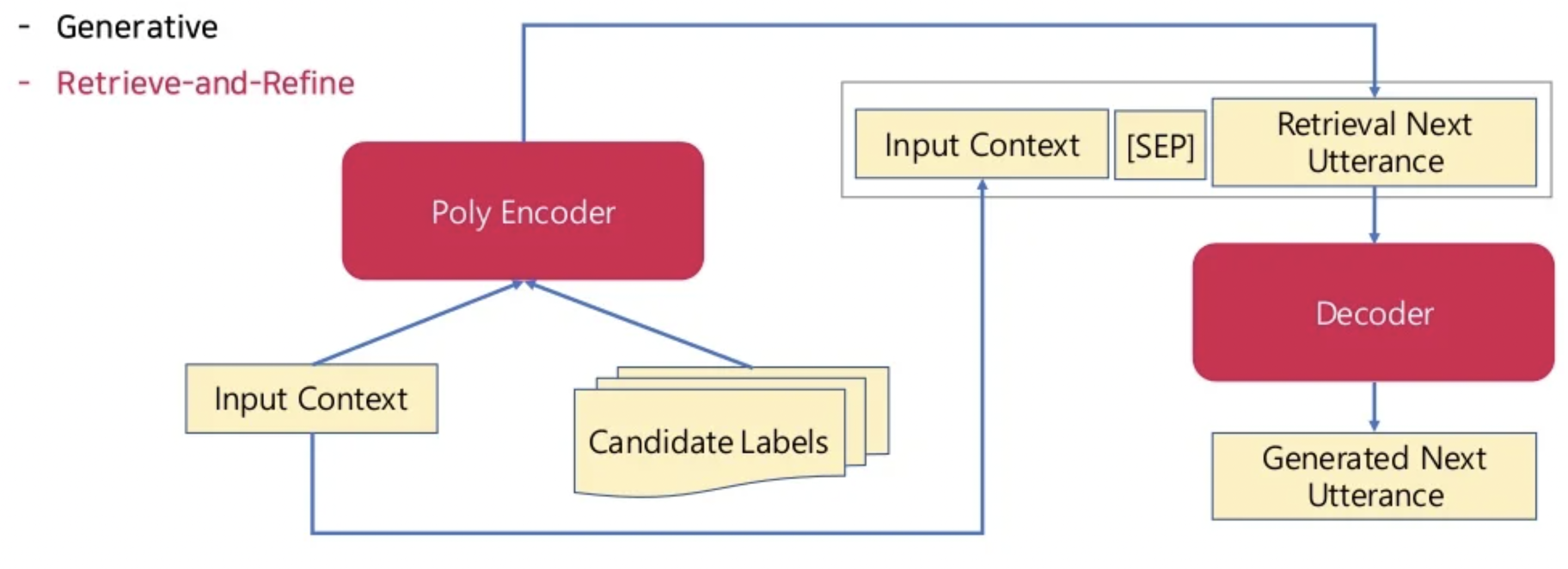
That is the retrieve and refine architecture; blenderbot 1 is a purely generative model, however we considered retrieve and refine in the original tech report as an alternative
-
Q1 Isn't
Reddit_3B a pre-trained modelwith reddit data as apoly-encoder? -
Q2
 This picture is Blenderbot1 fine-tuning script command when fine-tuning Reddit_3B/models are included.
Because I thought bb1 was a
This picture is Blenderbot1 fine-tuning script command when fine-tuning Reddit_3B/models are included.
Because I thought bb1 was a polyencoder+transformerbecause the reddit model was included in the fine-tuning. By the way, I am very confused because you said that it is a purely generavtive model. Sorry for the inconvenience, but please mercy on me.
bb1 was pre-trained on reddit as well, as a generative language model
Thank you for your reply seriously.