zstd
 zstd copied to clipboard
zstd copied to clipboard
Adaptive compression often wrongly locks at high compression levels
Describe the bug In my experience, adaptive compression sometimes increases compression level throughout low entropy data and afterwards fails to decrease it even though CPU becomes the bottleneck. I've aborted the compression after it lasted for a minute or two, so I don't think if it'd eventually manage to reduce it.
To Reproduce Most recently, I've reproduced while making a backup to a slower HDD, so...
Steps to reproduce the behavior:
tar -c / | zstd -v --adapt -T12 > /mnt/backup/foo.tar.zstd
Expected behavior I expected the compression level to be adapted to achieve best throughput with CPU utilization close to 100%.
Screenshots and charts
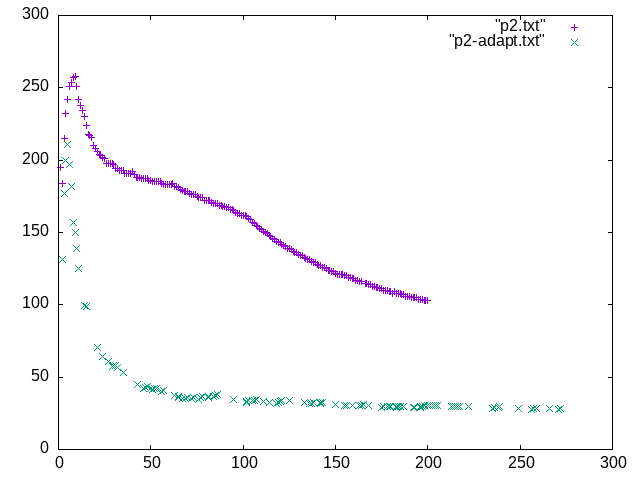
This is a very rough benchmark of input rate vs time. p2.txt is constant compression level that keeps CPU utilization low, so it's entirely I/O bound. p2-adapt.txt is adaptive compression. There's a visible peak due to I/O caching but still, it's quite clearly visible that adaptive compression is doing very badly here.
Desktop (please complete the following information):
- OS: Gentoo Linux
- Version: (not versioned)
- Compiler: gcc 9.3.0
- Flags:
-march=znver2 --param l1-cache-size=32 --param l1-cache-line-size=64 -O2 -pipe - Other relevant hardware specs: Ryzen 5 3600 (6 cores, 12 threads)
- Build system: Makefile
Additional context Maybe it'd be better to make adaptation work based on perceived CPU utilization rather than I/O conditions? I think that'd yield more stable results and avoid instability caused by buffering. I don't know what other use cases are for adaptive compression but in my case, the primary goal would be to achieve realtime compression, and only secondary to achieve strongest compression possible while at it.