`is_first_token` and `is_last_token` pattern in matcher
This PR adds is_first_token and is_last_token pattern to matcher.
Description
Abstract
This pull request implements is_first_token and is_last_token token pattern which matches the first or last token of the Doc presented to matcher.
The patterns are inspired by the regex anchors ^ and $ which match the beginning of the text and the end of the text respectively.
This pull request is spaCy's equivalent of the regex anchors in the form of the first or last token in the input Doc. This is achieved through retaining the information of the index of the tokens relative to the input Doc in the find_matches() function in matcher.pyx when it loops through each Token within Doc.
Rationale
Anchors
spaCy currently have is_sent_start as a type of anchor for start of sentences, however, it lacks an anchor for the start and end of a Doc or Span inputted into matcher.
Firstly, the value of the anchor would grant users the ability to specify the location of the match at the beginning or the end of the input Doc and not anywhere else.
Secondly, it is efficient for matcher since by specifying the location of the matches, lesser matches would be processed and thus take up lesser time.
Design Choice
is_first_token and is_last_token patterns are implemented as patterns in matcher and not an attribute in a Token.
Since the position of the token is relative to the input, the first token of a Span might be different from the original Doc.
doc = nlp("This is a sentence. This is another sentence.")
span = doc[2:6] # "a sentence. This is"
In the above example, the first token for the span is "a". However, it would be difficult to modify the token attributes every time a span is created.
Instead of modifying the token attributes and retrieving them from the get_token_attr_for_matcher(), is_first_token and is_last_token are processed within get_is_match().

Testing
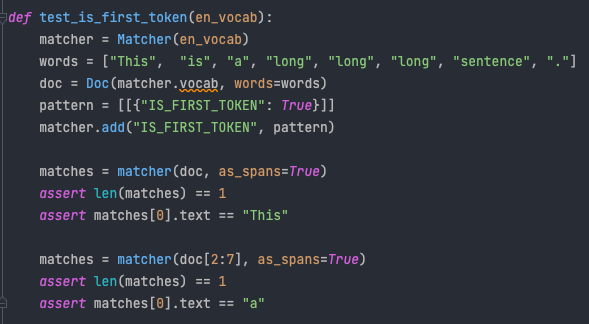
Types of change
Matcher enhancement and new feature
Checklist
- [x] I confirm that I have the right to submit this contribution under the project's MIT license.
- [x] I ran the tests, and all new and existing tests passed.
- [x] My changes don't require a change to the documentation, or if they do, I've added all required information.
Thanks for the PR, we'll take a look! Just as a note, it may take a bit longer than usual due to vacation plans on our end, but it's on our to-do list for sure.
Thanks again for the PR! It's unfortunate that this requires so much machinery for such a simple idea (I wish it could be done without new attributes and symbols), but this does look like a simple way to implement it and it doesn't look like the speed is a concern.
I think there is a general question about whether we want to include token features in the Matcher that aren't intrinsic features of the token itself.
Hi @shen-qin, we really appreciate the time and effort you've put into this PR, but I'm afraid we won't be merging it as such. After some internal discussion, we've come to the conclusion that these kind of properties are outside the scope of the matcher, as they're not inherent Token properties, but rather properties defined on the Doc/Span level.
To address your use-case, a workaround with custom attributes should be relatively easy to implement - you can match on those as well. We hope that works for you!