argopy
 argopy copied to clipboard
argopy copied to clipboard
Trouble fetching large amount of data by region
Hello, I seem to run into trouble when attempting to fetch a large amount of data by region. It appears that I am unable to fetch all the data (some appears to be missing).
MCVE Code Sample
from argopy import DataFetcher as ArgoDataFetcher
ArgoSet1 = ArgoDataFetcher(cache=True, parallel=True, progress=True).region([-175, -160, -45, -35,0,10000])
ds1 = ArgoSet1.to_xarray()
print(np.min(ds1.PRES))
#### Expected Output
I would expect np.min(ds1.PRES) to be very close to zero, however, I get 999.5
#### Problem Description
It appears that not all of the expected data is being fetched.
#### Versions
<details><summary>Output of `argopy.show_versions()`</summary>
<!-- Paste the output here argopy.show_versions() here -->
SYSTEM
------
commit: None
python: 3.9.12 (main, Apr 5 2022, 01:53:17)
[Clang 12.0.0 ]
python-bits: 64
OS: Darwin
OS-release: 20.4.0
machine: x86_64
processor: i386
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
LOCALE: None.UTF-8
libhdf5: 1.10.6
libnetcdf: 4.6.1
INSTALLED VERSIONS: MIN
-----------------------
aiohttp : 3.8.1
argopy : 0.1.12
erddapy : 1.2.1
fsspec : 2022.02.0
netCDF4 : 1.5.7
packaging : 21.3
scipy : 1.7.3
sklearn : 1.0.2
toolz : 0.11.2
xarray : 0.20.1
INSTALLED VERSIONS: EXT.EXTRA
-----------------------------
dask : 2022.02.1
distributed : 2022.2.1
gsw : 3.4.0
pyarrow : -
tqdm : 4.64.0
INSTALLED VERSIONS: EXT.PLOTTERS
--------------------------------
IPython : 8.2.0
cartopy : -
ipykernel : 6.9.1
ipywidgets : 7.6.5
matplotlib : 3.5.1
seaborn : 0.11.2
INSTALLED VERSIONS: DEV
-----------------------
bottleneck : 1.3.4
cfgrib : -
cftime : 1.6.1
conda : 4.13.0
nc_time_axis: -
numpy : 1.21.5
pandas : 1.4.2
pip : 21.2.4
pytest : 7.1.1
setuptools : 61.2.0
sphinx : 4.4.0
zarr : -
</details>
Hi @wjoyce2 This happens because the default chunking of your selection is still too large for the server. Thus, you should simply reduce the size of the chunks. This will increase the number of requests, but reduce their size, and argopy should be able to go through, see here for more: https://argopy.readthedocs.io/en/latest/performances.html#size-of-chunks
Also, if you just need the 'standard' user mode, always good to shift to the argovis data source for large requests
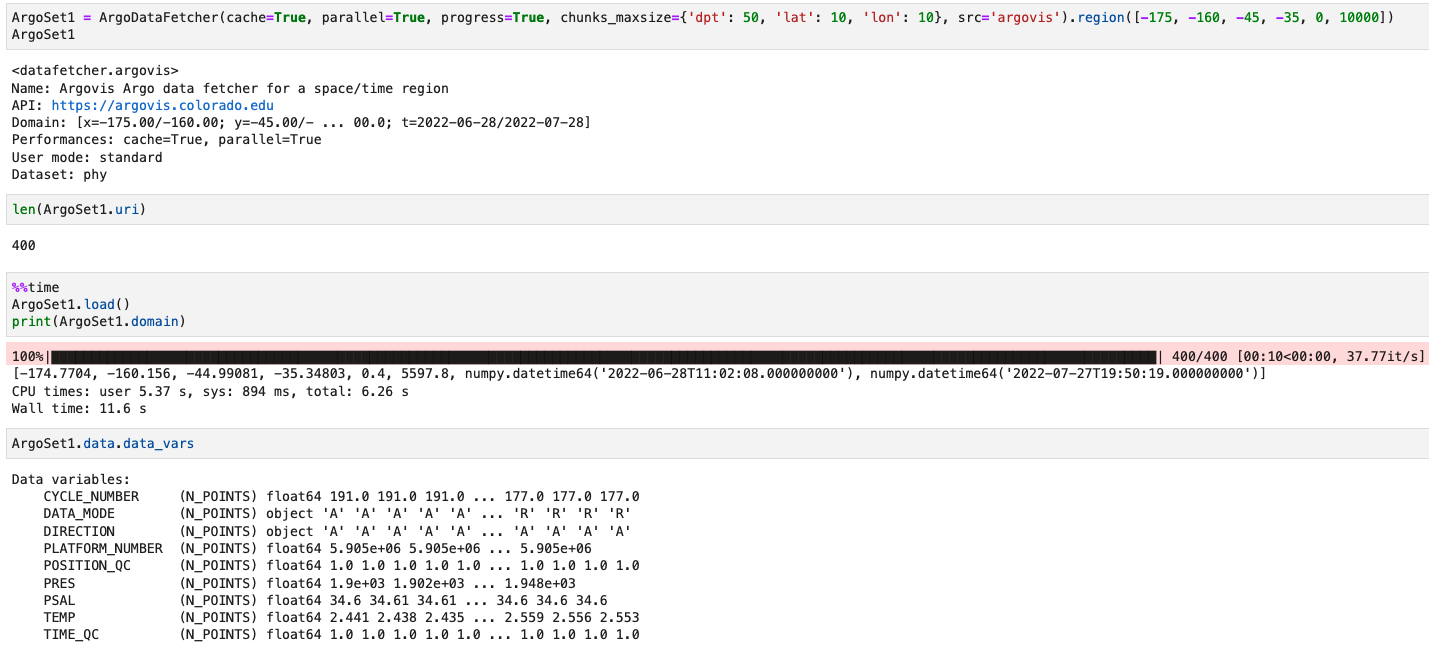
ArgoSet1 = ArgoDataFetcher(cache=True,
parallel=True,
progress=True,
chunks_maxsize={'dpt': 50, 'lat': 10, 'lon': 10},
src='argovis').region([-175, -160, -45, -35, 0, 10000])
It went through with my laptop in 12 secs:
Hi @gmaze,
Thank you so much for your help. It is greatly appreciated.
I tried reducing the chunk size previously, but ran into trouble.
The code you suggested, however, appears to have worked properly. (I did not change the source because I plan to use the 'expert' mode in the future)
ArgoSet2 = ArgoDataFetcher(cache=True, parallel=True, progress=True,chunks_maxsize={'dpt': 50, 'lat': 10, 'lon': 10}).region([-175, -160, -45, -35, 0, 10000])
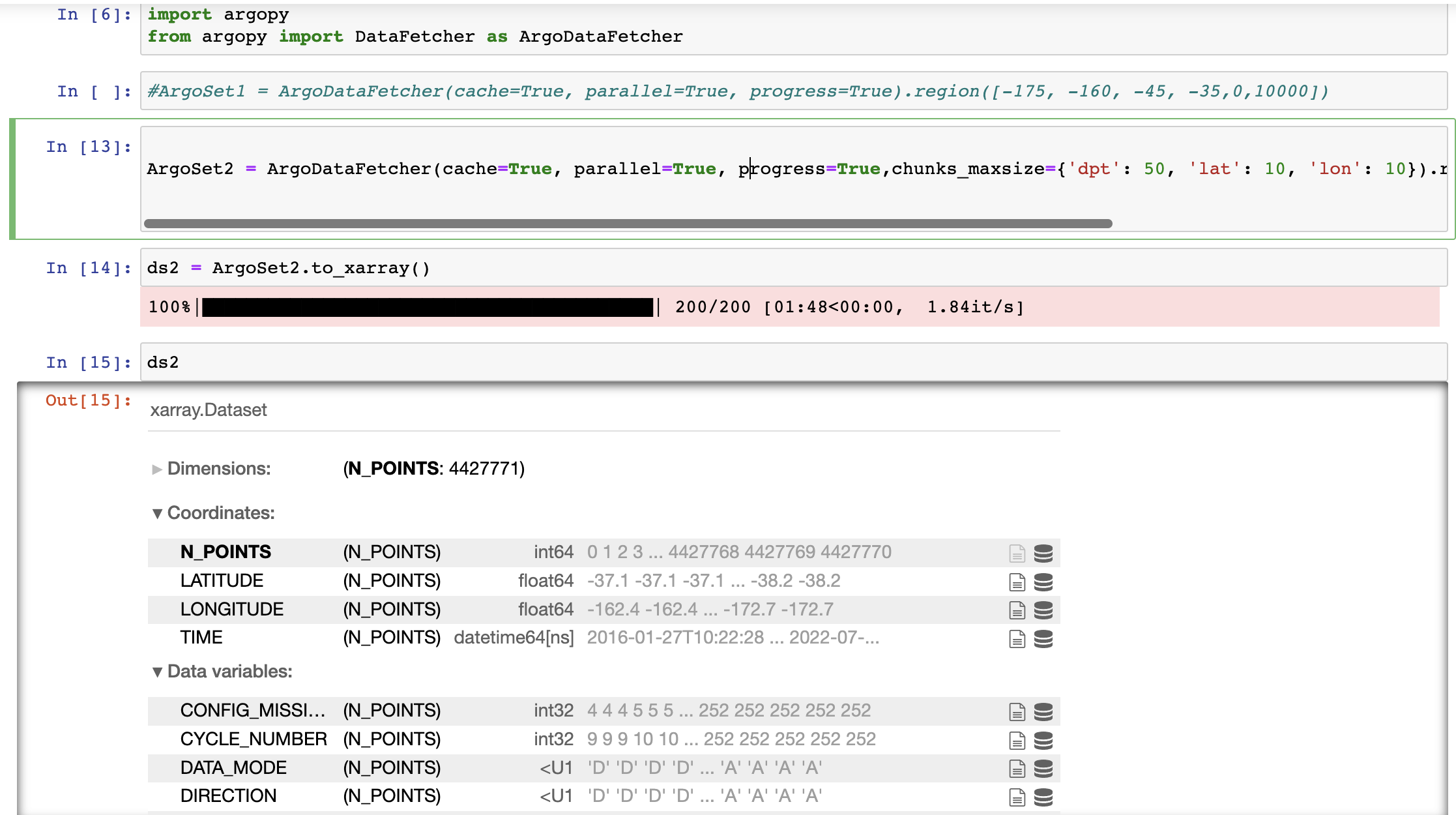
I am wondering, is there a way to check that the fetched data is complete? Or a way of knowing if the chunks are too large?
Thank you again.
I am wondering, is there a way to check that the fetched data is complete? Or a way of knowing if the chunks are too large?
Unfortunately, there is no methods for neither of these ...