architecture is different from the model in paper (up sampling stage and fusion module)
Hi Yisheng,

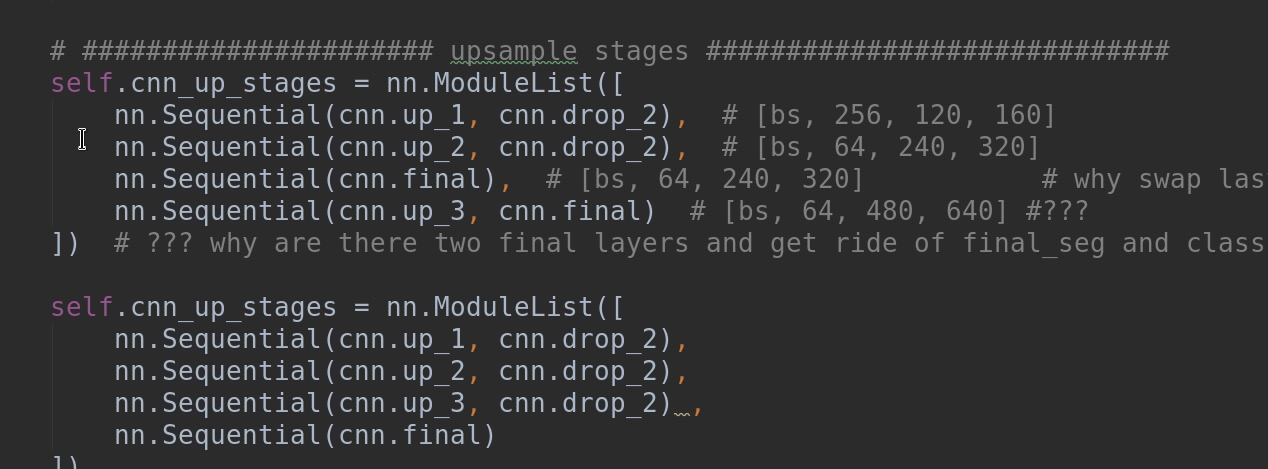
The network 's up sampling stage is not correct. The 3rd layer of up sampling and the conv2d afterwards are swapped, i.e., the 3rd layer of up sampling should be PSP_UP however, however it is just Conv2d.
It is a typo or you did it on purpose due to practical consideration?
It's a typo and I tried fixing it and re-trained one of the models on LineMOD, finding that the performance is close. Considering the cost of re-training all pre-trained models, I decided to keep it as it is.
It's a typo and I tried fixing it and re-trained one of the models on LineMOD, finding that the performance is close. Considering the cost of re-training all pre-trained models, I decided to keep it as it is.
Thank you for your reply!
I think the upsampling stages should be the 2nd version according to the paper, right? It is strange that you used two final layer before.
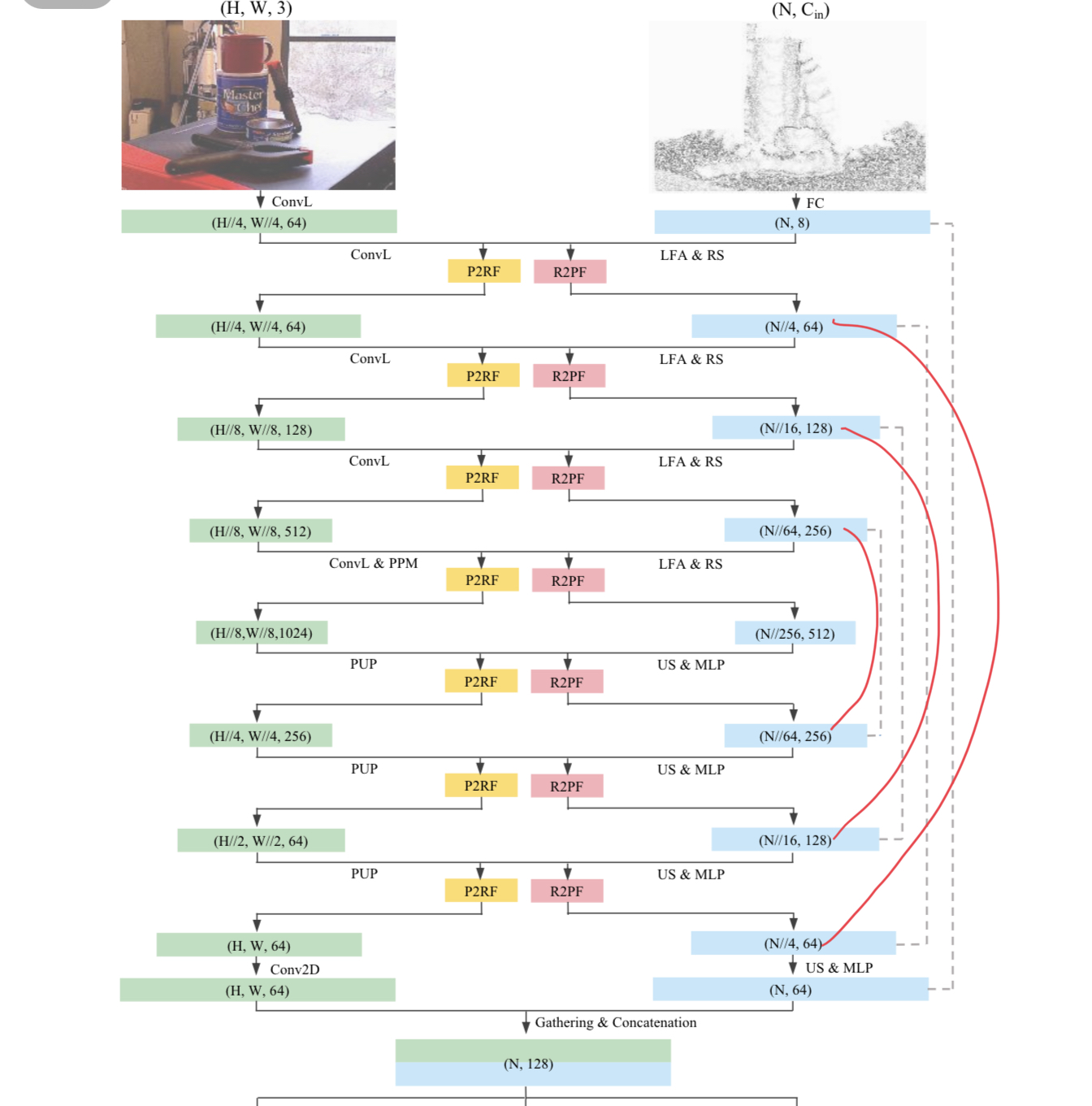
I am also confused about the size of the output tensor and fusion operation. In the point cloud flow, the number of point of down sampling and up sampling is symmetric, however for rgb flow, it is not symmetric.
You also use random sampling for rgb feature map to align the shape of rgb feature and point cloud feature before concatenation fusion. Could you tell me how you maintain the correspondence of rgb feature and point cloud feature during this process?
I tried to have a look at the shape of last layer of encoder and feel confused about random sampling of rgb feature map:
The nearest interpolation of point cloud feature tries to increase the number of points from 50 to 4800, which is 96 times later than original number. How to maintain the accuracy here?

I think the upsampling stages should be the 2nd version according to the paper, right? It is strange that you used two final layer before.
Yes, but the performance difference is small.
In the point cloud flow, the number of point of down sampling and up sampling is symmetric, however for rgb flow, it is not symmetric.
The framework of CNN and PCN is kept the same as their original version. Note that the main idea is to do full flow directional fusion on each encoding and decoding module, not limited to these tow frameworks. Apart from the example CNN and PCN frameworks, other frameworks also work.
The nearest interpolation of point cloud feature tries to increase the number of points from 50 to 4800, which is 96 times later than original number. How to maintain the accuracy here
The key is to keep the XYZ map aligned with the RGB feature map and find the relation between the XYZ map and point cloud, for which the KNN is enough. You can refer to our paper for some explanation, on page 4.
Thank you for your reply!
The framework of CNN and PCN is kept the same as their original version. Note that the main idea is to do full flow directional fusion on each encoding and decoding module, not limited to these tow frameworks. Apart from the example CNN and PCN frameworks, other frameworks also work.
I noticed that you extract layers from PSPnet and RandLaNet and get ride of some layers e.g. average pooling, fc layer of cnn.feats instead of using them directly. Did you try other networks as well or it is your assumption?
I am sorry to ask this question again in the screenshot. Could you tell me how you aligned rgb and point feature map during random sampling of rgb feature map? You random sampled rgb feature and point cloud feature separately but align the shape and concatenate them together. It seems that you only align the shape before concatenation but did not consider the correspondence.
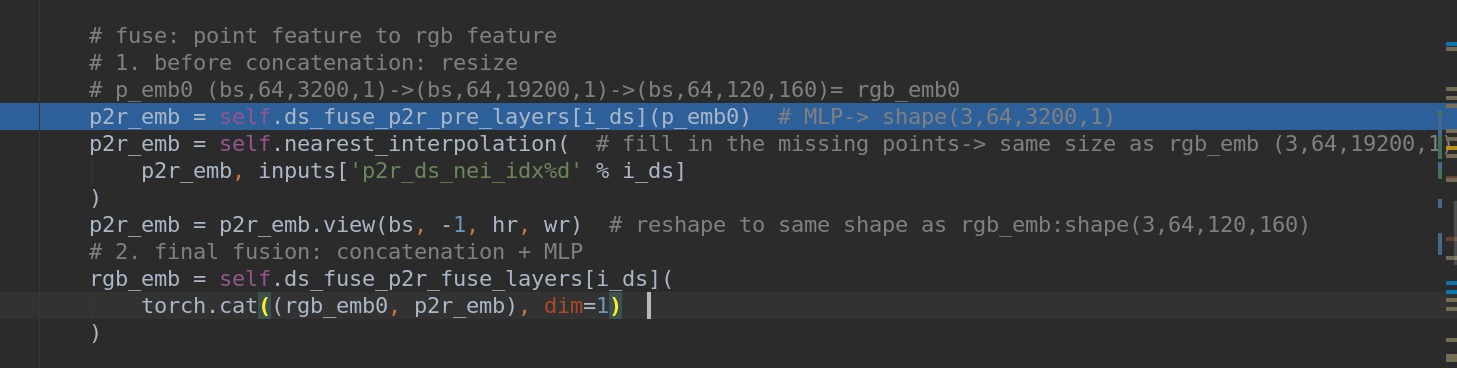
In the paper, you described that you resize XYZ map but you actually resize the p2r feature map.
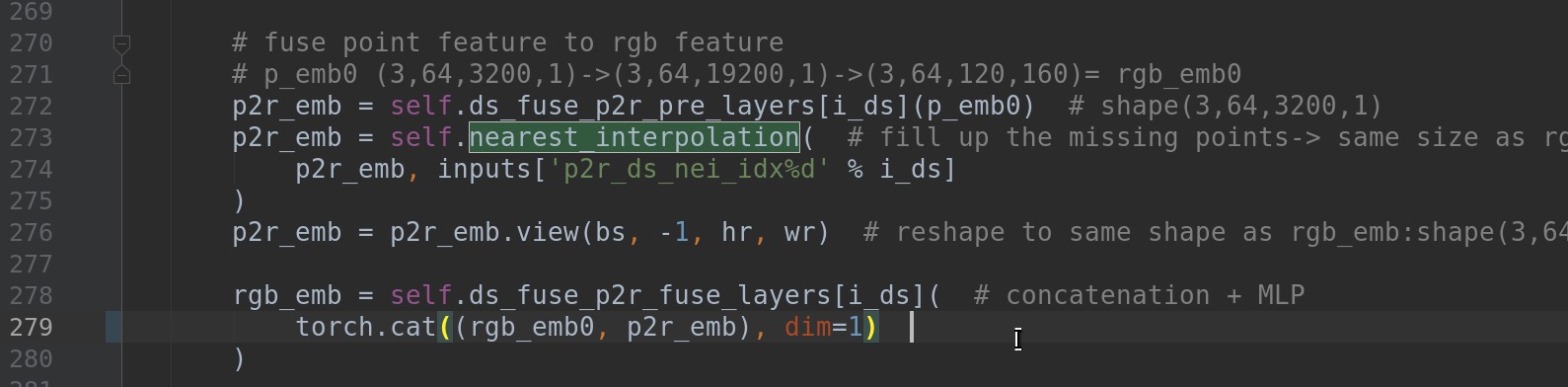
You did not mention the random sampling (from RandLaNet) for rgb embedding in the paper.
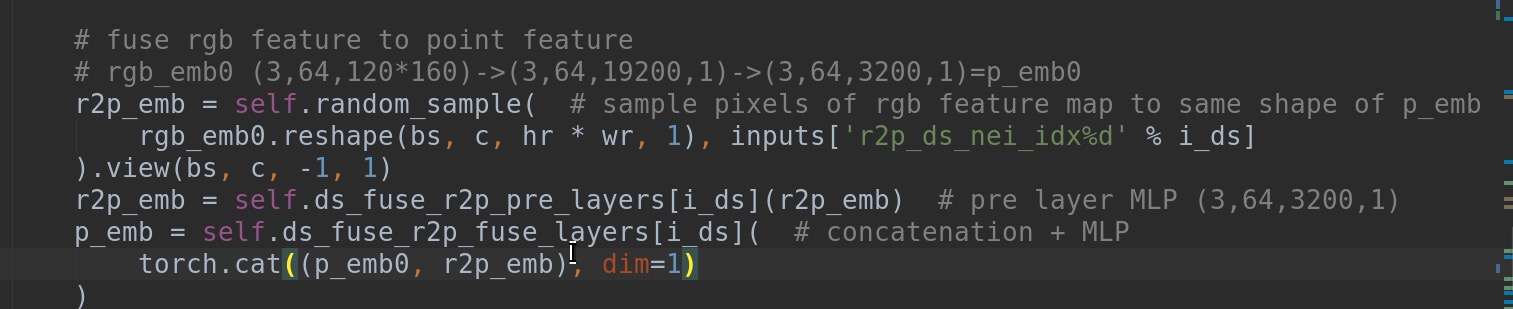
I did not find XYZ map in the ffb6d model class actually. I can only find XYZ map in ycb_dataset py file (without resizing and alignment with rgb feature map)
Feel free to correct me if I misunderstood something.
Best wishes, Min
Hi Yisheng,
There is no KNN feature gathering in fusion module from point to rgb.
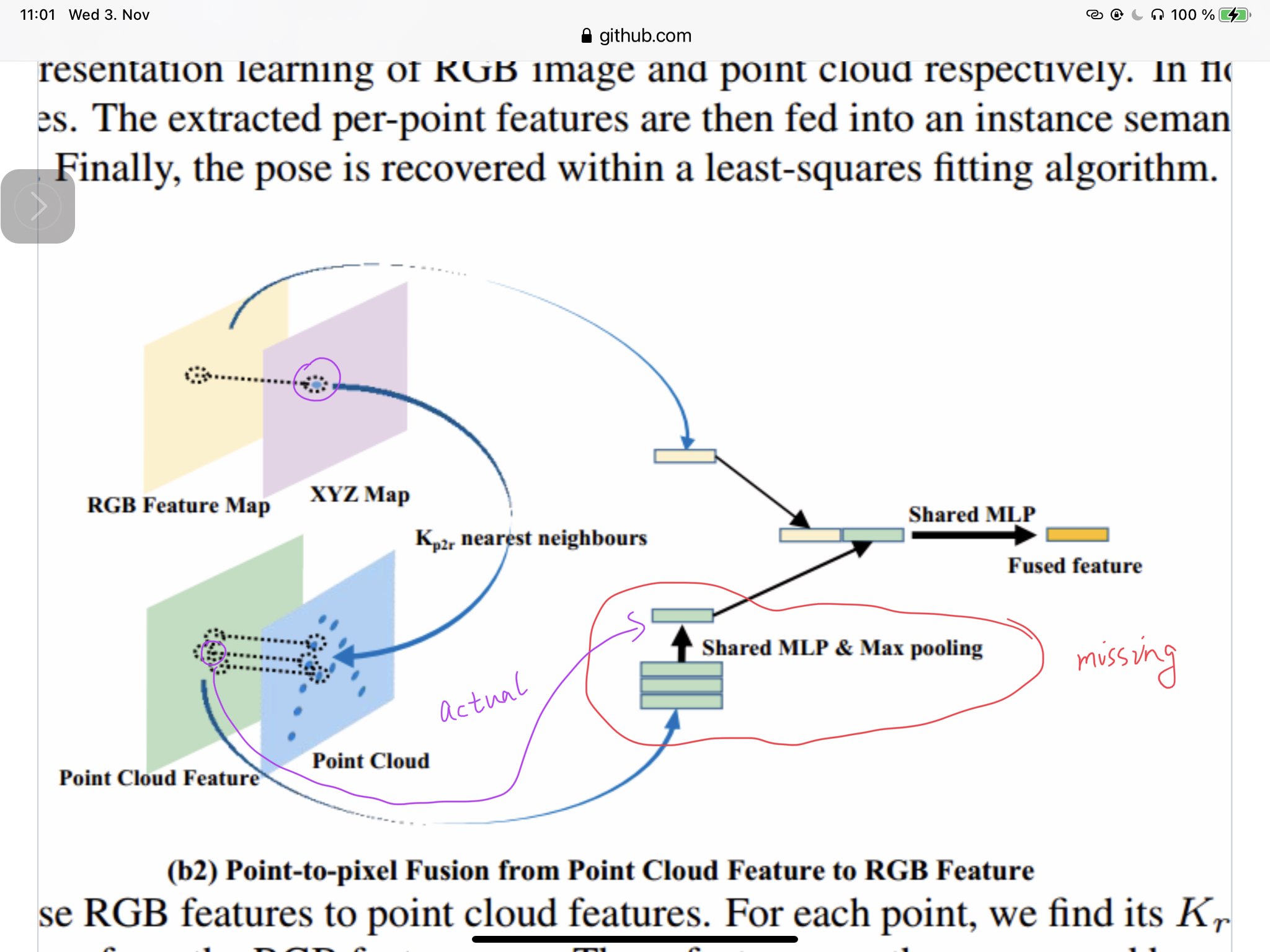
- In Table 7 of our paper we can see full flow bidirectional fusion is also beneficial to other frameworks. We also tried CNN with PointNet++ and it also works. It's reasonable to infer that other CNN and PCN architecture also works.
- As illustrated in our paper, the same size (H, W) of XYZ map is aligned with the same size of feature maps, we preprocess the XYZ map and establish the KNN correspondence (inputs['p2r_ds_nei_idx*']) between the XYZ map and point cloud in the data processing scripts as you mentioned. The random sampling function in fact is selecting the KNN feature from RGB to pcn. The function name may be miss leading and I may modify it when I have more time.
- We neglect the KNN from pcld to RGB in this version because it costs too much memory and the performance gain from it is relatively small. We need a 24G GPU to train that full model with a smaller batch size. While the current version is more friendly to common GPU with 8 GB memory.
Hi Yisheng, Thank you for your reply !
The framework of CNN and PCN is kept the same as their original version. Note that the main idea is to do full flow directional fusion on each encoding and decoding module, not limited to these tow frameworks. Apart from the example CNN and PCN frameworks, other frameworks also work.
- It's reasonable to infer that other CNN and PCN architecture also works.
Do you mean , regardless the architecture of network for RGB and network for depth (point cloud) and their output shapes of each layer, we can simply resize the feature maps of two modalities and concatenate them?
In the section 3.2 of your paper, you mentioned resizing XYZ map as follows (which is different from the codes): we need to maintain a corresponding XYZ map so that each pixel of feature can find its 3D coordinate. Instead, a better solution is to resize the XYZ map to the same size as the feature map within the nearest interpolation algorithm.
- the same size (H, W) of XYZ map is aligned with the same size of feature maps, we preprocess the XYZ map and establish the KNN correspondence
I guess you mean align XYZ map with original RGB image, instead of feature maps, since the feature maps (output of each layer of CNN) have different sizes, and you didn’t resize XYZ map.
The key is to keep the XYZ map aligned with the RGB feature map and find the relation between the XYZ map and point cloud, for which the KNN is enough. That is where I feel confused. It seems that you convert depth image to XYZ map and then point cloud and keep the correspondence between XYZ and point cloud during data preprocessing. You did not resize XYZ map.
- random sampling function in fact is selecting the KNN feature from RGB to pcn. The function name may be miss leading and I may modify it when I have more time.
Yes, I noticed that the random sampling and nearest interpolation method are from RndLaNet pytorch version. They use random sampling for downsampling the points and nearest interpolation for up sampling.
In you fusion module, you use the same random sampling for gathering KNN feature and max pooling as this figure:
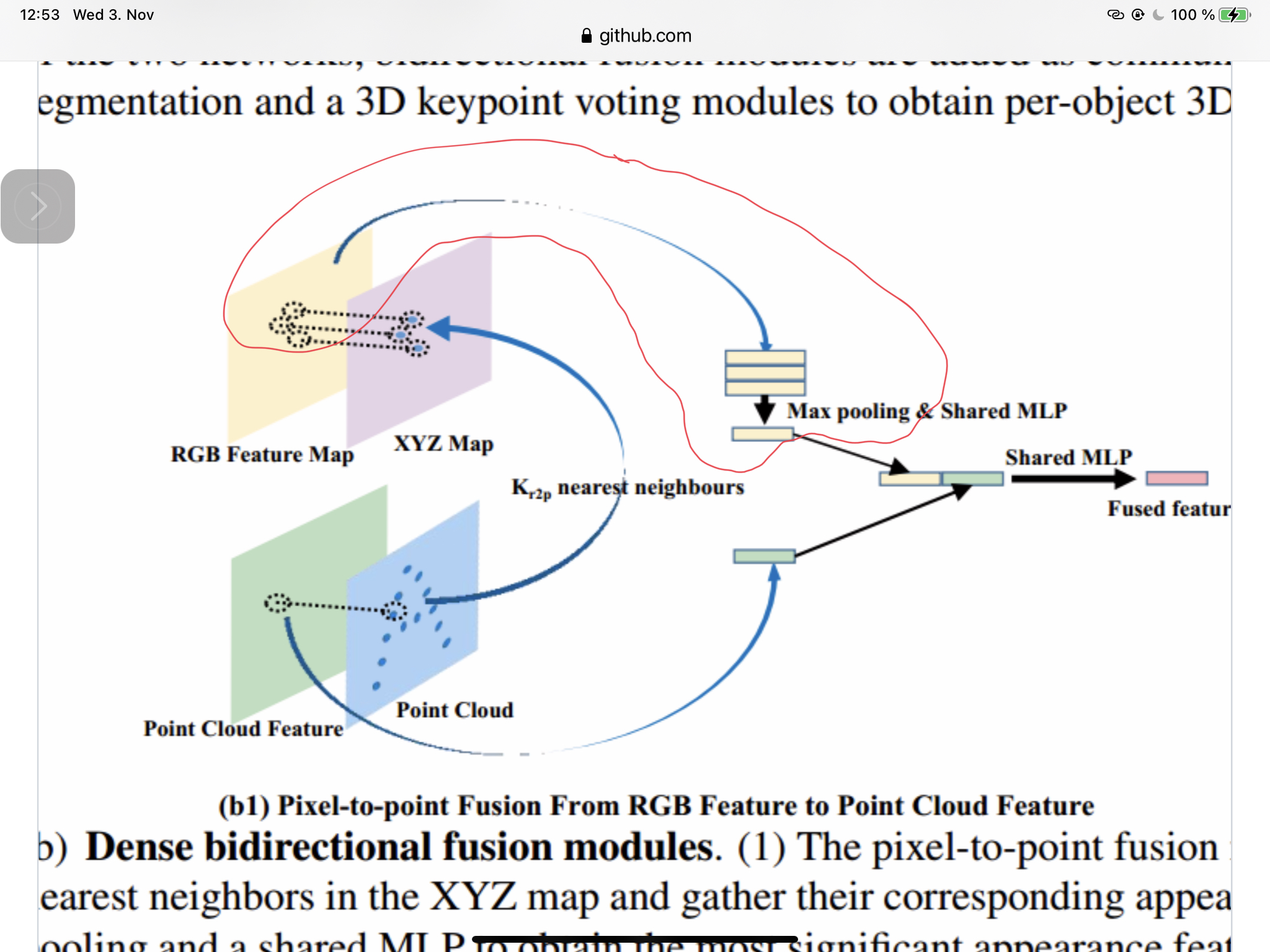
You also use the same nearest interpolation method to up sample the point cloud feature to match the size of rgb feature.
Therefore these two functions’ name is misunderstanding.
- We neglect the KNN from pcld to RGB in this version because it costs too much memory and the performance gain from it is relatively small. We need a 24G GPU to train that full model with a smaller batch size. While the current version is more friendly to common GPU with 8 GB memory.
Do you mean your version aligned with the paper is your internal version and you make some changes for open source version? Did you try to reduce the KNN neighbors from 16 to other number?
- not simply concatenation, but utilize similar architecture as our point to RGB and RGB to point fusion.
- The XYZ map part is the same as described in our paper. We resize the XYZ map to different resolutions (the resolution that the feature map will encounter during encoding & decoding) to establish the correspondence in the data preprocessing part link
- They name random sampling because their index is randomly sampled, while our index is obtained from knn correspondence. The upsampling module also serves as the KNN correspondence feature gathering function here.
- KNN = 1 is the best trade-off.
Thank you for your patience!
- The upsampling module also serves as the KNN correspondence feature gathering function here.
It is like gathering neighbors feature to make the size of point feature the same as rgb feature.(still upsampling) I think it is not the same as KNN feature gathering and max pooling (equation 3) in the paper.
- They name random sampling because their index is randomly sampled
The random sampling inside rgb to point fusion is like finding sampled points ‘s neighbors +max pooling