lmql
 lmql copied to clipboard
lmql copied to clipboard
HF Llama Indexing Issue
I'm currently trying to use the huggingface LlamaForCausalLM. I downloaded the weights, and hosting / inference work great.
The only issue is that there is some tokenization issue going on.
My .lmql file looks like this:
argmax """Once upon a time[GENERATION]""" from "llama/hf_llama7b" where len(GENERATION) < 40
However, my output is a bit messed up:

I think the issue has to do with the llama tokenizer always prepending the <s> token (beginning of string) to any text it tokenizes. This creates two failure potential failure modes that could result in the behavior above:
- it potentially throws off any indexing that somehow doesn't accounts for the <s>
- if lmql tokenizes an any intermediate text, we incorrectly add the <s> again. (For the intermediate text tokenizations we should pass add_special_tokens=False)
The issue is that I'm not familiar with the tokenization logic for lmql. If someone gave me a quick high-level rundown of all the relevant tokenization files to change, I can submit a PR.
Hi Chris, thanks for raising this, I suspect (2) is the issue here.
Can you point me to the resources that allow one to get your version of llama/hf_llama7b. We have the weights (including permission to use them), but I have not found a good way to make easily work with HF yet. Then I can also reproduce this locally.
If you want to have a look, I would suggest start looking into https://github.com/eth-sri/lmql/blob/main/src/lmql/runtime/hf_integration.py#L60 first. There, we handle the edge case, that some tokenizer add a bos_token_id, which LMQL does by itself. Maybe this can already be fixed by moving this logic directly to https://github.com/eth-sri/lmql/blob/main/src/lmql/runtime/tokenizer.py.
Also, just a heads up, I bumped main to transformers==4.28.1, which brings official LLamaTokenizer support wrt. dependencies and it being included in the transformers library.
Interestingly I can't get a LLamaTokenizer to work on my machine, e.g. this code never finishes executing and depending on environment sometimes tokenizer.bos_token_id spirals into a recursion loop in HF transformers code:
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("aleksickx/llama-7b-hf")
print("loaded")
print("bos_token_id")
print(tokenizer.bos_token_id)
Thanks for the quick response!
After downloading Llama, huggingface provides a script here: https://huggingface.co/docs/transformers/main/en/model_doc/llama
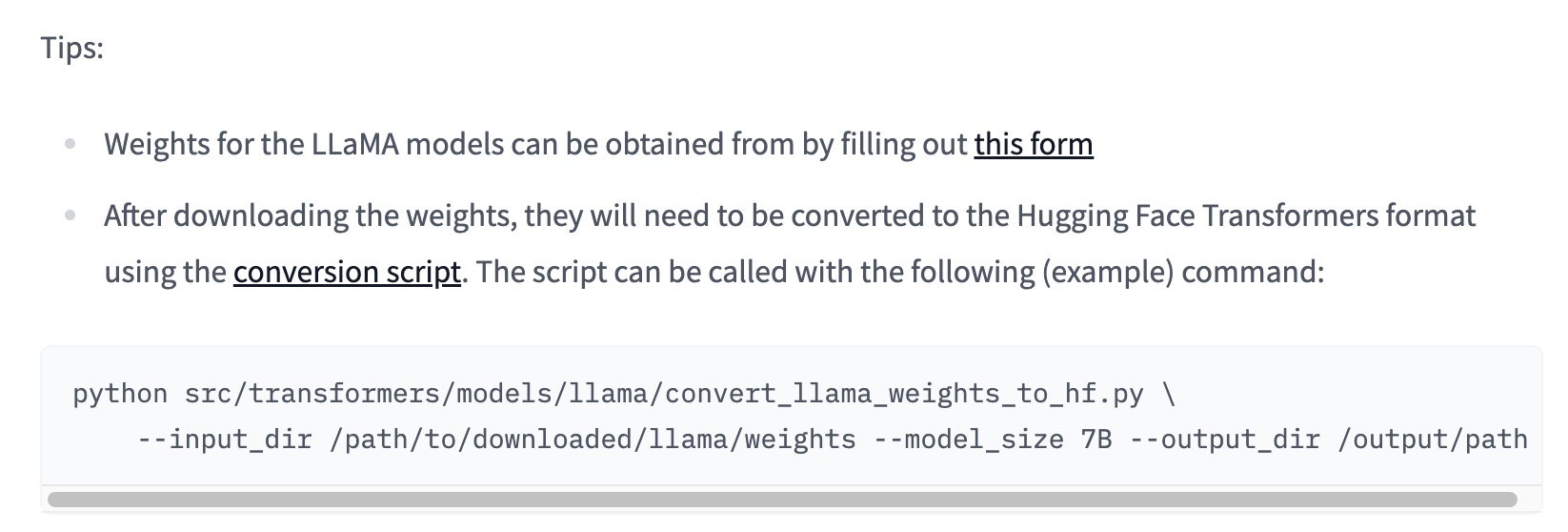
All I did locally was:
- Download Llama weights
- Run the script (putting the huggingface friendly llama weights into some directory)
- pip install sentencepiece and protobuf
- AutoTokenizer.from_pretrained("path/to/llama/llama7b")
I'll take a look at the tokenization logic right now and see if I move the logic to tokenizer.
It seems like there are multiple independent parts in the codebase that do tokenization, for instance in lmql.model.serve.TokenizerProcessor. Would you have to do any changes here, or does handling this issue in the client resolve the issue on the server?
Thanks for the instructions, I will have a look soon.
lmql.model.serve.TokenizerProcessor is outdated and should be removed, so there is no need to refactor it. I think the inference server does not really do tokenisation anymore IIRC. At least I yanked out the endpoints for that yesterday.
The underlying issue of this bug report has been fixed in the latest version, together with our addition of llama.cpp as model inference backend.
If you want to use llama models with HF transformers, I recommend huggyllama/llama-7b, which includes the latest fixes to the tokenizer implementations on the HF side. Older Llama models on the hub, sometime still included (slow variant) tokenises with buggy behaviour, that also affected LMQL.