etcd
 etcd copied to clipboard
etcd copied to clipboard
Yxjetcd rangestream
Please read https://github.com/etcd-io/etcd/blob/master/CONTRIBUTING.md#contribution-flow.
#12342 I will make an topic for resolve #12342 , and make test futhermore. If maintainer think this PR is good, I will do the following things.(unit test, proxy rangestream and lease reagestream)
This issue has been automatically marked as stale because it has not had recent activity. It will be closed after 21 days if no further activity occurs. Thank you for your contributions.
Hi @yangxuanjia, we have finished migrating the Documentation to https://github.com/etcd-io/website/. Could you please open a new PR there with the Documentation changes from this PR?
We did some evaluation of this branch.
It is using etcd benchmark tool range test. We did some change to the code so that it can send rangestream requests too.
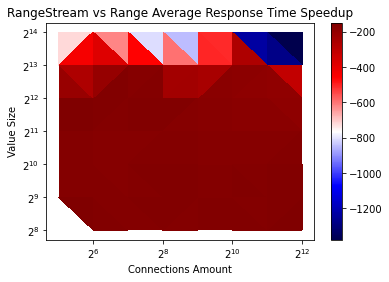
In our first test, the total is 10000 keys. we vary the number of clients/connections and the value size of the kv pair. The number of clients is always the same as the number of connections as they change.
for range requests, we set the limit to 500. So that each time range gets 500 KVs in response at maximum.
We plotted the result for both QPS and Average Response Time. They are very similar, I will just show the Average Response TIme here.
RangeStream
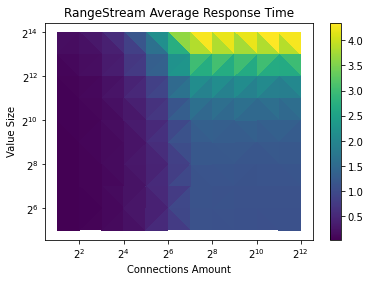
Range
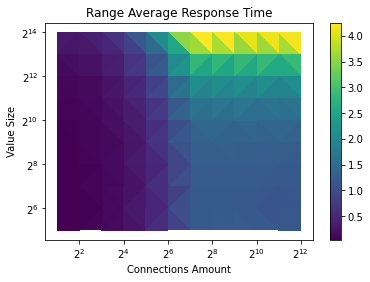
Diff

We can see that rangestream won't help much on performance unless the value size of the KV and the amount of the connection is large.
So what we can get from the memory usage?
We captured the memory usage and we see that compared with range request that has LIMIT and SORT specified. The memory usage of rangestream is actually higher. However, without LIMIT and SORT specified, range DO have a huge impact on system memory usage.
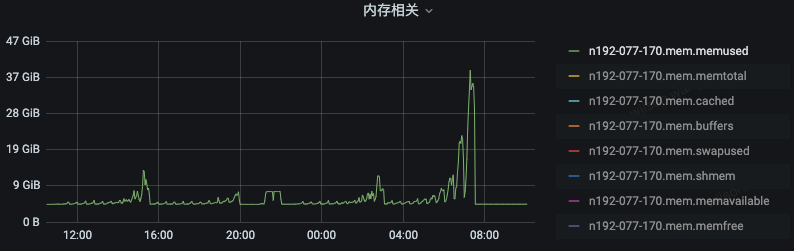
In the middle of the graph there is an "M" which was some personal running task. In the left half, I ran rangestream and range with LIMIT and SORT. On the right half, I ran rangestream and normal range.
So the final question is, do we really need rangestream? Or do we want the user (apiserver maybe?) to change the way they sending requests?
What could be other benefits we get from rangesteam? I want to hear what you guys think.
WIlson
I did another test on our physical machine with 3m key-value pairs. The key size is 256 bytes while the value size varies from 256 to 16K bytes. We can see that with a LIMIT specified, normal range memory usage is actually better than rangestream. Ideally, they should be similar. This might be related to some coding detail.
As a result, normal range request, if used properly with a Limit specified, should no longer trigger OOM in an environment with around 3m keys.
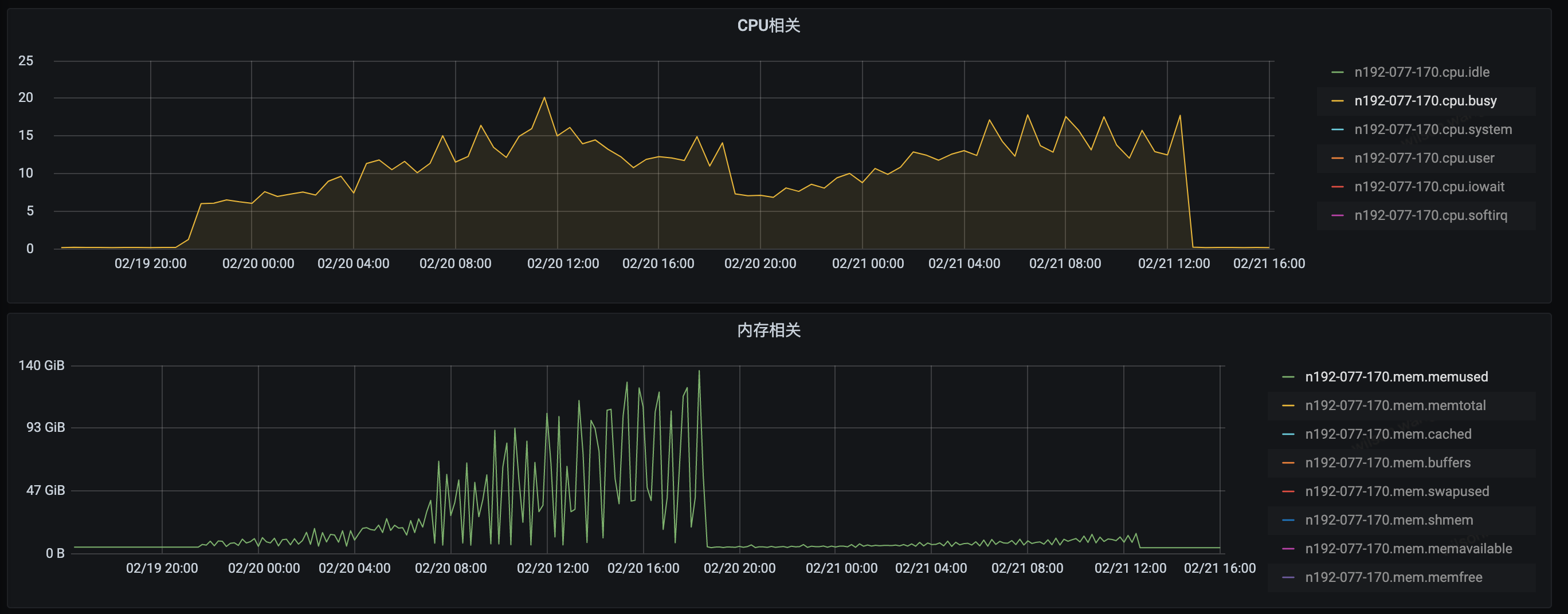 In this graph, left half is the cpu and memory usage when running rangestream. The right half is the similar setting when running normal range with limit specified. The limit is 10000 which is the default value used in API Server.
In this graph, left half is the cpu and memory usage when running rangestream. The right half is the similar setting when running normal range with limit specified. The limit is 10000 which is the default value used in API Server.
@wilsonwang371 I think your test may fall into a misunderstanding. You always prove that your test data looks good in the range under the set preconditions.
- As an underlying system like ETCD, it should do everything possible to ensure the stability of the system when used online, and eliminate all panic and OOM possibilities.
- On the premise that you cannot restrict how users use ETCD, ETCD is stable and OOM will not occur.
- A system like ETCD usually has no problems when it is just launched, but after running for half a year or a year, the online system suddenly crashes, often because the amount of data increases, the same The value of the key is getting bigger and bigger, the watch node is getting bigger and bigger, and suddenly OOM after ETCD reaches the bottleneck.
- Even for systems like K8S, when using ETCD, it is directly ranged without any limit restrictions. How can you expect other users' systems to consider clearly in advance that the ETCD range must add limit to avoid OOM (is it mentioned in the ETCD documentation?)
- range use 140G memory is dangerous signal, most of dockers we use online can't not allocate such big memory, mostly 16G, 32G memory for dockers, 64G is biggest most time. So we find ETCD easy to trigger OOM. Because ETCD not control exact memory used carefully. Therefore, rangeStream is a solution to avoid OOM and make ETCD online more stable. RangeStream purpose is not performance, but stability.
https://github.com/kubernetes/kubernetes/pull/94303 is related kuberentes discussion. It's probably right quorum to make decision whether k8s would prefer to use streaming or paginated polling.
I agree that presence of unlimited-size LIST is danger for stability, but in practice it means that at some point we would need to introduce sth. like --max-list-size-bytes=50MB to protect the backend.
@ptabor --max-list-size-bytes=50MB I don't think it's a good settings. Imagine a scenario where the application system has just been launched, and etcd has set --max-list-size-bytes=50MB. At this time, because the application system has just launched and the amount of data is relatively small, everything looks normal. As time grows, The amount of data is getting larger and larger. One day after 1 year, the online system suddenly reported an error, Error: range exceed max size, and the online business was suddenly unavailable. The R&D staff looked for the problem for half an hour and found that the range request data exceeded 50M It can't be used directly. Then, after hurriedly changing this parameter to 100M, an urgent application was made to restart ETCD. What about after that? 150M, 200M...how much should it be changed to?
Right. This style of limit really protects system, but is hard to 'predict' on the client side. The other approach is --max-range-limit=1000 (so all the range-scans needs to explicitly set limit:<1000), with per-object-max-size=1MB has the drawback of usage of 1GB of RAM.
@yangxuanjia: Question: Was there much analysis behind the decision to use a 1k batch size? In particular, I'm wondering what happens if we stream each result individually (sort of equivalent to batch==1), and never hold more than 1 result in memory plus a grpc/tcp send buffer. (ie: do 'batching' by output size in the send buffer). Should be much easier to control a memory budget in this way...
The next step down this path would be pushing the result/error channels even further down internally to the actual storage layers - never, ever build an array of results.
@yangxuanjia: Question: Was there much analysis behind the decision to use a 1k batch size? In particular, I'm wondering what happens if we stream each result individually (sort of equivalent to batch==1), and never hold more than 1 result in memory plus a grpc/tcp send buffer. (ie: do 'batching' by output size in the send buffer). Should be much easier to control a memory budget in this way...
The next step down this path would be pushing the result/error channels even further down internally to the actual storage layers - never, ever build an array of results.
There is not much thinking about this part, mainly because I think batch returns will be much faster than returning one by one. In the future, batch=1000 can be used as a startup parameter, which can meet the needs of returning one at a time. But it can also return many batches demand. There is only the difference in performance between the two, and I have not specifically compared it. If you want, you can post the test comparison.
rangeStream we use it for k8s big range to resolve OOM problem. I modify the inner rangeStream version include etcd, grpc-proxy. combine rangeRequest prototype for range and rangeStream. If need, I will update the code for this PR again.
this PR code version is old.
This issue has been automatically marked as stale because it has not had recent activity. It will be closed after 21 days if no further activity occurs. Thank you for your contributions.
This issue has been automatically marked as stale because it has not had recent activity. It will be closed after 21 days if no further activity occurs. Thank you for your contributions.
Is this still WIP?
I am working on https://github.com/etcd-io/etcd/pull/14810 that shares the idea on https://github.com/etcd-io/etcd/pull/12343#issuecomment-784008186 and it uses pagination so it won't break the queries.
It's kept in the backlog - it doesn't seem there is a maintainer that has capacity to proceed with the project, but technically it looks like a right thing to do. Improving the reliability is definitely higher priority than this.
PR needs rebase.
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes-sigs/prow repository.
This issue has been automatically marked as stale because it has not had recent activity. It will be closed after 21 days if no further activity occurs. Thank you for your contributions.