ASR decoding output text
There are my decode coef below
batchsize: 1 beam-size: 20 penalty: 0.0 maxlenratio: 0.5 minlenratio: 0.1 ctc-weight: 0.3 lm-weight: 0.5 ngram-weight: 0.0 nj= 2 ngpu=0
decode log
asr_recog.py --config conf/decode.yaml --ngpu 0 --backend pytorch --batchsize 1 --recog-json dump/test/deltafalse/split2utt/data.1.json --result-label exp/train_sp_pytorch_train/decode_test_decode_lm_4/data.1.json --model exp/train_sp_pytorch_train/results/model.last10.avg.best --rnnlm exp/train_rnnlm_pytorch_lm/rnnlm.model.best --ngram-model exp/train_ngram/4gram.bin --api v2 Started at Thu Sep 8 09:45:47 CST 2022
2022-09-08 09:45:48,674 (asr_recog:353) INFO: python path = /home/barry/espnet/tools/s3prl:
2022-09-08 09:45:48,674 (asr_recog:358) INFO: set random seed = 1
2022-09-08 09:45:48,674 (asr_recog:369) INFO: backend = pytorch
2022-09-08 09:46:31,019 (recog:33) WARNING: experimental API for custom LMs is selected by --api v2
2022-09-08 09:46:31,106 (deterministic_utils:26) INFO: torch type check is disabled
2022-09-08 09:46:31,106 (asr_utils:693) INFO: reading a config file from exp/train_sp_pytorch_train/results/model.json
2022-09-08 09:46:31,126 (asr_init:215) INFO: Reading model parameters from exp/train_sp_pytorch_train/results/model.last10.avg.best
2022-09-08 09:46:32,005 (encoder:177) INFO: encoder self-attention layer type = self-attention
2022-09-08 09:46:32,193 (decoder:124) INFO: decoder self-attention layer type = self-attention
2022-09-08 09:46:32,425 (encoder:174) INFO: encoder self-attention layer type = relative self-attention
2022-09-08 09:46:43,728 (asr_utils:693) INFO: reading a config file from exp/train_rnnlm_pytorch_lm/model.json
2022-09-08 09:46:43,898 (default:377) INFO: Tie weights set to False
2022-09-08 09:46:43,899 (default:378) INFO: Dropout set to 0.5
2022-09-08 09:46:43,899 (default:379) INFO: Emb Dropout set to 0.0
2022-09-08 09:47:03,987 (recog:139) INFO: BatchBeamSearch implementation is selected.
2022-09-08 09:47:04,094 (recog:153) INFO: Decoding device=cpu, dtype=torch.float32
2022-09-08 09:47:04,607 (recog:163) INFO: (1/3588) decoding BAC009S0764W0121
2022-09-08 09:47:23,615 (beam_search:356) INFO: decoder input length: 103
2022-09-08 09:47:23,991 (beam_search:357) INFO: max output length: 51
2022-09-08 09:47:23,991 (beam_search:358) INFO: min output length: 10
2022-09-08 09:47:44,332 (batch_beam_search:317) INFO: adding
2022-09-08 09:47:46,147 (asr_utils:889) INFO: groundtruth: 甚至出现交易几乎停滞的情况
2022-09-08 09:47:46,147 (asr_utils:890) INFO: prediction : 一线城市的房地产市场仍然有一定的影响力的一线城市的一线城市土地市场成交量的一线城市的一线城市的一线城市
2022-09-08 09:47:58,294 (asr_utils:889) INFO: groundtruth: 一二线城市虽然也处于调整中
2022-09-08 09:47:58,294 (asr_utils:890) INFO: prediction : 一线城市的房地产市场仍然有一定的影响力的一线城市的一线城市土地市场成交量的一线城市一线城市的一线城市
All of prediction text are same. Like
prediction :一线城市的房地产市场仍然有一定的影响力的一线城市的一线城市土地市场成交量的一线城市一线城市的一线城市
Will you please help me to understand about asr decoding?
I means, How different is the encoder+ctc(argmax) and asr decoding output?
All of prediction text are same. Like prediction :一线城市的房地产市场仍然有一定的影响力的一线城市的一线城市土地市场成交量的一线城市一线城市的一线城市 I have checked that ctc is work. And I have tried to adjust decode coef ,but it didn't work. I am trying restart the program from stage 0 now. Does anyone know how to fix it ?
Can you paste the learning curve and inference config?
network architecture
encoder related
elayers: 12 eunits: 2048
decoder related
dlayers: 6 dunits: 2048
attention related
adim: 256 aheads: 4
hybrid CTC/attention
mtlalpha: 0.3
label smoothing
lsm-weight: 0.1
minibatch related
batch-size: 24 maxlen-in: 512 # if input length > maxlen-in, batchsize is automatically reduced maxlen-out: 150 # if output length > maxlen-out, batchsize is automatically reduced
optimization related
sortagrad: 0 # Feed samples from shortest to longest ; -1: enabled for all epochs, 0: disabled, other: enabled for 'other' epochs opt: noam accum-grad: 2 grad-clip: 5 patience: 0 epochs: 6 dropout-rate: 0.1
transformer specific setting
backend: pytorch model-module: "espnet.nets.pytorch_backend.e2e_asr_conformer:E2E" transformer-input-layer: conv2d # encoder architecture type transformer-lr: 1.0 transformer-warmup-steps: 25000 transformer-attn-dropout-rate: 0.0 transformer-length-normalized-loss: false transformer-init: pytorch
conformer specific setting
transformer-encoder-pos-enc-layer-type: rel_pos
transformer-encoder-selfattn-layer-type: rel_selfattn
transformer-encoder-activation-type: swish
rel-pos-type: latest
macaron-style: true
use-cnn-module: true
cnn-module-kernel: 15
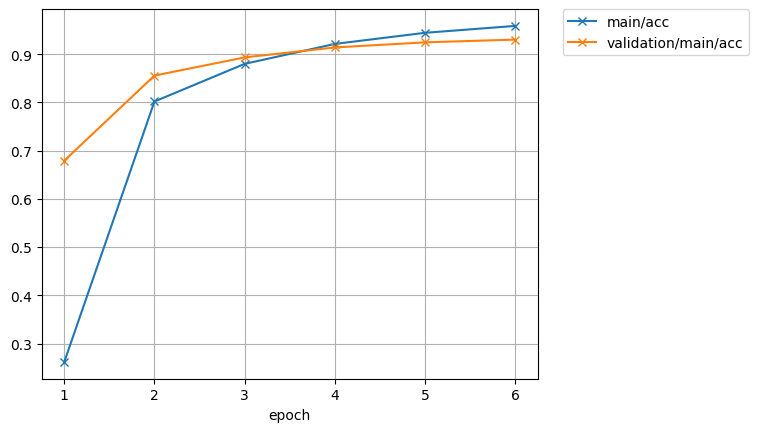
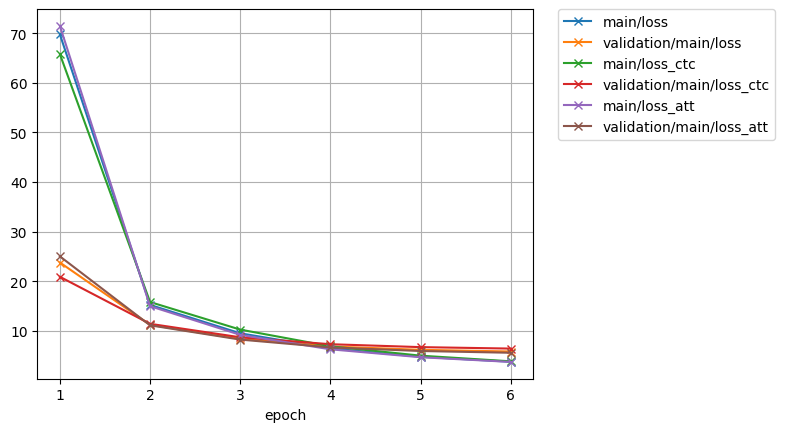
Did you use your own data? I guess your training/test split may have some issues.