huggingface model hub integration
Hi ESPnet team! As discussed offline with Shinji Watanabe (@sw005320) I hereby propose an integration with the HuggingFace model hub 🤗🤗
Samples models are visible (you can click on the "Use in ESPnet" button to display sample code):
-
TTS:
- https://huggingface.co/julien-c/ljspeech_tts_train_tacotron2_raw_phn_tacotron_g2p_en_no_space_train (
en) - https://huggingface.co/julien-c/kan-bayashi_csmsc_tacotron2 (
zh) - https://huggingface.co/julien-c/kan-bayashi-jsut_tts_train_tacotron2 (
ja, but widget not working due to more complex build dependencies)
- https://huggingface.co/julien-c/ljspeech_tts_train_tacotron2_raw_phn_tacotron_g2p_en_no_space_train (
-
ASR:
- https://huggingface.co/julien-c/mini_an4_asr_train_raw_bpe_valid
Or list all espnet models with https://huggingface.co/models?filter=espnet
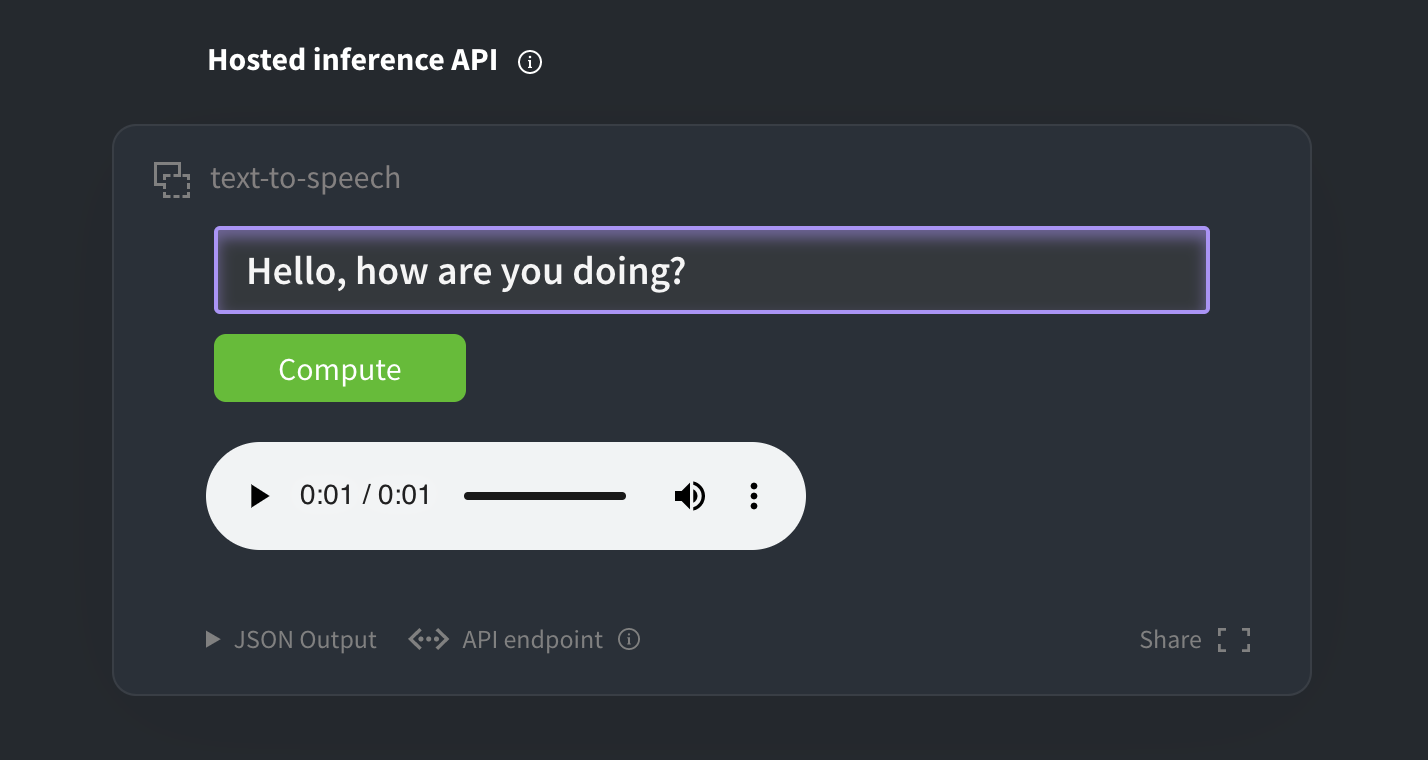
Demo widget on the first TTS model page:
The implementation in this PR relies on the huggingface_hub package, see readme over at https://github.com/huggingface/huggingface_hub
The implementations of both from_pretrained() methods are virtually identical (only the final line that instantiates the model differs), and could be factorized if necessary.
I've also added basic integration testing to the CI suite ✨.
Ok I was bitten by the fact that paths inside YAML files are re-written (tests were green on my local machine). Will try to find a work-around, but in the long term it might be cleaner to make all paths flow from the main meta.yaml
Codecov Report
Merging #2815 (4c7ece3) into master (c7dc873) will increase coverage by
1.04%. The diff coverage isn/a.

@@ Coverage Diff @@
## master #2815 +/- ##
==========================================
+ Coverage 80.64% 81.68% +1.04%
==========================================
Files 323 336 +13
Lines 28662 28953 +291
==========================================
+ Hits 23114 23650 +536
+ Misses 5548 5303 -245
| Impacted Files | Coverage Δ | |
|---|---|---|
| espnet2/enh/abs_enh.py | 0.00% <0.00%> (-100.00%) |
:arrow_down: |
| espnet/nets/pytorch_backend/ctc.py | 64.16% <0.00%> (-4.02%) |
:arrow_down: |
| espnet/nets/pytorch_backend/transformer/encoder.py | 92.23% <0.00%> (-2.62%) |
:arrow_down: |
| espnet/nets/chainer_backend/e2e_asr_transformer.py | 66.88% <0.00%> (-2.45%) |
:arrow_down: |
| espnet2/bin/enh_scoring.py | 92.64% <0.00%> (-2.36%) |
:arrow_down: |
| espnet2/bin/enh_inference.py | 94.05% <0.00%> (-2.34%) |
:arrow_down: |
| espnet/nets/pytorch_backend/e2e_asr_transducer.py | 94.82% <0.00%> (-2.04%) |
:arrow_down: |
| espnet2/bin/asr_inference.py | 92.59% <0.00%> (-1.83%) |
:arrow_down: |
| espnet2/torch_utils/initialize.py | 94.54% <0.00%> (-1.69%) |
:arrow_down: |
| espnet2/layers/stft.py | 91.17% <0.00%> (-1.02%) |
:arrow_down: |
| ... and 68 more |
Continue to review full report at Codecov.
Legend - Click here to learn more
Δ = absolute <relative> (impact),ø = not affected,? = missing dataPowered by Codecov. Last update c7dc873...9d85fa1. Read the comment docs.
- Could you tell me how to add a new model in more detail? Should we follow https://github.com/huggingface/huggingface_hub#publish-models-to-the-huggingfaceco-hub? Maybe we should add some instructions in https://github.com/espnet/espnet_model_zoo/blob/master/README.md?
Yes this is the way to go. You can probably just copy/paste those instructions to https://github.com/espnet/espnet_model_zoo or even to the espnet main README.md. I can help if needed
- Can we upload a public model without any charge?
Yes, public models are and will remain free.
According to https://huggingface.co/pricing, it seems that it would not be charged, but I just want to confirm it.
- Is it necessary to upload a model through zenodo, or we can directly upload a packed model to the huggingface model hub?
You can directly upload a model to huggingface.co, there's no need to go through zenodo.
The only difference with your current workflow is that you shouldn't zip the files before uploading them, just put them inside the model repo. It is very similar to GitHub. For reference this is the nexts I've taken to import the few models I've imported from Zenodo:
# create model repo on huggingface.co/new, then clone it locally:
git clone https://huggingface.co/julien-c/kan-bayashi-jsut_tts_train_tacotron2_ja
cd kan-bayashi-jsut_tts_train_tacotron2_ja/
git lfs install
git lfs track "*.pth"
# ^ make sure that model files will be versioned via git-lfs
# download the model from Zenodo. (For new models, skip this step and directly mv the files here)
wget -O archive.zip https://zenodo.org/record/3963886/files/tts_train_tacotron2_raw_phn_jaconv_pyopenjtalk_train.loss.best.zip?download=1
unzip archive.zip && rm archive.zip
# regular git workflow:
git add .
git commit -m "import from https://zenodo.org/record/3963886"
git log --pretty
git push
@julien-c
I added a script to prep librispeech (dev/test only) and run inference using your huggingface intergration. I found that while this works when using a single job, multiple jobs runs into errors.
Could you also check out difference between these two settings?:
./run_pretrained_inference.sh --inference_nj 1
./run_pretrained_inference.sh --inference_nj 32
The problem occurs when the config file is loaded from cache. It could be a result of some bad formatting from ESPnet? But I'm not sure - hopefully we can solve it together.
The yaml in question: https://huggingface.co/byan/librispeech_asr_train_asr_transformer_e18_raw_bpe_sp/blob/main/exp/asr_train_asr_transformer_e18_raw_bpe_sp/config.yaml
@brianyan918 hard to say, but it might be because of the yaml-rewriting workaround described in https://github.com/espnet/espnet/pull/2815#issuecomment-751490620
Ideally, all file paths should flow from the main meta.yaml – but it might require wider changes to the codebase.
i.e. that part: https://github.com/julien-c/espnet/blob/9cde807306bf6660a4801f0466409b057cc7cbe4/espnet2/utils/hf_hub.py#L34-L47
@brianyan918 I suspect it's because of the yaml-rewriting workaround described in #2815 (comment)
Ideally, all file paths should flow from the main
meta.yaml– but it might require wider changes to the codebase.
I see. I thought instead it had to do with the cached files being saved in an unexpected format. I actually used yamllint to clean up our yaml file a bit, which resolved some of the issues but not all.
If you're able to run the inference script, can you let me know if you encounter the same?
I am wondering about this PR, which are the problems before merging? (besides the conflicts?) Also, It will be better to prepare an organization and a list to check the uploaded models.
Ok let's finally close @sw005320! Happy to collaborate further in the future though
Thanks, @julien-c We have several collaboration items. We also recently started making some unified datasets (wrappers) to handle multiple datasets, mostly aiming to utilize cool HF datasets. Please keep in touch.