Make multiple glob modifiers behave like chaining, instead of Cartesian product
While working on issue #1018 I added a few relevant unit tests. Which caused me to notice the tests are fragile because they assume the wildcard expansion will be in a specific order. But wildcard expansions are not sorted so the test is really depending on machine specific behavior involving the order in which objects are created and directories are traversed. It seems to me the results of a wildcard expansion should always be sorted. The cost of sorting the results will normally be negligible and will a) make the unit tests less fragile, and, more importantly, b) result in more user friendly behavior.
There are some subtle aspects to this feature request. Should the sort be case sensitive or insensitive? Should it attempt to deal with numbers so that "x1", "x5", "x12" sort to that order or the naive ordering "x1", "x12", "x5"?
I think sorting needs to be kept as simple as possible. Once you start worrying about case, next you have to worry about accents, NFC versus NFD forms, and whether Gauß should be sorted with GAUSS. Then there is the possibility of filenames that aren't even properly formed unicode. Plus, there may be a call to obey locale settings! We probably don't want to go down that particular wormhole.
So I think there is a need to aim for predictability and repeatability, even if the result does not necessarily conform to the user's expectations. I.e., sort lexicographically by byte order.
I agree that we shouldn't worry about NFC versus NFD forms. But I do think it is reasonable to treat the pathnames as UTF-8, falling back to byte comparisons if the string isn't valid UTF-8.
For people unfamiliar with terms like "NFC" this Wikipedia article discusses the subtleties involved with non-English languages and why terms like "NFC" and "NFD" exist: https://en.wikipedia.org/wiki/Unicode_equivalence. Since elvish is not a word-processor, typesetting software, or the like I can't see any justification for elvish dealing with such subtleties. But if Elvish is going to do so then the problem extends far beyond this proposal to sort wildcard expansions as it affects string equality tests, the re: module, etc.
Despite having used the fish shell, and contributed to the project, for several years I am not convinced that magically handling embedded integers in file names is a good idea. Especially since the fish implementation only handles decimal integers.
FWIW, I think sorting wildcard expansions should be case-insensitive; albeit ignoring the subtleties of some non-ASCII languages. The more interesting question is whether to handle numbers in file names. I vote not to treat "numbers" in file names specially. The fish source says (in src/util.cpp):
/// Compare two strings, representing file names, using "natural" ordering. This means that letter
/// case is ignored. It also means that integers in each string are compared based on the decimal
/// value rather than the string representation. It only handles base 10 integers and they can
/// appear anywhere in each string, including multiple integers. This means that a file name like
/// "0xAF0123" is treated as the literal "0xAF" followed by the integer 123.
///
/// The intent is to ensure that file names like "file23" and "file5" are sorted so that the latter
/// appears before the former.
///
/// This does not handle esoterica like Unicode combining characters. Nor does it use collating
/// sequences. Which means that an ASCII "A" will be less than an equivalent character with a higher
/// Unicode code point. In part because doing so is really hard without the help of something like
/// the ICU library. But also because file names might be in a different encoding than is used by
/// the current fish process which results in weird situations. This is basically a best effort
/// implementation that will do the right thing 99.99% of the time.
It also says (in src/util.h):
/// Compares two wide character strings with an (arguably) intuitive ordering. This function tries
/// to order strings in a way which is intuitive to humans with regards to sorting strings
/// containing numbers.
///
/// Most sorting functions would sort the strings 'file1.txt' 'file5.txt' and 'file12.txt' as:
///
/// file1.txt
/// file12.txt
/// file5.txt
///
/// This function regards any sequence of digits as a single entity when performing comparisons, so
/// the output is instead:
///
/// file1.txt
/// file5.txt
/// file12.txt
///
/// Which most people would find more intuitive.
///
/// This won't return the optimum results for numbers in bases higher than ten, such as hexadecimal,
/// but at least a stable sort order will result.
///
/// This function performs a two-tiered sort, where difference in case and in number of leading
/// zeroes in numbers only have effect if no other differences between strings are found. This way,
/// a 'file1' and 'File1' will not be considered identical, and hence their internal sort order is
/// not arbitrary, but the names 'file1', 'File2' and 'file3' will still be sorted in the order
/// given above.
That is a lot of complexity that will result in confusing results some of the time. As someone who used fish for several years I appreciate its emphasis on user friendliness. But this is one area where I think fish went too far and created more problems than they solved.
Actually, I think that if you sort UTF-8 strings just treating them as sequences of unsigned bytes, you get the same order as if you treated them as sequences of Unicode code points. This would be like using the standard sort program in a locale with LC_COLLATE="C".
To do case-insensitive sorting, then, here is one possible way: For every filename, convert it to one case (upper or lower, I don't know that it matters much, except for the German ß). If the conversion fails because the filename is not valid UTF-8, keep it as is. This is the primary sort key. Use the original filename as a secondary sort key, for use on case sensitive file systems. For the latin alphabet (A-Z), that will sort uppercase letters before lowercase letters. I don't think you can count on this property for non-ASCII letters, though. It that is considered important, you'll have to work harder.
It would be desirable, perhaps, if expanding wildcards would give the same order as produced by ls. I am sure that is more or less what users would expect? But that seems tricky. On the Mac, I can't persuade ls (builtin or the GNU version from macports) to do case-insensitive sorting, no matter how I set the locale. On ubuntu, on the other hand, ls does indeed obey the locale settings. But this seems to be just a deficiency in the builtin locales on the mac:
⬥ for x abAB { echo $x } | E:LC_COLLATE=en_US.UTF-8 sort
A
B
a
b
So getting the same sort order from ls and wildcard expansion seems to be just too hard.
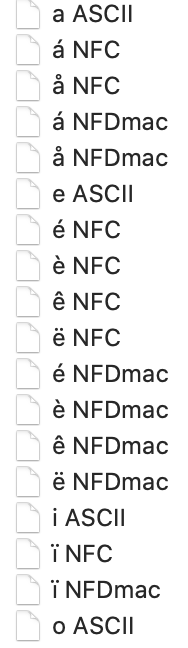
On normalisation issues: I experimented a little. Here is a directory listing from my mac. Each filename is a single unicode glyph, followed by a space and an indication of encoding (I had to run stty oxtabs first to get a paste friendly output):
⬥ ls
a ASCII e ASCII ê NFDmac ï NFDmac å NFC ê NFC
á NFDmac è NFDmac ë NFDmac o ASCII è NFC ë NFC
å NFDmac é NFDmac i ASCII á NFC é NFC ï NFC
I have to admit, I much prefer the sorting implied by NFD, as the NFC versions all wind up far from the corresponding unaccented letters. It is interesting to compare the sort order used by the Finder:
I'll leave those as data points to ponder.
I'll just add a word about filename encodings on the Mac: On HFS+ filesystems, filenames are forced into a version of NFD. It's actually NFD based on an old Unicode version. APFS filesystems, on the other hand, are claimed to be normalisation sensitive, but also normalisation preserving: So files are stored with their names as given by the user, but you can't have two files whose normalised forms are the same. As far as I can tell, files created with the standard file dialogs get the NFD form. But in the terminal (both Terminal and iTerm2), what you type gets the NFC form, so files created from the terminal tend to be named using NFC.
Sorting sounds good.
Regarding how to sort, I'm not convinced of the ROI of adding any kind of smartness, and I feel we should just use sort.Strings, which sorts by the byte sequence [1], unless there is another simple, clearly superior way.
[1] Sorting the UTF-8 encoding of a Unicode string is actually equivalent to sorting by the codepoints.
Sorting the UTF-8 encoding of a Unicode string is actually equivalent to sorting by the codepoints.
Yes, but only for case-sensitive sorting. I personally prefer that because it's what I'm used to from decades of using the ls command. But I know some people prefer case-insensitive order; which is why fish uses it.
For now let's keep it simple and efficient by doing a simple case-sensitive sort by assuming the pathnames are UTF-8 so a simple byte comparison is all that is needed.
While working on implementing the wildcard [type:xxx] modifier I noticed a quirk of the existing wildcard expansion behavior. Cd into an otherwise empty directory then do this:
$ touch a b
$ put ?[set:aeoiu digit]
▶ a
▶ a
$ put ?[set:aeoiu][digit]
▶ a
The first example, sort of, creates a cartesian product of two independent modifiers. The second example is effectively an "or" operation (considering only "local" not "global" modifiers). I said "sort of" regarding the first example because no file matches the [digit] index yet it still contributed a non-nil value to the expansion. Which means it's really more like a SQL "outer join" than a mathematical cartesian product.
Regardless of the merits of the current expansion behavior I'll point out that ordering the results should eliminate such duplicate entries. That deduplication of the sorted result should only be skipped if the input can be guaranteed to not generate a pathname more than once.
For the record, it turns out that simple globs are already sorted by virtue of using ioutil.ReadDir. Which could make you think that any change to the implementation is not needed. However, non-simple globs can result in reading a directory more than once and thus including a given filename in the expansion more than once. That is what caused me to open this issue.
Also worth noting is that sorting the expansion before filtering by modifiers is inefficient. For the typical glob that isn't much of a concern. However, for a glob like **[type:dir] it can result in a noticeable cost.
So I'm going to replace ioutil.ReadDir with os.Readdir and defer the sorting, and duplicate elimination, to the point where the glob expansion is returned to the user.
I reworded the title of the issue to reflect my preferred implementation strategy here (some discussion is in #1143).