[Feature] Store elementary results in a single schema
At the time of writing this with elementary 0.4.1, elementary persists results per dbt's schema. But, personally, it can get messy, as I have a lot of dbt's schema, that is, BigQuery datasets. Let's consider if we have 60 BigQuery datasets accross 5 Google Cloud projects in a dbt project. The same number of new BigQuery datasets for elementary are created. It looks messy for me. I would like to bundle them in a single BigQuery dataset to keep it clean. Moreover, it would be nice to specify a single destination schema in a database, that is, a single destination BigQuery dataset in a GCP project.
I misunderstand the behavior. In reality, elementary stores results to a single schema. But, I think it can get better. The destination database and schema is ones of the first values whose package_name is elementary. Let's consider if we have multiple databases and schemas with dbt tests by elementary. The destination can vary the order of graph.nodes.values().
Instead, personally I think it would be good to specify the destination database and schema for elementary rather than the current implementation. I will open a new issue whose focus on enablig to specify the destination database and schema.
- https://github.com/elementary-data/dbt-data-reliability/blob/0d76607370311d4411ac2a7a2250f4d532c0138b/macros/utils/graph/get_model_database_and_schema.sql#L7-L10
- https://github.com/elementary-data/dbt-data-reliability/blob/0d76607370311d4411ac2a7a2250f4d532c0138b/macros/utils/graph/get_model_database_and_schema.sql#L7-L10
I created another issues to improve this.
- https://github.com/elementary-data/elementary/issues/98
Hi @yu-iskw, thanks so much for opening an issue!
Let me shed some more light on the current behavior -
You can control the database and schema of Elementary's output using dbt's custom schema and dbt's custom database features. Our recommended configuration looks as follows -
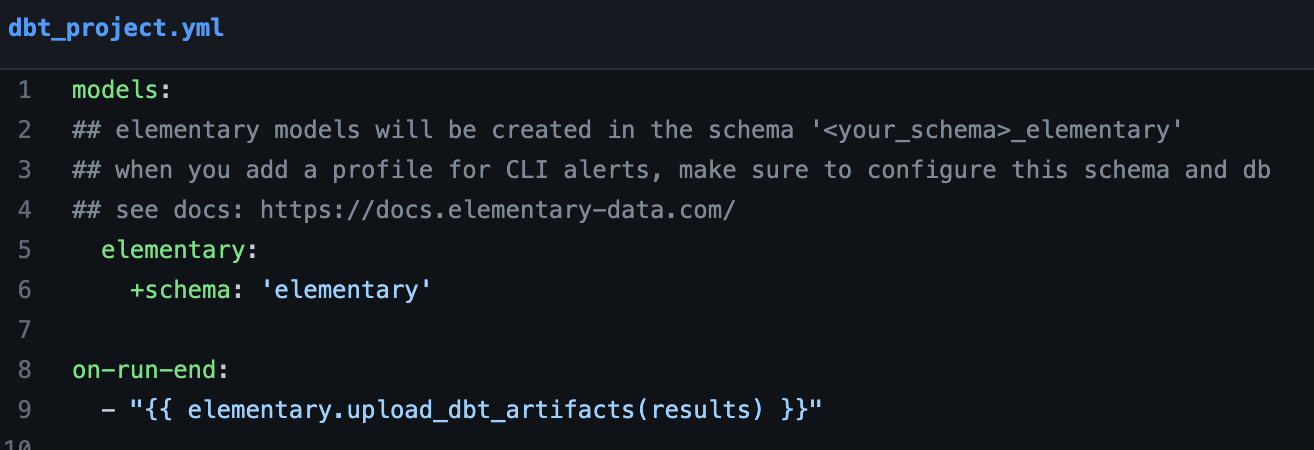
By default, this means that Elementary's models will be created in a custom schema <your_dbt_schema>_elementary as dbt concatenates the custom schema to the schema defined in your profiles.yml. You can also override this default dbt logic using a macro called generate_schema_name (see this doc to learn more about it).
Now Elementary dbt package has three parts -
- Regular dbt models which usually are stored in <your_schema>_elementary
- dbt tests macros. Since dbt tests can run in parallel and in multiple threads each test is writing its results to a separate set of tables (they are being re-created every dbt test run). Currently these are stored at <your_schema>_elementary__tests and you can treat them as temporary tables (this resembles the dbt store failures feature).
- on-run-end hooks that are responsible for aggregating the metrics, test results and dbt run results into the tables that were created by the Elementary models. To find these tables in the on-run-end hooks we use the dbt graph to find an Elementary model (just taking the first as we just need one) and then we extract its database and schema to make sure these are being aggregated to the correct places and tables. We could potentially simplify this dramatically by just using simple dbt 'ref' instead of doing this workaround, it's just that we had some issues in the past with partial parsing (which I think are now solved by dbt so potentially it's a good timing to test and change it).
To sum it up, using the custom schema and database you can configure all of Elementary models (which contain test results, data metrics, dbt artifacts, schema changes and more) to be created in the same place. By default and if you follow the recommended configuration it's here <your_schema>_elementary (the temp test tables are stored then in <your_schema>_elementary__tests at the moment).
Please let me know if this clarifies and solves the issue or if you have any further questions about it! :)
@oravi Thank you for the explanation in detail. I totally understand how the destination database and schema are determined. They come from a dbt profile and models' schema of elementary, not our own dbt models. In that way, we can already specify the destination database and schema for elementary.
Whereas, I still feel the current configuration is not intuitive, because the destination schema is composed of a schema in a dbt profile and +schema under model.elementary. For instance, when we have the subsequent configurations in profiles.yml and dbt_project.yml, the destination schema for elementary is my_dataset_xxx_elementary_yyy. Personally, it would be nicer to have a single configuration point to settle the destination schema. What do you think?
--- profiles.yml for BigQuery
jaffle_shop:
target: dev
outputs:
dev:
project: "my-project"
dataset: "my_dataset"
--- dbt_project.yml
models:
elementary:
+schema: 'xxx_elementary_zzz'
@yu-iskw Yeah I agree that it could be nice to support configuring it explicitly using vars as well. We just need to make sure that the existing method will still work to support backwards compatibility, and also some teams are probably already accustomed to it. We will look into it and get back with our findings and suggestion.
In the meantime and as a workaround you can still override this default concatenation behavior of dbt using a macro called 'generate_schema_name'. What do you think about it?