Having issue while using in multi POD
Hello,
I am using 3 pods and disk_usage_exporter as sidecar. But out of 3 only one pod running without any issue and scraping the metrics even with less resources. But other two pods behaving weird, not scraping the metrics, if I try to scrape the metrics locally, pods are getting restarted with OOM issue. I have allocated enough resources still the same.
[root@local-path-provisioner-monitoring-wwp9n /]# curl http://localhost:9995/metrics curl: (52) Empty reply from server
And the other one immediate response
`[root@local-path-provisioner-monitoring-plq4d /]# curl http://localhost:9995/metrics
HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 6.5438e-05 go_gc_duration_seconds{quantile="0.25"} 8.8972e-05`



And other two

Definitely it's not for scrape timeout as it's failing locally .
Could you please help me out to fix this issue.
Hello, what is approx the disk size of the pods and attached volumes? Gdu allocates circa 300MB RAM per 100GB of disk usage if running in the default mode and enough free RAM is available.
Thanks Daniel For your response. It seem after allocating more resource issue got resolved.
Our requirement is to monitor local-path-provisioner (PVC). So the approach is like we need to mount the localpv on PODS and using some exporter pull the metrics. As we cannot run any exporter on Nodes.
let's say there will be 5-6 PV's size of 1.5TB on each node and may be more that that. We need to monitor all the PV's.
`[root@observability-pvc-metrics-nzbp2 /]# df -kh /localpv Filesystem Size Used Avail Use% Mounted on /dev/mapper/gainvg-root 11T 2.6T 8.1T 24% /localpv
[root@observability-pvc-metrics-nzbp2 /]# ls -lrt /localpv/ total 0 drwxrwxrwx 4 root root 130 Oct 28 11:10 pvc-cfbda679-da2f-46ca-85b6-8b9af8d6c612_datadir-redpanda-retail-0 drwxrwxrwx 2 root root 26 Nov 7 10:47 pvc-b4ca1e1b-4da9-4fd7-b773-b391459db1a8_katana_test drwxrwxrwx 4 root root 150 Nov 7 12:20 pvc-9509a8ad-c059-40ec-9a1c-30c8ec3ff82b_messaging-redpanda-observability_datadir-redpanda-observability-2 drwxrwxrwx 5 root root 176 Nov 7 12:22 pvc-4b5c375a-2e7f-43ee-bf73-f4a47e85bc4a_messaging-redpanda-retail_datadir-redpanda-retail-1 drwxr-xr-x 2 root root 10 Nov 10 07:40 kishore-test-localpv`
Also consuming high CPU
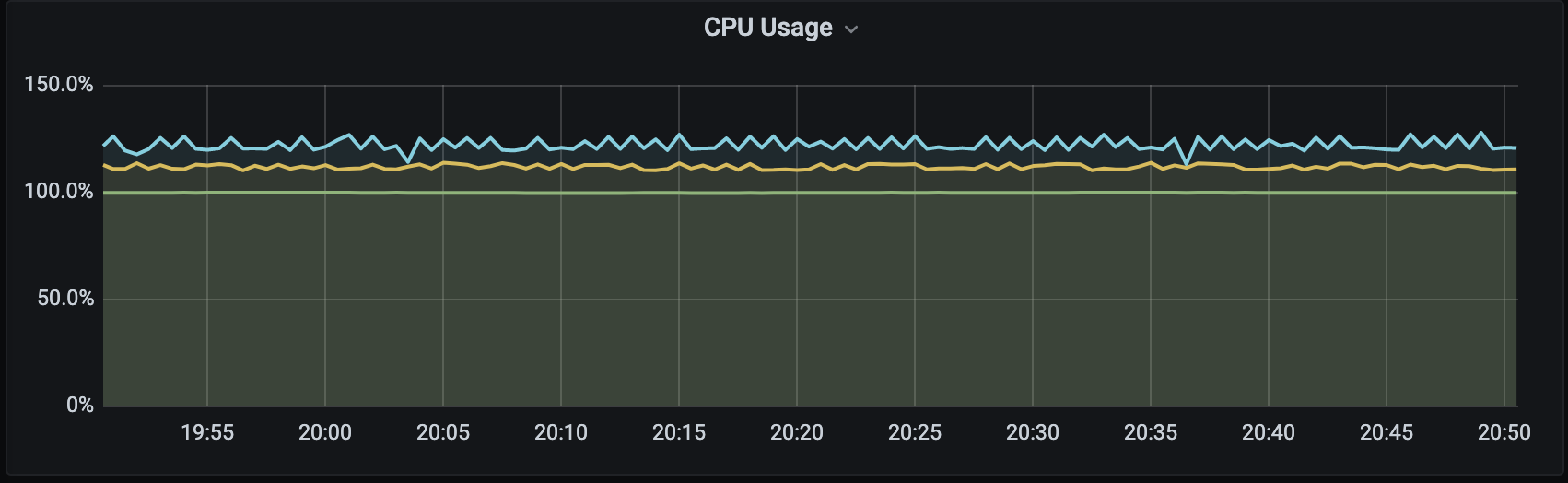
Do you think we can use this exporter for out requirement. If so Could you please share the Dockerfile of ghcr.io/dundee/disk_usage_exporter/disk_usage_exporter-c4084307c537335c2ddb6f4b9b527422:latest image
There is no Dockerfile used here. It's just call to https://github.com/ko-build/ko in CI workflow.
I think this exporter should be capable to do what you need. There might be needed some playing around to get it running properly. E.g. setting garbage collection level - https://github.com/dundee/gdu/#memory-usage