HTTP request waterfall when querying multiple Parquet files in S3
More of a question than an actual bug report. I experimented with DuckDB WASM over the weekend, where I have some partitioned Parquet files in a S3 bucket. Now, I want to query those files with DuckDB WASM. I wondered why my query took so long, then I had a look on the network tab in Chrome:
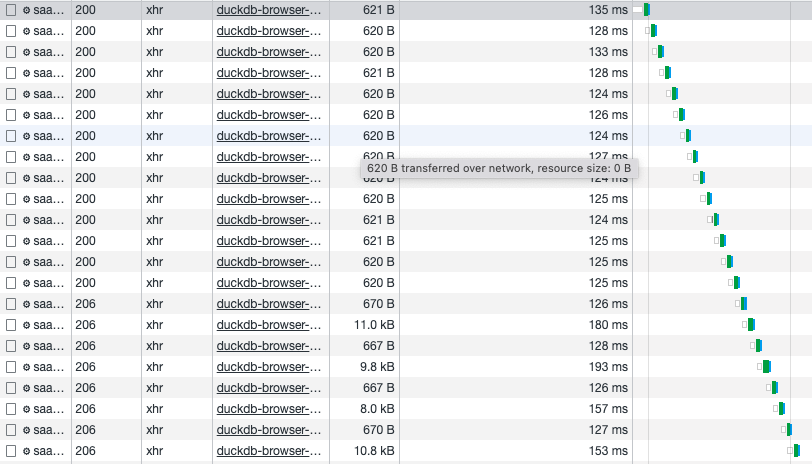
I honestly wonder if/why the requests couldn't be parallelized, instead of the seemingly sequential access pattern. This would really increase the query speed for my use case (multiple smaller files).
Thanks for any feedback!
This explanation sounds reasonable to me? https://github.com/dotnet/aspnetcore/issues/26795
Thanks @Mause for the feedback. The request shouldn‘t be directed at the same URL in my case, as those are partitioned parquet files with specific names…
I can try Setting the no-store cache header, but this feels counter-productive tbh.
Unfortunately not @rickiesmooth. As far as I understood the parallelism problem is not yet solved, but maybe @pdet can share some insights?
I believe at least part of the problem here is S3 only supports HTTP/1.1. You can see this if you show the Protocol column on the Network tab view. Chrome and other browsers limit the number of concurent connections to the same host. To prevent the user from being throttled but other reasons as well. Newer HTTP/2 can do multiplexing (streaming multiple files on a single TCP connection) and reusing connections to avoid multiple TLS handshakes and HTTP/3 can do streaming via UDP and eliminate head of line blocking.
One option is to use CloudFront instead with an S3 origin which supports HTTP/2 and 3.
@dude0001 Thanks for the input, that might be the problem. I assume hosting the data on CloudFront not only incurs costs, but to my understanding then we can no longer use globs or Hive partitioned reads... Or am I mistaken?
I'm not an expert, but I believe you are correct globbing would not work with CloudFront. There is no way I'm aware of to list resources like you can do with an S3 bucket. I do not see why hive-partitioned reads would not work if you enumerate the files though for those that are still practical.
There was just a discussion in the DuckDB Discord about this:
- https://discord.com/channels/909674491309850675/921073327009853451/1156256117807124561
- https://discord.com/channels/909674491309850675/921073327009853451/1156256186031689870
Seems like this wouldn't work over HTTPS like it works via S3.