performance
Current FFT implementation uses classic Decimation in Time, Radix-2, in-place algorithm, which is far from being the best in class. I am comparing Float64, Float32, and Array implementations on three V8 based engines.
Raw benchmarks for (node 0.12.2, 0.10.38; iojs 1.6.3, FF36) can be found in Travis logs here: https://travis-ci.org/drom/fourier
Here are some charts I have crafted from the results on my Intel(R) Core(TM) i5-4200U CPU @ 1.60GHz. most of points are less then ±5% variation:

Using FFT Benchmark Methodology from here: http://www.fftw.org/speed/method.html
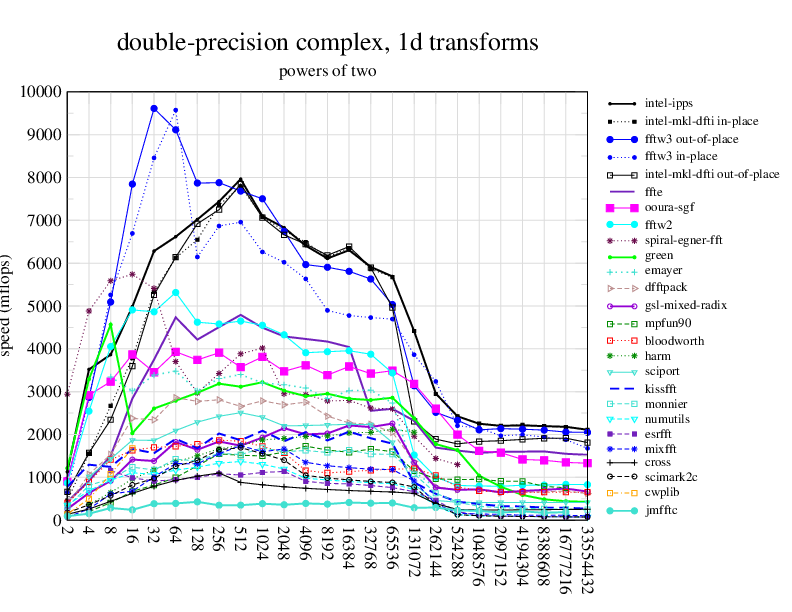
Here is the chart from http://www.fftw.org/speed/CoreDuo-3.0GHz-icc64/ : Which includes some state of art FFT implementations in C.
Double precision:
Single precision:
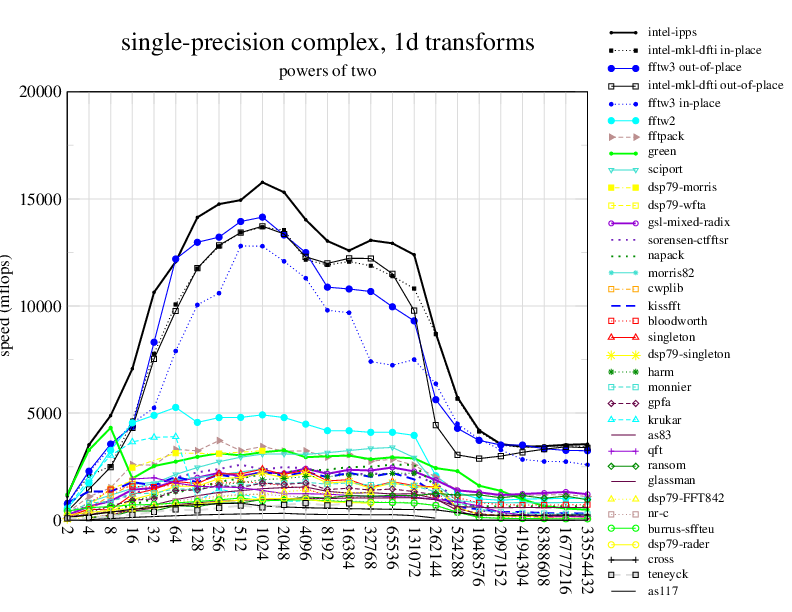
Obviously this just the beginning and we are x20 slower then the best; and results are different with different version of V8 engine; and because of dynamic nature of modern JavaScript run-time speed may suddenly change.
In my list to try:
- higher radix algorithms (4,8,16,...)
- better data / operation flow organisation.
- data type casting techniques like asm.js
- SIMD extensions: https://github.com/johnmccutchan/ecmascript_simd
Any other ideas are welcome!
I have created templated version of fft with one custom version of function per size.
The overall performance is higher. Float32 version always the fastest. V8 v0.10 has higher threshold to start JIT optimizer. io.js is the most reliable performance and the best performance with standard Arrays. Chart shows 10x performance difference between compiled and optimized versions.

Progress
Here is some progress on FFT implementation. The same Radix-2 DIT generator. Produces asm.js code for Float32 and Float64 typed arrays.

Observations
- Dramatic improvement of Float64 versions. It is clearly faster then Float32. How come???
- Firefox got the biggest benefit from asm.js rewrite. 5x for Float64 case.
- node v0.12.2 shows improvment but not that much as Firefox.
- node v0.10.38 about the same on Float64, degradation on Float32.
- io.js 1.6.3 -- significant degradation.
- in overall -- performance is more consistent; probably because of AOT compilation.
Here is some update on asm.js:
I improved Float32 implementation by adding float coercion using Math.fround() function.

Results
- Firefox is the only engine that understand this trick.
- node v0.10.38 has no
Math.fround()function -- so bumper! I have to put dummy function here; that makes performance very low. - node v0.12.2 and iojs 1.6.3 shows performance degradation compare to vanilla JS.
Conclusion
Looks like strict asm.js is good for Firefox only. v8 understands some of tricks but needs very different code to run fast. Any suggestions?
p.s. I have added http://jsperf.com/fft for FFT 64K
I have made some progress today -- separated asm and raw versions of FFTs.

As one can see:
- only FF benefits from
asmnotations. asmfloat32 casting usingfround()is bad for v8- node v0.12 and iojs is about the same on
rawversions.
I have published 64K versions here: https://jsperf.com/fft/2
I have benchmarked Node 4.1.0, Node 5.1.0 and FF42

Looks like Node finally got f32 right!
Efficient FFT Algorithm and Programming Tricks http://cnx.org/contents/4kChocHM@6/Efficient-FFT-Algorithm-and-Pr