TarWriter uses ASCII to write down fields and should use UTF8 instead
All formats use ASCII encoding to write down fields, which is unfortunate because a UTF8 name like "földër" will look garbled when read back.
MemoryStream ms = new MemoryStream();
TarWriter writer = new(ms, leaveOpen: true);
GnuTarEntry gnuEntry = new(TarEntryType.Directory, "földër");
writer.WriteEntry(gnuEntry);
writer.Dispose();
ms.Position = 0;
TarReader reader = new(ms);
TarEntry readEntry = reader.GetNextEntry();
Console.WriteLine(readEntry.Name); // Prints "f?ld?r".
reader.Dispose();
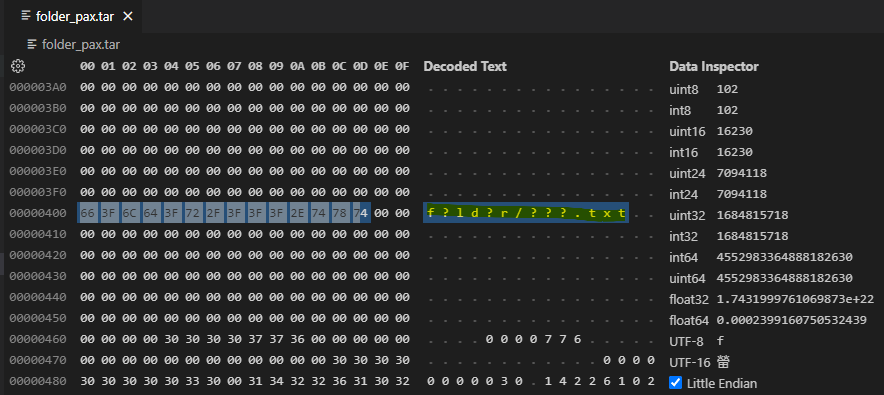
This is visually mitigated on Pax because UTF8 encoding is used to write down extended attributes and fortunately, that's the default format. However, legacy fields on Pax entries do get garbled but when using .NET APIs, we overwrite the legacy fields with the contents of the extended attributes. So AFAIK, the issue in pax shows only if you look at the bytes of the tar archive:
cc @carlossanlop @stephentoub @danmoseley @tmds
Tagging subscribers to this area: @dotnet/area-system-io See info in area-owners.md if you want to be subscribed.
Issue Details
All formats use ASCII encoding to write down fields, which is unfortunate because a UTF8 name like "földër" will look garbled when read back.
MemoryStream ms = new MemoryStream();
TarWriter writer = new(ms, leaveOpen: true);
GnuTarEntry gnuEntry = new(TarEntryType.Directory, "földër");
writer.WriteEntry(gnuEntry);
writer.Dispose();
ms.Position = 0;
TarReader reader = new(ms);
TarEntry readEntry = reader.GetNextEntry();
Console.WriteLine(readEntry.Name); // Prints "f?ld?r".
reader.Dispose();
This is visually mitigated on Pax because UTF8 encoding is used to write down extended attributes and fortunately, that's the default format. However, legacy fields on Pax entries do get garbled but when using .NET APIs, we overwrite the legacy fields with the contents of the extended attributes. So AFAIK, the issue in pax shows only if you look at the bytes of the tar archive:
cc @carlossanlop @stephentoub @danmoseley @tmds
| Author: | Jozkee |
|---|---|
| Assignees: | - |
| Labels: |
|
| Milestone: | 8.0.0 |
Should we fix for 7.0? What is the risk of breaking something else if we fix this?
https://github.com/dotnet/runtime/pull/75373#discussion_r967650446
What is the impact if we don't do this? Does it prevent roundtripping / another tool deserializing tar archives produced by TarWriter?
There's a high liklihood file names will contain non-ASCII characters.
What do other tools do? Why did we start with ASCII?
Does it prevent roundtripping / another tool deserializing tar archives produced by TarWriter?
I tried opening with 7Zip an archive created with TarFile.CreateFromDirectory and that worked just fine.
What do other tools do?
I tried BDS Tar on WSL Ubuntu with all the supported formats and all of them encode the name as UTF8.
What is the impact if we don't do this?
For formats other than Pax, containing a name or some other field (such as LinkName) that contains non-ASCII characters, those characters will be garbled as shown in the picture of the original post. Keep in mind that Pax is the default.
For formats other than Pax, containing a name or some other field (such as LinkName) that contains non-ASCII characters, those characters will be garbled as shown in the picture of the original post.
But they'll be garbled not just if someone inspects the value in a debugger but also if any other non-.NET tool tries to untar them, right? e.g. they'll produce garbage names in the file system?
Keep in mind that Pax is the default.
Sure... and we make it easy to do something other than the default.
Is there any impact on reading archives using our API, created by other Tar tools, and using non-ASCII metadata?
What is the risk of breaking something else if we fix this?
This might be as easy as replacing Encoding.ASCII for Encoding.UTF8 and nothig else.
they'll produce garbage names in the file system?
Right, even our own TarReader will read them back as garbled as I show in the snippet in the original post.
they'll produce garbage names in the file system?
Right
Then this needs to be fixed for 7.0.
This might be as easy as replacing Encoding.ASCII for Encoding.UTF8 and nothig else.
It won't be. Several code paths assume that the input and output lengths will be the same; that's a valid assumption for Encoding.ASCII but not for Encoding.UTF8.
You'll want to include chars that encode as more than 2 bytes, too, not just földër (föld€r ? )
We should have tests for every string in our API both reading and writing that use non ASCII chars -- I guess that includes entry name and link name, and extended attributes, possibly user/group although they may be limited by POSIX to a subset of ASCII. We'll need to do interop tests for each value in each format.