csharplang
 csharplang copied to clipboard
csharplang copied to clipboard
Champion: "Permit surrogate pairs and wide Unicode-escaped code points in identifiers"
- [x] Proposal added: (none needed; the C# language specification already supports this)
- [ ] Discussed in LDM
- [ ] Decision in LDM
- [ ] Finalized (done, rejected, inactive)
- [ ] Spec'ed
The C# language specification already requires that we accept Unicode letters (etc) in identifiers. But the Roslyn compiler doesn't support Unicode letters higher than U+10000 (https://github.com/dotnet/roslyn/issues/9731)(https://github.com/dotnet/roslyn/issues/13474), or those that are represented as a Unicode escape sequence for such a code point (https://github.com/dotnet/roslyn/issues/13560). We could treat it as a bug and fix it, but that fix probably needs to be tied to a language version change to prevent a backward breaking change. This championed issue is to track the fix (as a language change) in some language version.
[jcouv update:] this restriction is documented as a known/expected/explicit decision from roslyn.
@svick since only a later version of the compiler would be able to parse those identifiers, this should be tied to a lang version to not silently break code in older versions (i.e. this is an observable "bug fix")
@svick A source file that successfully compiles using language version 6 on a recent compiler should also compile using an older version of the compiler in the same language version. Similarly, APIs described in an assembly that was compiled with a recent compiler using language version 6 should be usable by an older compiler using language version 6. Both of these would be violated by permitting a newer compiler to accept identifiers that were rejected by previous compilers.
@svick https://github.com/dotnet/roslyn/blob/master/docs/compilers/CSharp/Unicode%20Version.md Unicode sometimes has breaking changes.
As a prime example: Ask Jon Skeet about the Mongolian Vowel Separator. :upside_down_face:
Since this is touching Unicode support, wouldn't it be nice if C# could support wider range of characters in identifiers? I personally don't care about emoji, but it would be nice if the following code would compile:
int Sum(int x₁, int x₂)
{
return x₁ + x₂;
}
@ghord Do you want any characters to be supported? or do you have any rule? Many languages - C#, Java, Go, Python, Elixir, etc. - support Unicode identifiers as defined in the Unicode Annex #31.
@ufcpp There are some other languages with more relaxed definitions like JavaScript and Swift (Fragment of Swift spec with ranges defined). That would be a good place to start.
@ghord Yes but... Relaxation is not necessarily good. For instance, the following code is valid in Swift. I personally don't like this identifier rule.
import Foundation
var = 2 // function apply
var = 3 // invisible times
var = 5 // invisible separator
var = 7 // invisible plus
print( * * * )
var 𝟎 = 2 // bold
var 𝟘 = 3 // double-struck
var 𝟢 = 5 // sans-serif
var 𝟬 = 7 // sans-serif bold
var 𝟶 = 11 // mono-space
print(𝟎 * 𝟘 * 𝟢 * 𝟬 * 𝟶)
prefix operator ∑ // 'N-ARY SUMMATION' (U+2211)
prefix func ∑ (array : [Int]) -> Int {
var sum : Int = 0
for item in array {
sum += item
}
return sum
}
let a = [ 1, 2, 3, 4, 5]
let Σa = 0 // 'GREEK CAPITAL LETTER SIGMA' (U+03A3) + a
print(∑a) // 15
print(Σa) // 0
@ufcpp I admit it looks confusing when you use characters like these, but it's alreay possible in current language
var а = 2; // U+0430
var a = 3; // ASCII a
var b = а + a; // 5
The thing is, nobody writes code like this. I would not consider it a strong argument against the changes.
@ghord If you'd like the definition of identifier to change, please lobby for that change in the Unicode spec rather than the C# spec. We are unlikely to depart from the Unicode spec further than we already do (we treat _ as a letter).
This championed issue is not a wish list of changes to the spec. It is about implementing what is already in the spec. If you want to propose changes to the specification, please open new issues.
This was originally tagged 'help-wanted'. I would be happy to help with this one if needed.
Since this is touching Unicode support, wouldn't it be nice if C# could support wider range of characters in identifiers? I personally don't care about emoji, but it would be nice if the following code would compile:
int Sum(int x₁, int x₂) { return x₁ + x₂; }
@ghord Like @ufcpp , I would recommend against such a relaxation for the following reasons:
-
There is a reason that Unicode recommends a specific set of characters for the starting character, and then some additional ones for continuing characters.
-
Having a standard approach to identifiers makes porting code and/or skills between platforms much easier (even if there is minor variation due to which version of Unicode is being implemented, plus customizations)
-
It seems counter to Unicode's goal of increasing standardization
-
You can already use similar characters. For example, the following code works for me in LINQPad 5:
void Main() { int Xₐ = 2; // U+2090 (subscript "a") int Xₘ = 4; // U+2098 (subscript "m") int Xⅱ = 6; // U+2171 (small Roman numeral 2) Console.WriteLine(Xₐ + Xₘ + Xⅱ); } -
I wouldn't recommend to those languages that do support such relaxations that they continue to do so (or that it was a good idea to start if that means that they cannot now stop due to people making use of it), but perhaps there is a middle-ground? SQL Server handles such things by requiring identifiers containing characters not specified by Unicode as being valid identifier characters (as of Unicode 3.2) to be delimited by either
[and'], or"(depending on yourQUOTED_IDENTIFIERsetting). Hence, the following statement is invalid:CREATE TABLE dbo.🍷 (Col1 INT);But, if delimited, then it is valid, and the following does work:
CREATE TABLE dbo.[🍷] (Col1 INT);If C# were going to be modified in any way, I would suggest something along those lines that still allows for normal identifier rules to be enforced. Of course, you cannot delimit variable names in T-SQL, so
@x₂would never work there, but we aren't talking about T-SQL ;-)
var 𝟎 = 2 // bold var 𝟘 = 3 // double-struck var 𝟢 = 5 // sans-serif var 𝟬 = 7 // sans-serif bold var 𝟶 = 11 // mono-space print(𝟎 * 𝟘 * 𝟢 * 𝟬 * 𝟶)
@ufcpp Hi there. While I do agree with your point, it should be noted that when C# starts allowing supplementary characters having the "ID_start" and "ID_continue" properties to be valid for identifiers, then the portion of your example code shown above won't be usable as a counter-point against relaxations since they are all valid "ID_continue" characters. At that time, the following will compile and execute:
void Main()
{
var a𝟎 = 2; // bold (U+1D7CE)
var a𝟘 = 3; // double-struck (U+1D7D8)
var a𝟢 = 5; // sans-serif (U+1D7E2)
var a𝟬 = 7; // sans-serif bold (U+1D7EC)
var a𝟶 = 11; // mono-space (U+1D7F6)
Console.WriteLine(a𝟎 * a𝟘 * a𝟢 * a𝟬 * a𝟶);
}
But yes, it will still be inadvisable to do such things ;-)
IMO, C# should follow Unicode® Standard Annex #31. From this stand point, var 𝟎 = 2 is disallowed but var a𝟎 = 2 should be allowed. Roslyn violates C# specification. This is just an implementation issue.
- IsIdentifierStert/PartCharacter uses
charas a parameter. It should useint(code point). CharUnicodeInfo.GetUnicodeCategorynow have an overload that acceptint(code point) but this overload doesn't exist in netstandard2.0 (current Roslyn's target)
This championed issue is not a wish list of changes to the spec. It is about implementing what is already in the spec. If you want to propose changes to the specification, please open new issues.
Hi @gafter . I would argue that supporting supplementary characters in identifiers (as much as I support that happening), is not already in the spec, thus this request is proposing a change to the spec.
Again, I fully support the intent of this request. Unfortunately, the C# specification is, and has always been, incomplete with regards to clearly delineating between BMP characters and supplementary characters. True, the spec does state that characters in certain general categories are allowed, and it does not state that either only BMP characters are allowed, or that supplementary characters are invalid. But, the spec was written with "The Unicode Standard, Version 3.0" in mind, and neither version 3.0.0 (June, 1999) nor version 3.0.1 (August, 2000) designate any supplementary characters for use in identifiers. In fact, they don't seem to assign any properties to supplementary characters. It appears that version 3.1.0 (March, 2001) is the first to incorporate supplementary characters in these properties, as well as when they switched from using "identifier part" to "ID_start" and "ID_continue".
And, that timing fits with an old list-serve thread I just found on Unicode.org, from September, 2000, wherein they discuss incorporating supplementary characters into Unicode, including terminology such as "BMP character", "supplementary character", and "surrogate code point":
-
from Asmus Freytag, 2009-09-29
I and other people who have the need to write about these characters have, with more or less encouragement from the Unicode Editorial Committee started to use the terms "Supplementary Planes", "Supplementary Characters" etc. This view has now also taken hold in WG2 and is being reflected in part 2 of ISO 10646.
Being that the C# spec is based on Unicode version 3.0.x (whether .0 or .1), it could not have included, nor intended to include, supplementary characters as valid for identifies since those characters did not exist yet.
I just submitted a PR https://github.com/dotnet/csharplang/pull/2675 to rectify the situation with the specification.
But, the spec was written with "The Unicode Standard, Version 3.0"
https://github.com/dotnet/roslyn/blob/fab7134296816fc80019c60b0f5bef7400cf23ea/docs/compilers/CSharp/Unicode%20Version.md
But, the spec was written with "The Unicode Standard, Version 3.0"
also see the comments at https://github.com/dotnet/roslyn/issues/13474#issuecomment-243858232
@ufcpp and @miloush : Yes, I am aware of those. However, none of that relates to what I am saying or suggesting. I am not referring to the current state of the compiler; I am referring to the current (and past) state of the specification. I am saying that:
-
The C# specification is wrong (incomplete / ambiguous). For example, the description of
'\\U' hex_digit hex_digit hex_digit hex_digit hex_digit hex_digit hex_digit hex_digitwas incorrect the moment it was written into the spec. It describes the original definition of UCS-4, but certainly not Unicode / UTF-32, nor what UCS-4 was constrained to only a few years later. -
A possible explanation for the lack of clarity regarding supplementary characters in the C# specification is the context in which it was being developed/written. I point out that the spec was originally written with Unicode 3.0 in mind not because that is the version number still in the document, but because it indicates which context to look at. That context is the state of Unicode circa 1999. Knowing that, when we look at the two links to the Unicode list-serve archive provided in my previous comment, we see that the name "supplementary characters" was just officially decided in late 2000, because that is when they were starting to include them in the UCD. And, that hadn't even been published yet.
It is this context that helps us understand the original intent of what we find in the C# specification today. This guides us, pretty clearly, in the understanding that
letter_character : '<A Unicode character of classes Lu, Ll, Lt, Lm, Lo, or Nl>'does not mean "any Unicode character, BMP or supplementary, of those classes" (thereby making this issue a bug fix), but instead means "any Unicode BMP character of those classes" (thereby making this issue an enhancement request).
Again, I fully support the goal of having C# (or any language) support all characters indicated by Unicode as being valid for identifiers in identifiers. I am just pointing out that "implementing what is already in the spec" does not include supplementary characters. This is why I submitted that PR to fix the spec, to reduce confusions such as this caused by the loose definitions surrounding supplementary characters.
@srutzky I disagree with your interpretation of the standard. To me it clearly says "any Unicode character of those classes", it is just at that time only BMPs existed. Technically claiming they meant to exclude surrogates isn't any more valid than claiming they meant to include them. It was clarified in the linked comments that the intent (and the only practical implementation) of the specification was to refer to the latest Unicode standard.
As far as I understand the current state of C# 6 standard addresses this issue by referring to the latest standard as per @ufcpp link.
I'd like this issue to be documented as a "known bug" and hope it to be fixed.
The ECMA standard for C# refers to the latest Unicode specification, not 3.0, and does not restrict the character set to those encodable in UTF-16 without surrogates. We intend to merge the ECMA specification with this one, so those changes will flow into this specification. Support for supplementary characters should not require any additional specification changes.
We do not expect to devote resources to this, as we have not had any actual outside users reporting that this would be helpful to them. However, we would consider a clean PR that implements this in the Roslyn compilers.
as we have not had any actual outside users reporting that this would be helpful to them.
If it's worth anything, I discovered this myself without reading about it when I was writing C# yesterday.
This would be helpful to me and I'm happy to give it a try. Do you have quick pointers to the code areas involved?
@miloush It seems that @ufcpp has been working on a fix.
https://github.com/dotnet/roslyn/compare/master...ufcpp:surrogate-pair-identifier
I'm not sure how big of a task it is, or whether it's worthwhile to offer help.
@Serentty I have not been able to make formal suggestions due to language barriers. (I'm not so fluent in English.) I'm still doing a lot of research. I need to look at the impact locations and prepare test plans like https://github.com/dotnet/roslyn/issues/28489.
https://github.com/dotnet/roslyn/compare/master...ufcpp:surrogate-pair-identifier seems to work fine to some extent
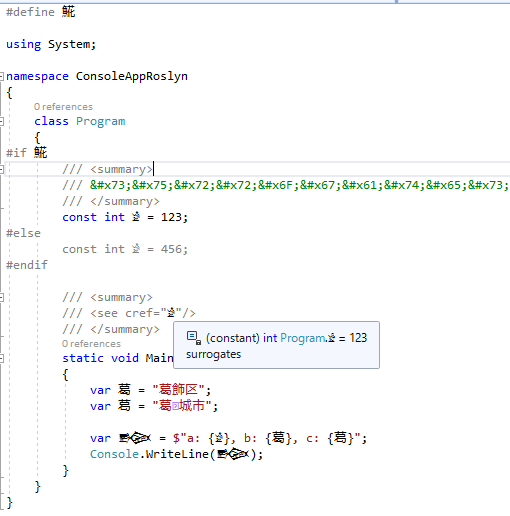
There remains some issues. I have also some open questions. I'm working on summarizing the issues and questions.
This is very exciting! The .NET situation around Unicode has gotten a lot better over the past year or so, and thanks to the efforts of people like you it's continuing to do so.