User study feedback: How does the ongoing critical infrastructure issue affect my PR?
This question came up a lot, as it's unclear to users how and if the Ongoing Critical Infrastructure issues affect their PR. We should be more clear about what those are for.
/cc @ViktorHofer @tlakollo @MichalStrehovsky @elinor-fung @radical @hoyosjs @BruceForstall @dougbu @adiaaida
I really think we are being a bit too liberal with making things "critical infrastructure issues". It would be REALLY bad if people just started to ignore this section because there's always something there that isn't relevant/actionable.
I think we should only mark things that as critical infrastructure issues if they are fully blocking more than 50% of PRs AND we can't handle it with a known issue (making sure it only showed up when it actually impacted you). Anything less and that means that most of the time they are irrelevant, and irrelevant noise in a feature specifically designed to minimize irrelevant noise is bad.
Thoughts @ulisesh, @ilyas1974, @Chrisboh, @MattGal, @AlitzelMendez, @markwilkie?
It would be REALLY bad if people just started to ignore this section because there's always something there that isn't relevant/actionable.
Some folks didn't even notice that section during the user study, even though it's at the top. Others suggested putting it at the bottom of Build Analysis because they didn't find any value in it since there wasn't anything actionable for them.
putting it at the bottom of Build Analysis because they didn't find any value in it since there wasn't anything actionable for them
That's a HUGE HUGE HUGE red flag, and means we need to take action here really quickly. We can't have a huge feature we invested in written off like that.
That was kinda my reaction when I first saw this section too. It was a lot of words that said nothing more than "Critical Infrastructure Issue". There was no way for me to tell if this thing actually affected my results or not.
Even if we severly cut back on marking things with this tag, for the things that are, it sounds like we need to be really careful with their titles, and making sure they are 100% clear with no other context (which can be tricky, given how short titles are).
yea, I think the original thinking/goal was to make it clear that something is dreadfully wrong and is affecting most builds. Perhaps it's time to determine the right "bar" for what critical means? cc/ @ilyas1974
I definitely agree that something that isn't actually affecting a high portion of builds should not be considered "critical." If there is an AzDO outage, and we create tracking known issue for that, that's a critical infrastructure issue. If one repo is getting 429s, that might be critical for that repo, and it might be technically an infra issue of sorts, but it's hard to call that "critical" for the entire org if it's not affecting more than that one repo. So the tool being smarter about what is affected would be really nice.
Rather than having a threshold for critical, I think it would be best to add some logic to see if an already reported issue its affecting my PR. There might be an issues that are affecting builds but doesnt meet the bar to be displayed as critical. I think I liked the runfoapp approach tag into the PR the current issues that match (in Runfo's case) the same failing tests. This approach could be extended in the build analysis tool to track build failures and to even look for same failure signatures, and then build a section of issues that are relevant to my current build failures
@tlakollo, that logic is already there for the "Known issues" feature, and that should be the one we prefer to use when we can. The "Critical Infrastructure Issues" is a different feature that we should only use when that logic can't be written AND it impacting 50%+ of users.
Here's some docs @tlakollo as it sounds like you're interested. https://github.com/dotnet/arcade/blob/main/Documentation/Projects/Build%20Analysis/KnownIssues.md
@tlakollo I didn't have a PR to show you with Known Issues in action, but this is what it would look like:
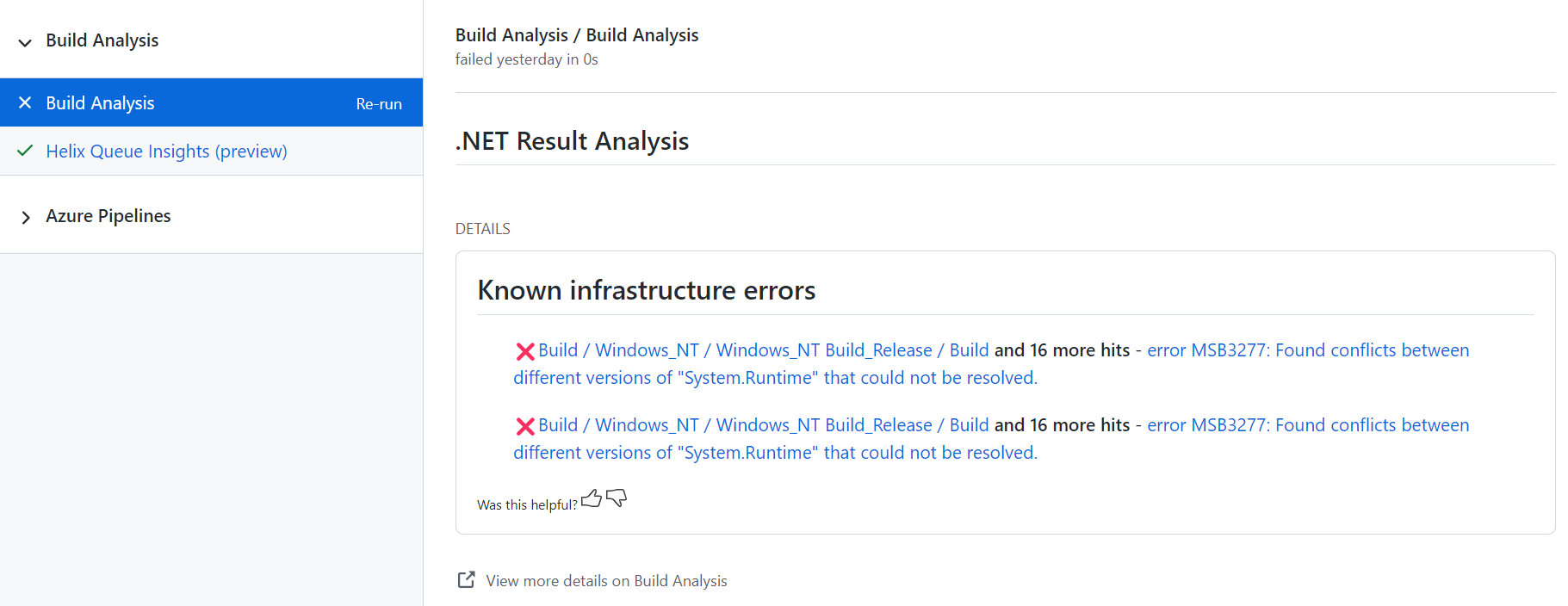
I think we definitely need to remove the word "infrastructure" there. and perhaps change it to "existing issues affecting this PR" or something. They aren't necessarily "errors", especially once tests are involved.
I think we definitely need to remove the word "infrastructure" there. and perhaps change it to "existing issues affecting this PR" or something. They aren't necessarily "errors", especially once tests are involved.
+1 to this, I think the biggest problem is labeling this a "Known infrastructure error" instead of "Errors seen on other executions" which the screen shot here is actually referring to. Once you get the word "infrastructure" involved, the person who actually broke the build is let off the hook and our team is expected to investigate and fix it.
Got sentiment feedback regarding this issue here: https://github.com/dotnet/arcade/issues/11068
I see the two features that build analysis shows as:
- Normal known issues: we know for sure your PR hit this error string from the known issue.
- Critical issue: mechanism to catch a series of problems where we don't exactly know how the error will surface in individual PRs, but they will most likely affect your builds.
For instance, during the metadata migration for the dnceng organization that is going to happen soon, we know that all builds will fail as they won't be able to restore packages, publish build artifacts, and a whole series of things we're not sure how they are going to show up exactly in your build. We can't really predict all the ways that this critical issue will surface, but there's a very good chance that your PR will fail because of it, and we don't want users to open a known issue for every modality of failure that happens that could be related to this outage.
I think having a well defined bar for what constitutes a critical infrastructure issue would solve most of the problems in this space, so that the section doesn't become a "general announcement" section that folks will learn to ignore.
As for the "infrastructure" wording, my sense is that if we're going to keep the word "infrastructure" in there, users should not be able to make that call straight away, and it should first go through a process where the eng services team has vetted the issue as being infrastructure.
Something like:
- user reports an issue, with an explanation of why they think it's infrastructure related.
- First responders investigates the report, if it's actually infra related, it's marked as such.
Updated the title on the issue to better reflect what the goal should be.
Existing documentation lives in https://dev.azure.com/dnceng/internal/_wiki/wikis/DNCEng%20Services%20Wiki/867/Critical-infrastructure-issues
The more I think about it the more I see why Ilya made this a critical issue, the day of the transition from dnceng to dnceng-public the issue meet the criteria of impacting builds in random ways. On the other hand, the issue should have been resolved or the critical label removed once the transition was done. A critical issue shouldn't be open for too long
I also don't agree that this section should be used for announcements, except in very rare circumstances (like the migration to the new AzDO instance, or the work Ricardo says is upcoming). If we DO use it for those kinds of announcements, then the issue of the title should be very clear and concise to users as to what they should expect. In this case, the title of the epic did not convey anything to the user as to how their PR may be impacted, which was a popular sentiment from users when I did the user study.
I think having a well defined bar for what constitutes a critical infrastructure issue
Proposal: Issue that caused large number (>5%) of PRs to fail in last 48 hours, and was not resolved yet.
I think having a well defined bar for what constitutes a critical infrastructure issue
Proposal: Issue that caused large number (>5%) of PRs to fail in last 48 hours, and was not resolved yet.
If it's possible to quantify the impact of a problem, this would be a bar worth investigating. However, in an example situation where AzDO is having an outage that is manifesting in multiple ways that make it difficult to quantify, we'll need to come up with a bar for those scenarios.
(Also, if a consistent error message can be identified, that should be a regular Known Issue, so that it will be used for error matching on a PR, in my opinion).
If it's possible to quantify the impact of a problem, this would be a bar worth investigating.
You do need to quantify the impact precisely. For example, it should be good enough to do a cursory look at the last 10 or 20 failed PRs and see whether they are likely impacted.
a consistent error message can be identified, that should be a regular Known Issue, so that it will be used for error matching on a PR
Yes, that is always better - if it is an option.
I don't think in general, it's unclear when something is critical. Anything that's impacting 90% of builds is going to be pretty well known by the engineering team (because there will be many, many fires going on in the FR communication channels). We have very vocal customers, so we know pretty quick when stuff isn't working.
In my head it's also unusual for something to affect, say 40% of builds. Failing in our systems tend to be more in the 5-10% (some intermittent networking/throttling problem) or 90-100% buckets (there is some full outage in a system we depend on)
Need to have discussion in Triage about either 1) what the bar is for an issue to be considered a critical issue and document that guidance for future use, or 2) find an appropriate place for this issue to live to be handled.
Added criteria to: https://dev.azure.com/dnceng/internal/_wiki/wikis/DNCEng%20Services%20Wiki/867/Critical-infrastructure-issues