plot_tree labels are reversed
I believe the plot_tree function is reversing labels when displayed.
Here is my environment :
Python 3.9.5
xgboost==1.6.1
pandas==1.2.1
matplotlib==3.5.2
Below is a small script to show the reversed labels. The script is building a simple model to predict the boolean : "Is is monday ?" and end up with a perfect model but the graph is reversed.
From the script, we've got :
| day | is it monday ? | predictions | |
|---|---|---|---|
| 0 | 0:1 | 1 | 1 |
| 1 | 0:1 | 1 | 1 |
| 2 | 0:1 | 1 | 1 |
| 3 | 1:1 | 0 | 0 |
| 4 | 2:1 | 0 | 0 |
| 5 | 3:1 | 0 | 0 |
| 6 | 4:1 | 0 | 0 |
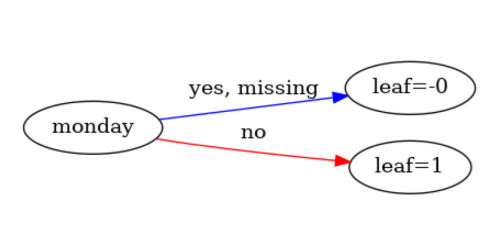
And the reversed graph :
## For the script to work, please create these 3 files in the same folder than the code
# train.txt
# 1 0:1
# 1 0:1
# 1 0:1
# 0 1:1
# 0 2:1
# 0 3:1
# 0 4:1
# test.txt
# -> same as train.txt
# mapping.txt
# 0 monday i
# 1 tuesday i
# 2 wednesday i
# 3 thursday i
# 4 friday i
import xgboost
import pandas as pd
import matplotlib.pyplot as plt
# Train a simple tree
train_dataset = xgboost.DMatrix("train.txt")
test_dataset = xgboost.DMatrix("test.txt")
params = {
"eta": 1,
"objective": "reg:squarederror",
"lambda": 0.0,
"base_score": 0.0,
"nthread": 1,
}
num_tree = 1
model = xgboost.train(params, train_dataset, num_tree, evals=[(test_dataset, "test")])
# The tree is doing perfectly well
print("\nDataset + predictions")
print("---------------------")
df = pd.read_csv("test.txt", sep=" ", names=["is it monday ?", "day"])
df["predictions"] = model.predict(test_dataset)
print(df[["day", "is it monday ?", "predictions"]])
# The dump is consistent too
mapping = "mapping.txt"
model.dump_model("my_model_dump", mapping)
print("\nMy model to text")
print("-----------------")
with open("my_model_dump", "r") as my_model_file:
for line in my_model_file:
print(line)
# However the plot_tree is reversed
fig, ax = plt.subplots(figsize=(8, 6))
ax = xgboost.plot_tree(model, rankdir="LR", num_trees=0, ax=ax, fmap=mapping)
plt.show()
Hi, Let me give more details
About the dataset :
| day | is it monday ? | predictions |
|---|---|---|
| 0 | 1 | 1 |
| 0 | 1 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 0 |
| 2 | 0 | 0 |
| 3 | 0 | 0 |
| 4 | 0 | 0 |
Captions :
- day is one feature (where 0 = monday, 1 = tuesday, ...)
- is it monday ? is the target
- predictions is the predictions from Xgboost
The model is really simple :
booster[0]:
0:[monday] yes=2,no=1
1:leaf=-0
2:leaf=1
In a nutshell : if day = 0 then we're monday else no.
However the graph shows the opposite :

We have : If monday (day = 0) then leaf = 0 (we're not monday) else leaf = 1 (we're monday)
Instead we should have : If monday (day = 0) then leaf = 1 (we're monday) else leaf = 0 (we're not monday)
Seems like the model dump is reversed instead of the plot being reversed. Marked as a bug, will investigate tomorrow.
Thanks for your investigation. Just wanted to say, I strongly believe it is the plot that is wrong since the model dump is consistent with the predictions results : when monday (day = 0), model predicts 1.
Let me know if I can help.
Alright, I forgot the subtleties around specifying int and indicator in mapping.txt. The meaning of "yes" and "no" seems to be suggesting the answer to the query instead of the split condition of tree node. I will need to take a look into the R implementation as well.
Confirming this bug. The problem may lie in the behavior of get_dump with dump_format='dot', which seems to give incorrect output, whereas get_dump with dump_format='json' gives the correct behavior. It may be a result of mixing up the meaning of left and right in src/tree/tree_model.cc, around line 711 or 712, where the usual tree convention (that right is higher) may not be matching with the visualization convention (where right may not be higher).