dgl
 dgl copied to clipboard
dgl copied to clipboard
[Feature][Performance][GPU] MultiGPUNodeDataLoader
Description
Adds support for storing graph features partitioned in GPU memory. This doesn't implement new functionality, but rather better exposes that which was already implemented in the NCCL based NodeEmbedding.
(Below is out of date--but remains roughly true) This enables running GraphSage on ogbn-papers100M with the node features entirely in GPU memory, on 8x 16GB GPUs (such as a P3 instance). This has a very large performance impact as not only do node features not have to pass through the limited PCIe bandwidth (when NVLINK is available), but the CPU no longer needs to sped time slicing them.
Loading data can dominate the runtime when running with sufficiently large batch sizes so as to make the GPU computation efficient. Below is graphsage running with a batch size of 4096:
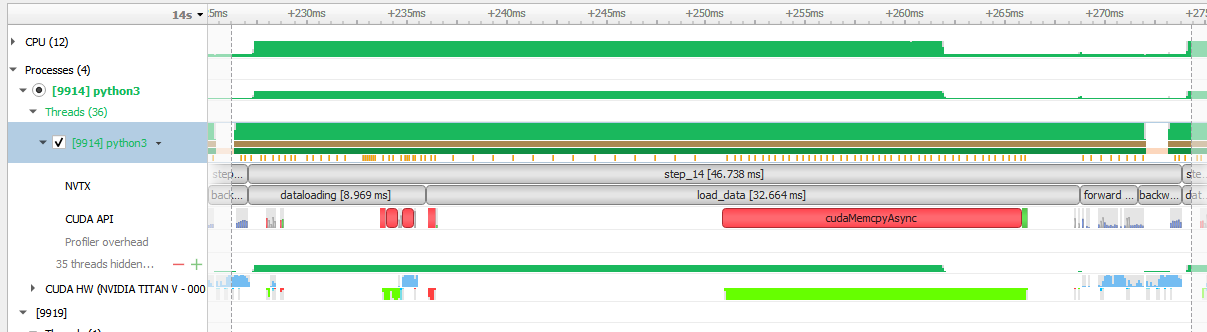 Here, performing a slice on the features, and copying the data across PCIe is taking up 70% of the runtime.
Here, performing a slice on the features, and copying the data across PCIe is taking up 70% of the runtime.
While currently replicating all features on GPUs is possible, and solves this problem well for small graphs, it is not sufficient when the graph is too large for a single GPU (as is the case for ogbn-papers).
So in the case of ogbn-papers100M, I observed a ~4x reduction in epoch time when splitting the data across 8 GPUs connected with NVLINK, with this PR:
$ OMP_NUM_THREADS=10 python3 train_sampling_multi_gpu.py --dataset ogbn-papers100M --num-epochs 25 --eval-every 25 --num-hidden 1024 --batch-size=4096 --fan-out 30,30 --gpu 0,1,2,3,4,5,6,7 --num-worker 0 --data-cpu
load ogbn-papers100M
finish loading ogbn-papers100M
finish constructing ogbn-papers100M
Using backend: pytorch
/usr/local/lib/python3.6/dist-packages/dgl-0.7.0-py3.6-linux-x86_64.egg/dgl/base.py:45: DGLWarning: DEPRECATED: DGLGraph and DGLHeteroGraph have been merged in v0.5.
dgl.as_heterograph will do nothing and can be removed safely in all cases.
return warnings.warn(message, category=category, stacklevel=1)
Epoch 00000 | Step 00000 | Loss 5.2617 | Train Acc 0.0054 | Speed (samples/sec) nan | GPU 2205.7 MB
Epoch 00000 | Step 00020 | Loss 2.0258 | Train Acc 0.4399 | Speed (samples/sec) 55115.1795 | GPU 2244.8 MB
Epoch Time(s): 29.1478
Epoch 00001 | Step 00000 | Loss 1.5826 | Train Acc 0.5283 | Speed (samples/sec) 53799.2058 | GPU 2244.8 MB
Epoch 00001 | Step 00020 | Loss 1.4502 | Train Acc 0.5667 | Speed (samples/sec) 55876.3346 | GPU 2244.8 MB
Epoch Time(s): 24.8195
...
Epoch 00024 | Step 00000 | Loss 1.0210 | Train Acc 0.6714 | Speed (samples/sec) 65573.5708 | GPU 2263.7 MB
Epoch 00024 | Step 00020 | Loss 1.0429 | Train Acc 0.6567 | Speed (samples/sec) 65522.1282 | GPU 2263.7 MB
Epoch Time(s): 24.0144
Avg epoch time: 24.40067551136017
$ OMP_NUM_THREADS=10 python3 train_sampling_multi_gpu.py --dataset ogbn-papers100M --num-epochs 25 --eval-every 25 --num-hidden 1024 --batch-size=4096 --fan-out 30,30 --gpu 0,1,2,3,4,5,6,7 --num-worker 0
Epoch 00000 | Step 00000 | Loss 5.2728 | Train Acc 0.0054 | Speed (samples/sec) nan | GPU 14215.7 MB
Epoch 00000 | Step 00020 | Loss 2.0104 | Train Acc 0.4377 | Speed (samples/sec) 832442.6948 | GPU 14215.7 MB
Epoch Time(s): 6.4573
Epoch 00001 | Step 00000 | Loss 1.5918 | Train Acc 0.5300 | Speed (samples/sec) 958284.6524 | GPU 14215.7 MB
Epoch 00001 | Step 00020 | Loss 1.4402 | Train Acc 0.5659 | Speed (samples/sec) 953889.6586 | GPU 14215.7 MB
Epoch Time(s): 4.8995
...
Epoch 00024 | Step 00000 | Loss 1.0228 | Train Acc 0.6660 | Speed (samples/sec) 816982.4967 | GPU 14215.7 MB
Epoch 00024 | Step 00020 | Loss 1.0339 | Train Acc 0.6589 | Speed (samples/sec) 814339.5615 | GPU 14215.7 MB
Epoch Time(s): 6.3077
Avg epoch time: 6.580887830257415
Checklist
Please feel free to remove inapplicable items for your PR.
- [x] The PR title starts with [$CATEGORY] (such as [NN], [Model], [Doc], [Feature]])
- [x] Changes are complete (i.e. I finished coding on this PR)
- [x] All changes have test coverage
- [x] Code is well-documented
- [x] To the my best knowledge, examples are either not affected by this change, or have been fixed to be compatible with this change
Changes
This adds a MultiGPUFeatureGraphWrapper class, which can be used to wrap a DGLGraph object, and automatically switches the feature storage to be striped across the available GPUs.
To trigger regression tests:
@dgl-bot run [instance-type] [which tests] [compare-with-branch]; For example:@dgl-bot run g4dn.4xlarge all dmlc/masteror@dgl-bot run c5.9xlarge kernel,api dmlc/master
Super cool!
In discussion, two use cases came up:
-
Including edge features -- seemingly more of a docs issue?
-
Interop with cudf/dask-cudf, where etl/cleaning is on-gpu, and we need to do some sort of dlpack call: https://docs.rapids.ai/api/cudf/stable/10min-cudf-cupy.html#Converting-a-cuDF-DataFrame-to-a-CuPy-Array
Hi @nv-dlasalle, Was your test result that "Avg epoch time: 6.580887830257415" got on DGX-A100?
Hi @nv-dlasalle, Was your test result that "Avg epoch time: 6.580887830257415" got on DGX-A100?
This was on a DGX-V100, but this PR has changed quite a bit since then (using the dataloader to load all node and edge features as opposed to only explicitly loading the 'features'), so the actual performance may vary somewhat from that now.
@nv-dlasalle I changed this PR to draft as it perhaps needs some major refactoring. Also, this feature could be a perfect example to showcase the design of GraphStorage and FeatureStorage but may need to come after a formal specification of the components (see feature request #4295 ). If you think a new PR will probably be created in the future, you could also close this. Thanks for the great effort!