Donghyun Kim
[paper](https://arxiv.org/abs/2106.01548) NTK 도 찾아보게 만들고... 수학공부 다시 시작하게 만들어 준 고마운 논문. augmentation 이나 pretraining 없는 조건에서는, SAM 이 VIT 나 MLP-Mixer 에 굉장히 잘 적용되고, resnet 을 이기더라.. 하는...
[paper](https://arxiv.org/pdf/2110.04369.pdf) maximum eigenvalue of the loss Hessian == λ_1 이라 놓자. 마찬가지로, k 개의 loss Hessian 이 있다고 할 때, minimum eigenvalue of the loss Hessian == λ_k `λ_1 <...
현재 LLM 들은 학습이 덜 되었다 !! Gopher 모델을 주된 비교군으로 놓았음. Gopher 에서 4배만큼 parameter 를 줄이고, 4배만큼 training 데이터를 늘렸더니, SOTA 를 찍더라. [paper](https://arxiv.org/pdf/2203.15556.pdf) 아래 그림에서 FLOPs 는...
[paper](https://arxiv.org/pdf/2203.06717.pdf) [code - MegEngine](https://github.com/megvii-research/RepLKNet) [code - pytorch](https://github.com/DingXiaoH/RepLKNet-pytorch) 개인적으로 좋아하는 MEGVII 의 Rep~ style 연구 31x31 large kernel 을 활용하여 좋은 성능을 이끌어낸다. ERF 결과  # RepLKNet ## Custom Kernel...
[paper](https://arxiv.org/pdf/2204.02311.pdf) [blog](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html) 6144 TPU v4 chip 을 이용해 540B GPT-like 모델 학습 Pathways system 사용 (#115) paper 에서 주로 볼 내용 1. Efficient Scaling : _Pathways system 을 어떻게 활용하였는가_...
[paper](https://arxiv.org/abs/2203.12533) TPU들에 대해 어떻게 분산 처리를 할 것인가 파이토치 같은 경우 각 GPU마다 같은 프로그램을 띄워서 필요할 때 각 프로그램이 collective operation을 수행하는 방식. TF v1 같은 경우는 하나의 프로그램에서...

# prompt Calibrate Before Use: Improving Few-Shot Performance of Language Models (https://arxiv.org/abs/2102.09690) p-tuning (https://arxiv.org/abs/2104.08691) Do Prompt-Based Models Really Understand the Meaning of their Prompts? (https://arxiv.org/abs/2109.01247) An Empirical Study on Few-shot...
`rosinality`'s comment ``` mlp with gating으로 lm 학습하기 moe 기반의 sparse 모델, 더 높은 성능을 더 적은 연산량으로 달성 autoregressive lm을 all mlp로 태클 autoregressive이기 때문에 moe routing에 이후 토큰...
bai 붙은 사람들은 다 OCR을 잘 하는 걸까? (~xiang bai 센세에 이어..~)  OCR task 를 위한 pretraining strategy 제안. [paper](https://arxiv.org/pdf/2203.03911.pdf) # INTRO 3개의 pipeline 을 그림으로 표현 1. OCR...
아 ㅋㅋ relu 가 빠르다고 ㅋㅋ  [paper](https://arxiv.org/pdf/2202.08791.pdf) ## self-attention A == self attention function attention output 은 다음과 같이 정의된다. 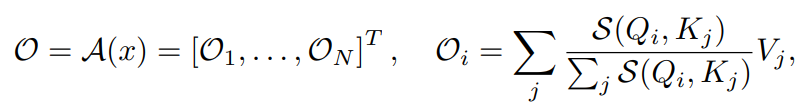 보통 S 는 다음과 같이 정의된다.  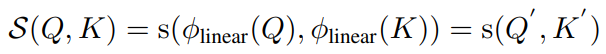...