Donghyun Kim
## CVPR 2020 ### Detection [ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network](https://arxiv.org/abs/2002.10200) ### Recognition ### E2E ### Others ##### Change Log [20/04/02] Made Issue [20/04/02] add ```ABCNet```(Detection)
S4 ( #52 ) 의 시초. HiPPO ==> LSSL ( #51 ) ==> S4 ( #52 ) 모두 1저자 작품. 수식이 워낙 어려워서 컨셉 위주로만 이해해 보려 한다. [paper](https://arxiv.org/pdf/2008.07669.pdf) [code](https://github.com/HazyResearch/hippo-code)...
RESTART

GPT-4 라는 지금까지의 판도를 뒤집을 만한, 거대한 물결이 왔다. OpenAI 는 whisper 도 있겠다, 음성 input output 이 붙는 건 시간문제라 생각한다. 다양한 시각들이 있다. 알파고 때보다 더 큰 변곡점이...
[paper](https://arxiv.org/abs/2110.09348) [code](https://github.com/facebookresearch/directclr) Contrastive Learning (CL) 에서 Dimensional Collapse (DC) 발생. non-CL method 들은 상대적으로 DC 가 덜 발생. 기존 CL 에선 nagtive sample pair 들을 이용해 DC 를 막음. 근데,...
[paper](https://arxiv.org/pdf/2104.08691.pdf) [code](https://github.com/google-research/prompt-tuning) [code2](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k) T5에 prompt tuning 했더니 GPT3 의 few-shot prompt design 보다 좋더라  파란색은 GPT-3 빨강, 주황, 초록은 T5 초록은 추가로, 모든 task에 대해 single frozen model을 reuse...
CCA가 다변수 상황에서 similarity 를 측정할 수 있지만, invertible linear transform 에 invariant 하기 때문에 data-point 의 수보다 더 높은 차원의 representation 에서는 잘 동작하지 못함. CKA (Centered Kernel Alignment)...
[paper](https://arxiv.org/pdf/2203.15380.pdf) [unofficial code - lucidrains](https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/sep_vit.py) 말 그대로 attention 을 효율적으로 다루는 논문. vit 에 적용해서 swin 보다 효율적인 것을 주장. 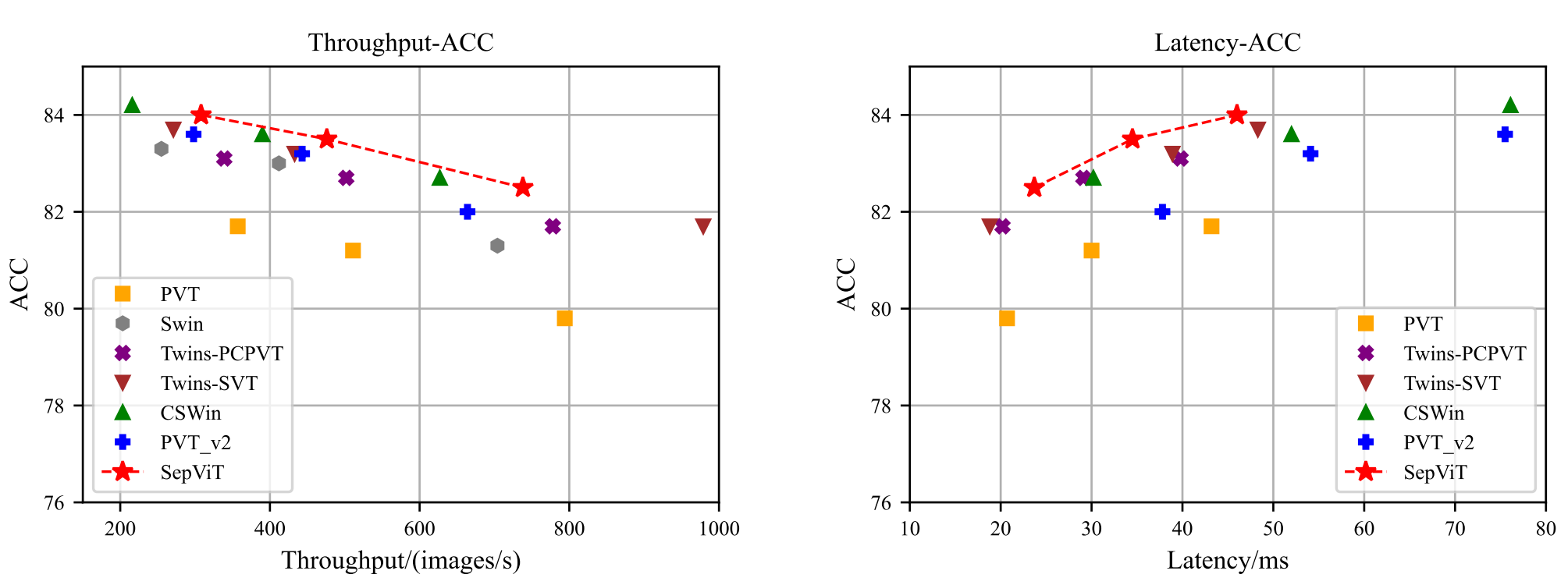 ## SepViT  간단하다. 말 그대로 depthwise 하게 attention...
[paper](https://arxiv.org/pdf/2205.09579.pdf) TeraFLOPs TeraParams 설명은 건너뛴다. ## TRT-ViT 4개의 rule 을 실험적으로 찾아내며, 아키텍처를 고름 1. transformer block 은 마지막 stage 에 위치하는 게 가성비가 좋다 (널리 알려진 사실) 2. 앞쪽...
[v1 paper](https://arxiv.org/pdf/2110.02178.pdf) [v2 paper](https://arxiv.org/pdf/2206.02680.pdf) [v3 paper](https://arxiv.org/pdf/2209.15159.pdf) [v1, v2 code](https://github.com/apple/ml-cvnets) [v3 code](https://github.com/micronDLA/MobileViTv3) 재미있게도 v3는 저자 소속이 다르다. 합의는 된 걸까 ㅋㅋㅋ v1 ==> ICLR 22, apple 논문 v2 ==> v1과 동저자,...
[paper](https://arxiv.org/pdf/2206.04920.pdf) ASAM (#128) 은 다음과 같은 문제가 있다고 한다. ``` However, this approach to determining the flatness ellipsoid of interest is heuristic and might severely degrade the neighborhood structure. ```...