[55] Lite Vision Transformer with Enhanced Self-Attention (LVT, with CSA. Conv-Self-Attn)
Convolutional Self-Attention 제안 코드는 업로드 예정이라고 함.
Lite Vision Transformer
convolution 을 단순히 Attention 과 결합하는 게 아니라
- LVT 의 첫 stage에서 local-self attention 3x3 수행 => low-level feature
- Recursive Atrous Self-Attention (RASA) 제안 => High-level feature
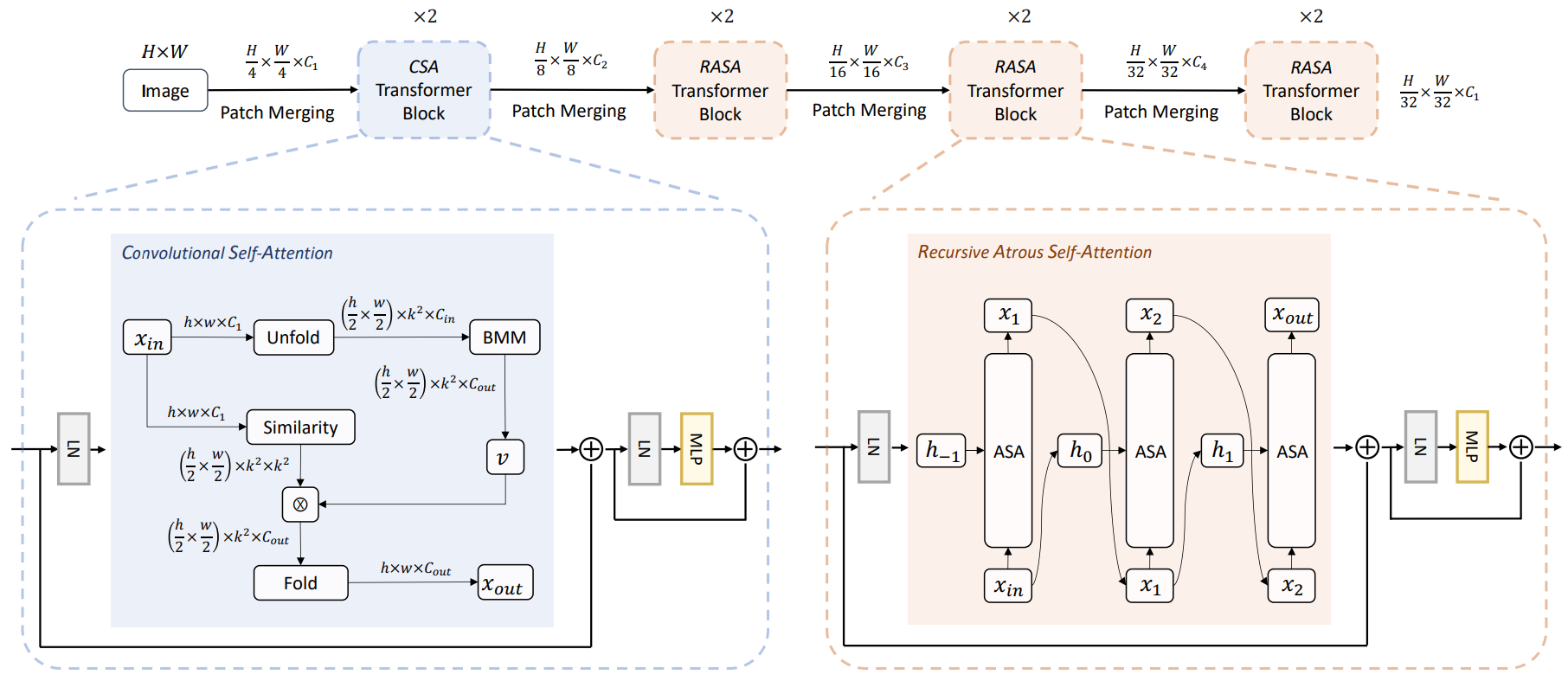 진짜 Attention 만 다 바꿔버린 구조.
진짜 Attention 만 다 바꿔버린 구조.
Convolutional Self-Attention
정말 예상하는 대로 작동함
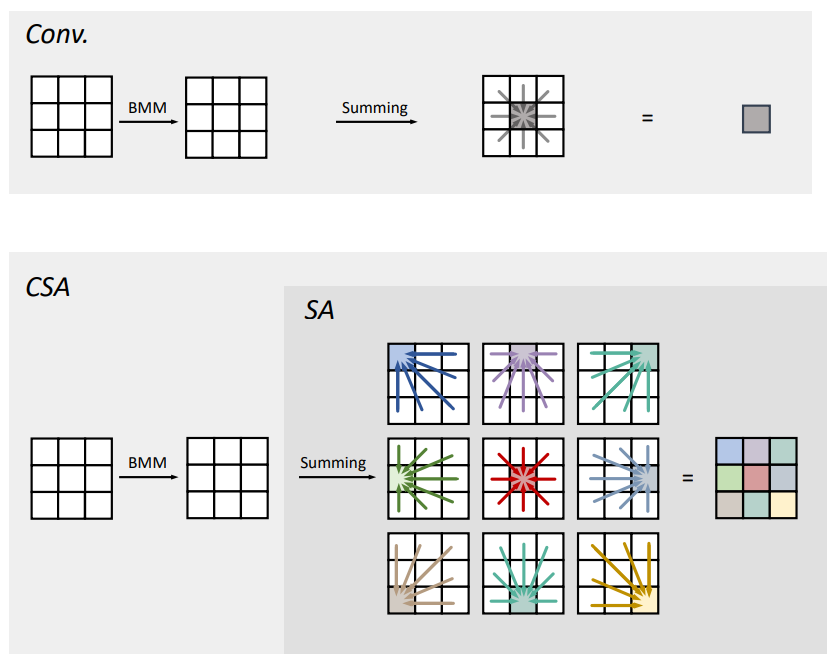
conv 연산을 그냥 attention 으로만 대체해서 sliding window 하는 작업.
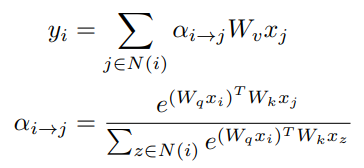 그니까,, BMM 까지는 해서 weight 곱한 값을 구해 놓고,
거기에 window 한정, local self-attention 을 수행하는 것임.
window-step 을 1로 두면 중복연산이 많이 발생하니까, BMM 으로 intermediate tensor 캐싱해두고 활용하는 방식으로 구현되었을 것으로 보임.
그니까,, BMM 까지는 해서 weight 곱한 값을 구해 놓고,
거기에 window 한정, local self-attention 을 수행하는 것임.
window-step 을 1로 두면 중복연산이 많이 발생하니까, BMM 으로 intermediate tensor 캐싱해두고 활용하는 방식으로 구현되었을 것으로 보임.
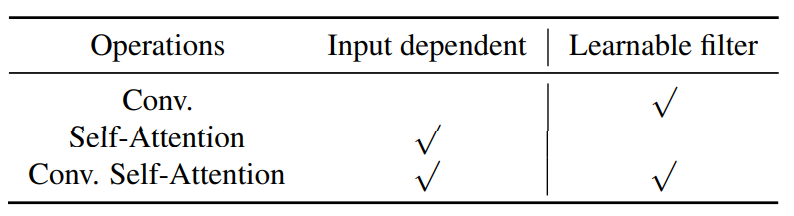
굳이 operation별 특징을 정리하면, 다음과 같음.
이제는 main figure의 local-self attention을 보면 이해가 된다. main figure 의 Unfold(im2col), Fold(col2im) 연산은 각각 stride 2를 갖고 있어서 first stage 에서 featuremap 크기가 줄어든다. BMM 은 그냥 conv 라고 생각하면 된다. (그니까, Unfold+BMM 묶어서 stride 2 conv라고 생각하면 이해가 편할 거다.)
Recursive Atrous Self-Attention
이게 좀 특이한데, mobile 은 parameter 가 많이 못들어가니까, computation을 좀 늘리더라도 최대한 high-level feature를 뽑고 싶었다고 한다.
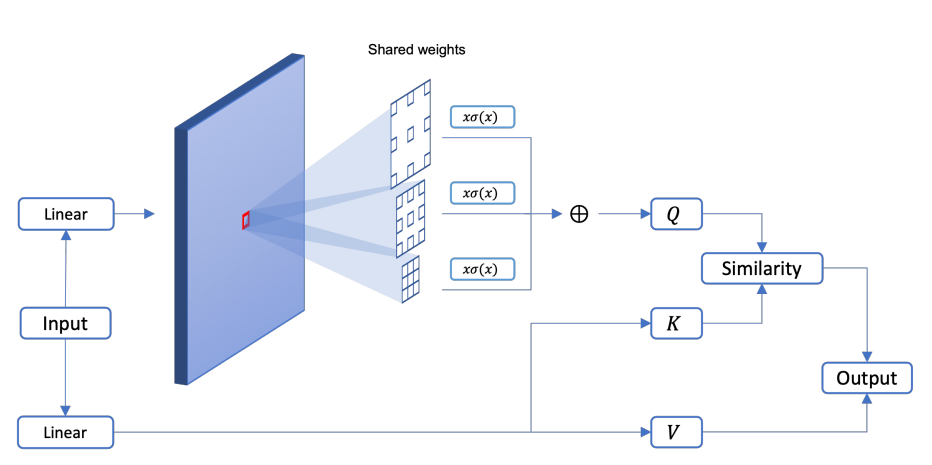
ASA 부터 이해하면 되는데,
1x1 conv 태우고 나서
dilation rate (1,3,5) conv 를 각각 태운다.
이걸 전부 summation 하면 Query 가 나온다.
key, value 를 위해서는 또다른 1x1 conv를 태운다.
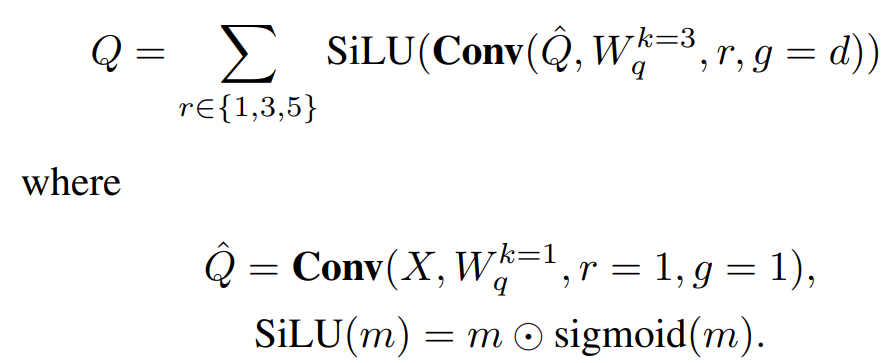
여기까지가 ASA 이고 RASA 는 main figure 를 참조하면 되겠다.
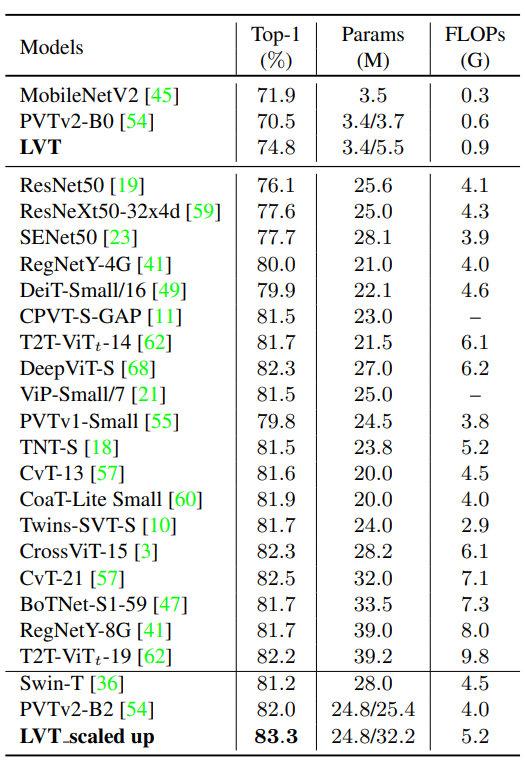
Results
Flop 은 약간 더 높고, 성능이 꽤 오른다. CPU 속도와 FLOPS 수가 보통 비례하는 것을 감안하면 훌륭한 결과.
ImageNet
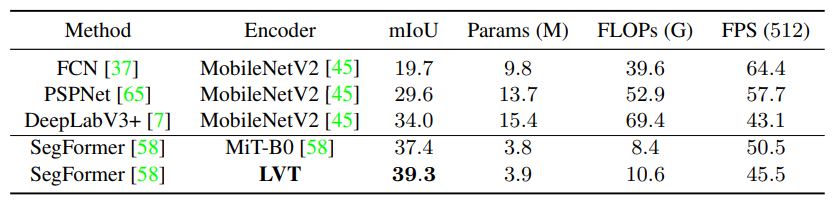
ADE-20K
FPS 는 on-device에서 512 inference 하면서 측정.
COCO Panoptic Segmentation
