1day_1paper
 1day_1paper copied to clipboard
1day_1paper copied to clipboard
Published
20 hours ago •
 dhkim0225
dhkim0225
[102] TRT-ViT: TensorRT-oriented Vision Transformer
TeraFLOPs TeraParams 설명은 건너뛴다.
TRT-ViT
4개의 rule 을 실험적으로 찾아내며, 아키텍처를 고름
- transformer block 은 마지막 stage 에 위치하는 게 가성비가 좋다 (널리 알려진 사실)
- 앞쪽 stage 는 얕아도 된다.

- transformer block 보다는, transformer + bottleneck 을 혼합시킨게 더 가성비가 좋다
- global 을 먼저 보고 local 을 보는게 더 효과적이더라

이게 끝이다 ㅋㅋ
아래 표에서 볼 수 있듯이 (C) block이 효과적이었다.

detail 한 아키텍처는 다음과 같다

Results
ImageNet
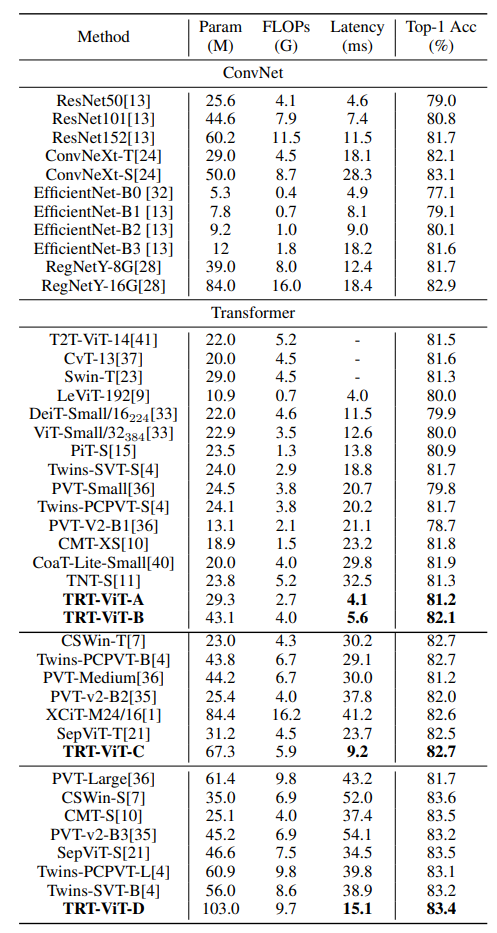
Setttings
- Swin setting (https://github.com/microsoft/Swin-Transformer/blob/d19503d7fbed704792a5e5a3a5ee36f9357d26c1/config.py)
- GPU: V100 * 8
- epochs: 300
- batch-size: 1024
- resolution: 224x224
- gradient clipping: max norm 1
- Augmentation
- RandAugment:
rand-m9-mstd0.5-inc1 - mixup 은 0.5 확률로 둘 중 하나 선택
- Mixup: alpha 0.8
- Cutmix: alpha 1.0
- random erasing: 0.25
- stochastic depth: 0.1 (DeiT 스럽게 약간 변형)
- repeated augmentation, EMA 2개는 사용 안했음 (Swin 기준 성능에 별 영향 없었음)
- RandAugment:
- optimizer
- AdamW
- weight deacy: 0.05
- warmup: 30 epoch
- lr
- 0.001
- cosine decay
Ablations

ADE 20K

COCO
