1day_1paper
 1day_1paper copied to clipboard
1day_1paper copied to clipboard
Published
20 hours ago •
 dhkim0225
dhkim0225
[101] SepViT: Separable Vision Transformer
paper unofficial code - lucidrains
말 그대로 attention 을 효율적으로 다루는 논문.
vit 에 적용해서 swin 보다 효율적인 것을 주장.
SepViT
 간단하다. 말 그대로 depthwise 하게 attention 을 먼저 해주고, channel 별 중요도를 학습시켜서 attention 효율화를 수행한다.
제안하는 방식을 DSSA (Depthwise Seperable Self Attention) 이라 부른다.
DSSA = DSA (Depthwise Self Attn) + PWA (PointWise Attn) 이다.
간단하다. 말 그대로 depthwise 하게 attention 을 먼저 해주고, channel 별 중요도를 학습시켜서 attention 효율화를 수행한다.
제안하는 방식을 DSSA (Depthwise Seperable Self Attention) 이라 부른다.
DSSA = DSA (Depthwise Self Attn) + PWA (PointWise Attn) 이다.

win_tokens 는 학습 가능한 token 들이다. 요 녀석들을 learnable 하게 만들고 channel 별 중요도를 뽑아낸다는 개념.
Grouping
depthwise attention를 더 효율적으로 수행하기 위해서 window 를 설정하고 local 하게 살펴보게 된다. 근데, window 를 확 키워버리는게 생각보다 성능이 괜찮다. (물론 속도는 느려진다) 해당 방식을 GSA (Grouped Self Attention) 이라 한다.
아래 그림을 보면 더 이해가 잘 간다.
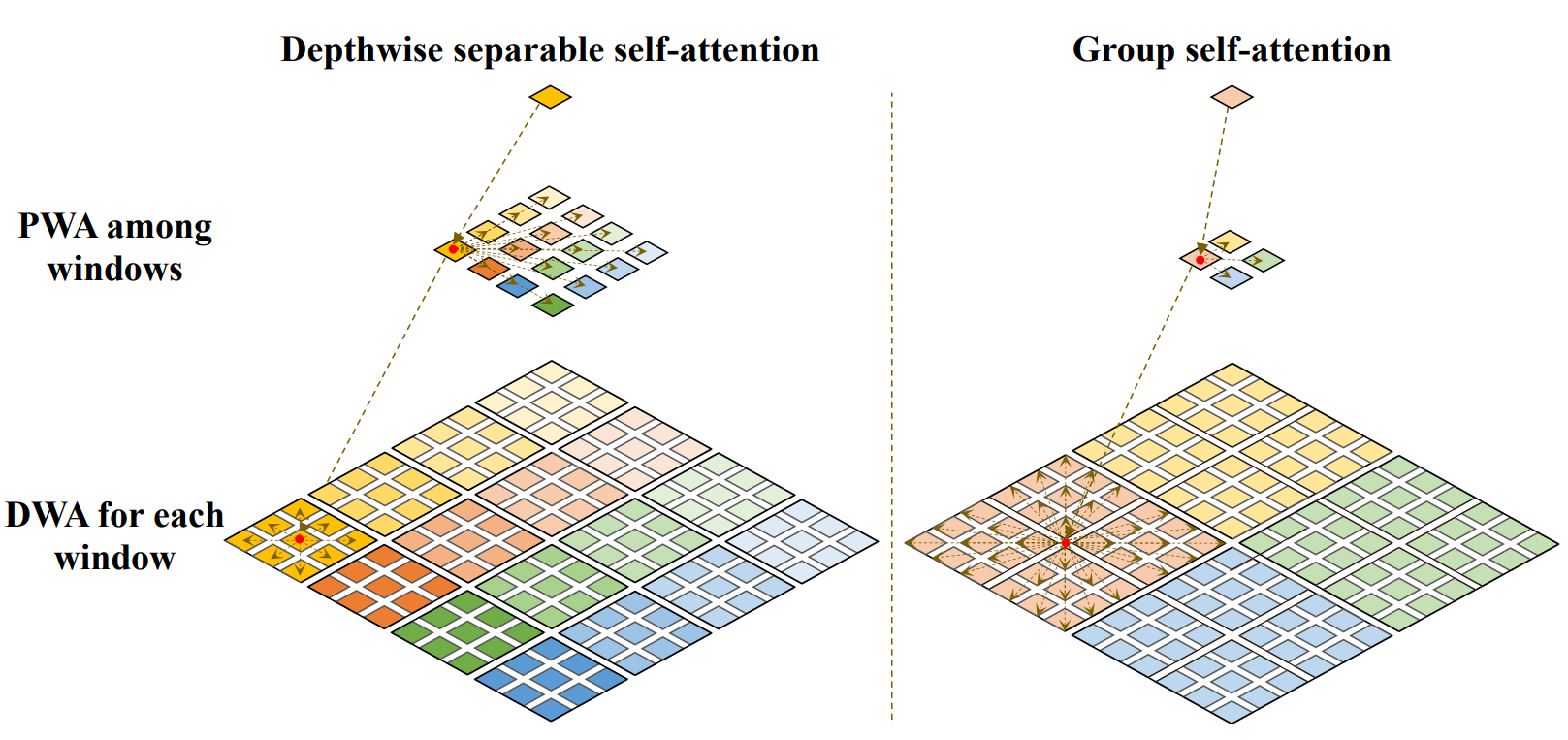
GSA = DSA + PWA 인건 똑같은데, window size 만 차이가 있는 것으로 보인다. (워딩이 굉장히 헷갈린다.)
- DSSA window size 는 7x7
- GSA window size 는 14x14
이라고 한다.

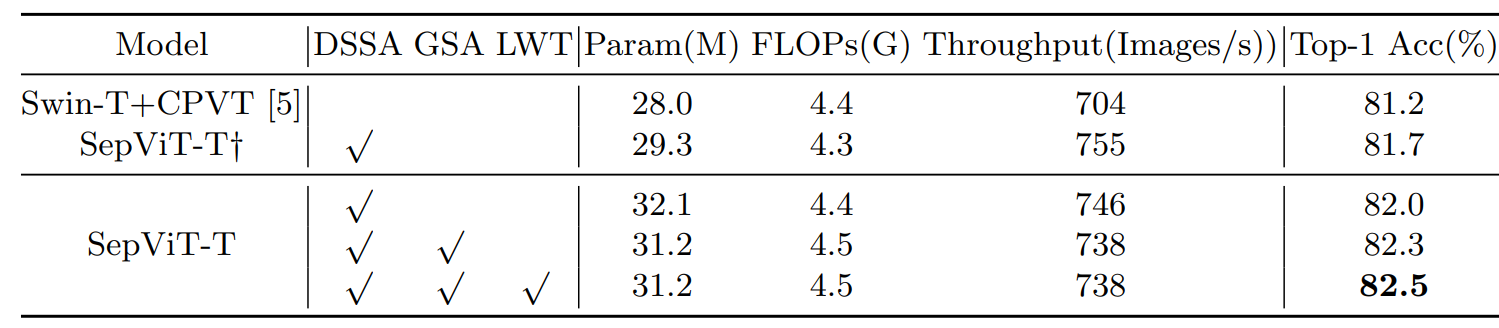
Results
Ablations
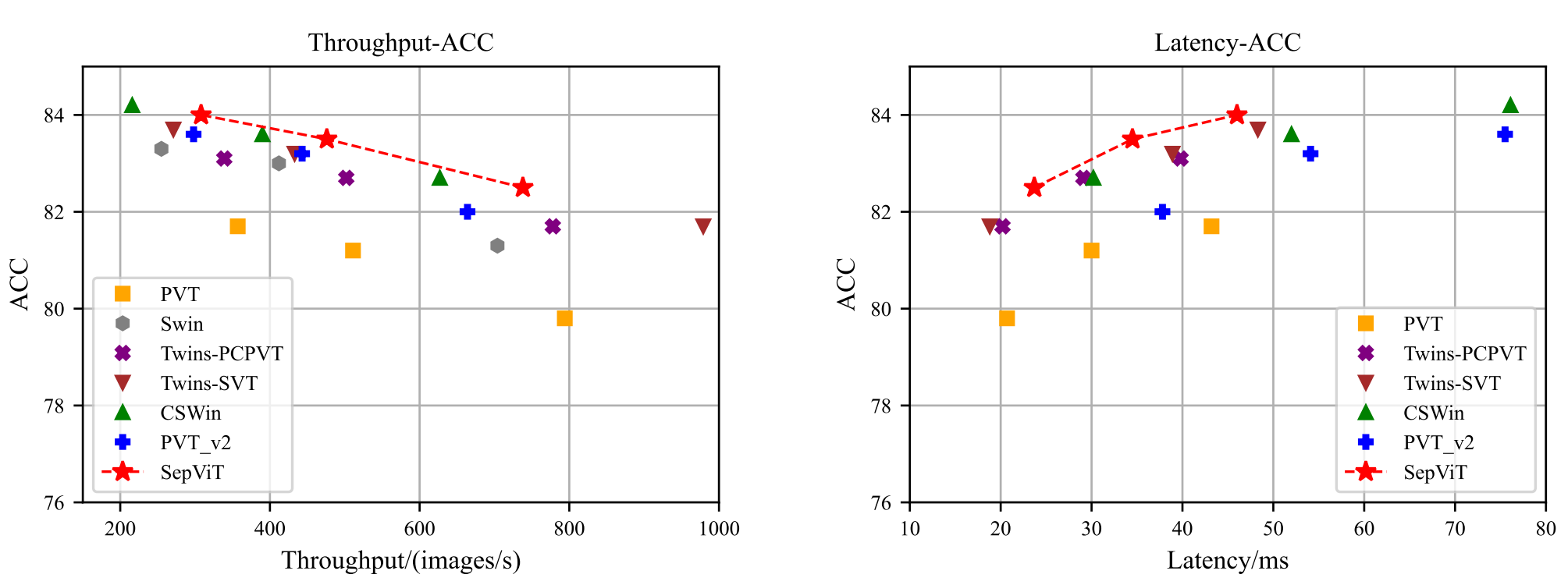
Throughput 말고 latency도 궁금한데 흠..
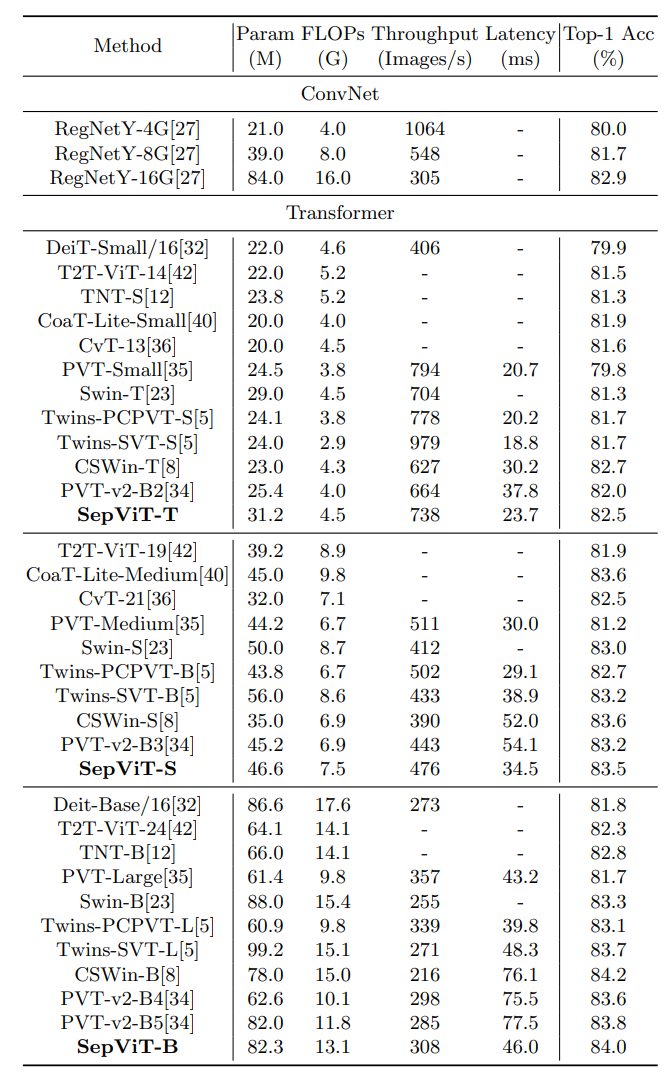
ImageNet (classification)
latency 는 T4 + TensorRT + 8 batch 로 쟀다.
Settings
- Swin setting (https://github.com/microsoft/Swin-Transformer/blob/d19503d7fbed704792a5e5a3a5ee36f9357d26c1/config.py)
- GPU: V100 * 8
- epochs: 300
- batch-size: 1024
- resolution: 224x224
- gradient clipping: max norm 1
- Augmentation
- RandAugment:
rand-m9-mstd0.5-inc1 - mixup 은 0.5 확률로 둘 중 하나 선택
- Mixup: alpha 0.8
- Cutmix: alpha 1.0
- random erasing: 0.25
- stochastic depth: 0.2, 0.3, 0.5
- repeated augmentation, EMA 2개는 사용 안했음 (Swin 기준 성능에 별 영향 없었음)
- RandAugment:
- optimizer
- AdamW
- weight deacy
- SepViT-B: 0.1
- SepViT-S/T: 0.05
- warmup
- SepViT-B: 20epoch
- SepViT-S/T: 5epoch
- lr
- 0.001
- cosine decay
- stochastic-depth aug ratio
- 학습하면서 점점 증가시킴
- SepViT-B: 0.5
- SepViT-S: 0.3
- SepViT-T: 0.2
ADE20K (semantic segmentation)

COCO (detection & instance segmentation)
