RequestError: RequestError(400, 'mapper_parsing_exception', 'The number of dimensions for field [embedding] should be in the range [1, 2048] but was [12288]')
Hello @julian-risch ,
I hope you are doing well, my friend. I wanted to build a system using the New OpenAI pipeline with ElasticsearchDocumentStore, but I faced this error;
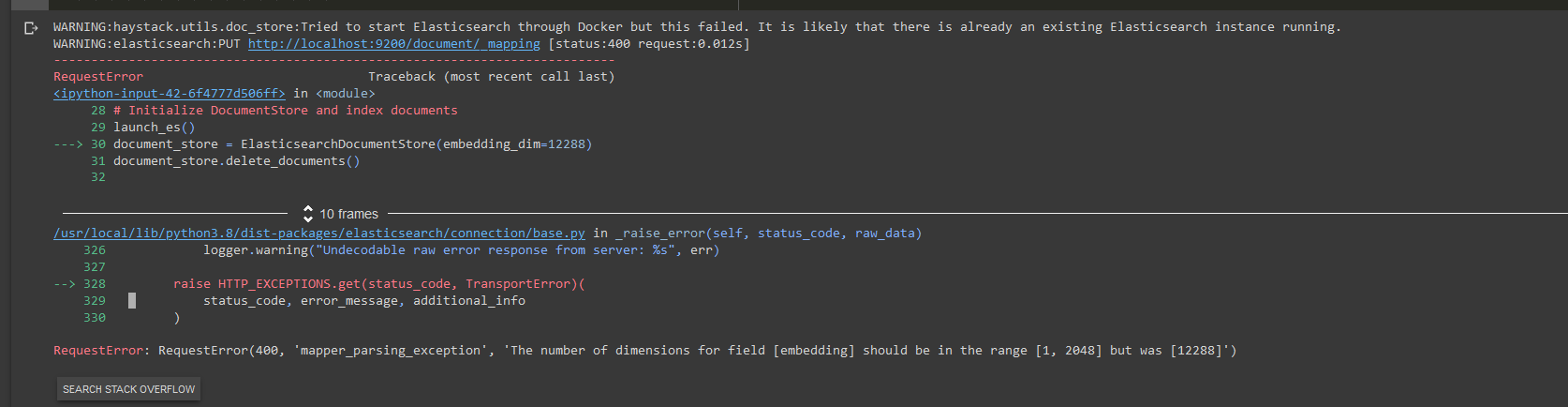
When I was trying to use davinci retrieving;
retriever = EmbeddingRetriever(document_store=document_store,
embedding_model="davinci",
model_format='openai',
top_k=10,
progress_bar=True,
api_key=os.getenv("OPENAI_API_KEY"))
Saying that the maximum that ElasticsearchDocumentStore can handle is 2048 ED while davinci maximum is 12288 ED, Is there a way to use the elasticsearch for that, or you suggest to me another document store?
Thanks, buddy!
Hello @AI-Ahmed I hope you are doing well too. I would suggest that you use a different document store, for example FaissDocumentStore. Elasticsearch limits the vector dimensions and I don't know how to work around that limit: https://www.elastic.co/guide/en/elasticsearch/reference/current/dense-vector.html#dense-vector-params
from haystack.document_stores import FAISSDocumentStore
document_store = FAISSDocumentStore(similarity="cosine", embedding_dim=12288)
@agnieszka-m Maybe we could update our page on pros and cons of different document store with the supported maximum size of vectors here: https://docs.haystack.deepset.ai/docs/document_store#choosing-the-right-document-store ?
Thanks, @julian-risch, for answering back. I am now working with PineconeDocumentStore; it does well, actually.
Another problem that I am facing is with OpenAIGenerator, it seems like it limits the answers, and it does show some weird results in comparison with the playground.
This is weird since we are using something like text-davinci-003. It should provide us with good results according to the retrieved documents. (documents' size is just 1700 words, ~2000 tokens, so it should give us good results since I don't exceed the token limits)
But it seems like it gives similar weak results (in terms of accuracy and length) as a miniature model such as LFQA.
Please, report that also.
I am using ExtractiveQApipeline, with EmbeddingRetriever.