lgt8fx
 lgt8fx copied to clipboard
lgt8fx copied to clipboard
Larger code size in LGT
The compiler produces quite a lot larger code sizes (additionally to having 1k less usable flash due to eeprom emulation), which makes larger Atmega projects impossible to run on LGT.
Blink example: Atmega Nano: 932 bytes (of 30720) LGT8F328P Nano: 1060 bytes (of 29696) => + 13.7%
Some of my complex code (OLED@I2C, Ethernet@SPI, 4 Keys, 4 channels of FastLED, EEPROM, ...): Atmega Nano: 30718 bytes (2 bytes left ^^) LGT8F328P Nano: 32960 bytes (absolutely impossible anymore) => +7.2%
Any ideas? ;)
Thank you
Not checked, but I think larger code came from LGT's larger setup code. After reset need to set more parameters than ATmega because no lock bits, LGT have port redirection capability which need to set up, internal oscillator, Embed on-chip debugging and more. These codes may not optimal.
That's a good point @LaZsolt, this chunk for example is largely not needed, and the compiler can't remove it: https://github.com/dbuezas/lgt8fx/blob/master/lgt8f/cores/lgt8f/main.cpp#L27-L107
I think it can't be removed even if no external clock is used because of this:
if((VDTCR & 0x0C) == 0x0C) {
// switch to external crystal
sysClock(EXT_OSC);
} else {
CLKPR = 0x80;
CLKPR = 0x01;
}
I don't understand what this snippet is supposed to do, it is checking if the low voltage threshold is 2.9v and if so, switching to the external oscillator:
We could also add menu options for tweaking the compiler optimisation flags (and decide between speed and size). Changing them will totally break the timings of bit-banged protocols (e.g. Software Serial), so the default should stay default. Here are some experimental results on a mega: https://www.instructables.com/id/Arduino-IDE-16x-compiler-optimisations-faster-code/
Please, let’s not start breaking things. If we want this core to be widely used it must be stable.
That's a good point @LaZsolt, this chunk for example is largely not needed, and the compiler can't remove it: https://github.com/dbuezas/lgt8fx/blob/master/lgt8f/cores/lgt8f/main.cpp#L27-L107
I don’t think this can be removed! This is changing the clock source and other vital settings.
I agree, should not break things. But there must bei something else, as the byte diff is not identical on my two examples. Most probably I have to disasm the large project for both targets and compare them, including the base diffs for blink. Thanks for enlighten me on the larger base, thats a couple of bytes, too.
Please, let’s not start breaking things. If we want this core to be widely used it must be stable. I don’t think this can be removed! This is changing the clock source and other vital settings.
Don't worry @seisfeld, I don't intend to remove that code! The observation is that this code is compiled even when no external clock is used (e.g. when it is not set in the menu nor called anywhere in your program). It is the compiler that should be able remove it, and only if nobody calls that function.
And the compiler cannot remove it because of the if((VDTCR & 0x0C) == 0x0C) {, which is only known at runtime
The internal clock is also set twice: First here: https://github.com/dbuezas/lgt8fx/blob/master/lgt8f/cores/lgt8f/main.cpp#L53-L54 and then again here: https://github.com/dbuezas/lgt8fx/blob/master/lgt8f/cores/lgt8f/main.cpp#L123-L137
there go a couple of extra unnecessary flash bytes
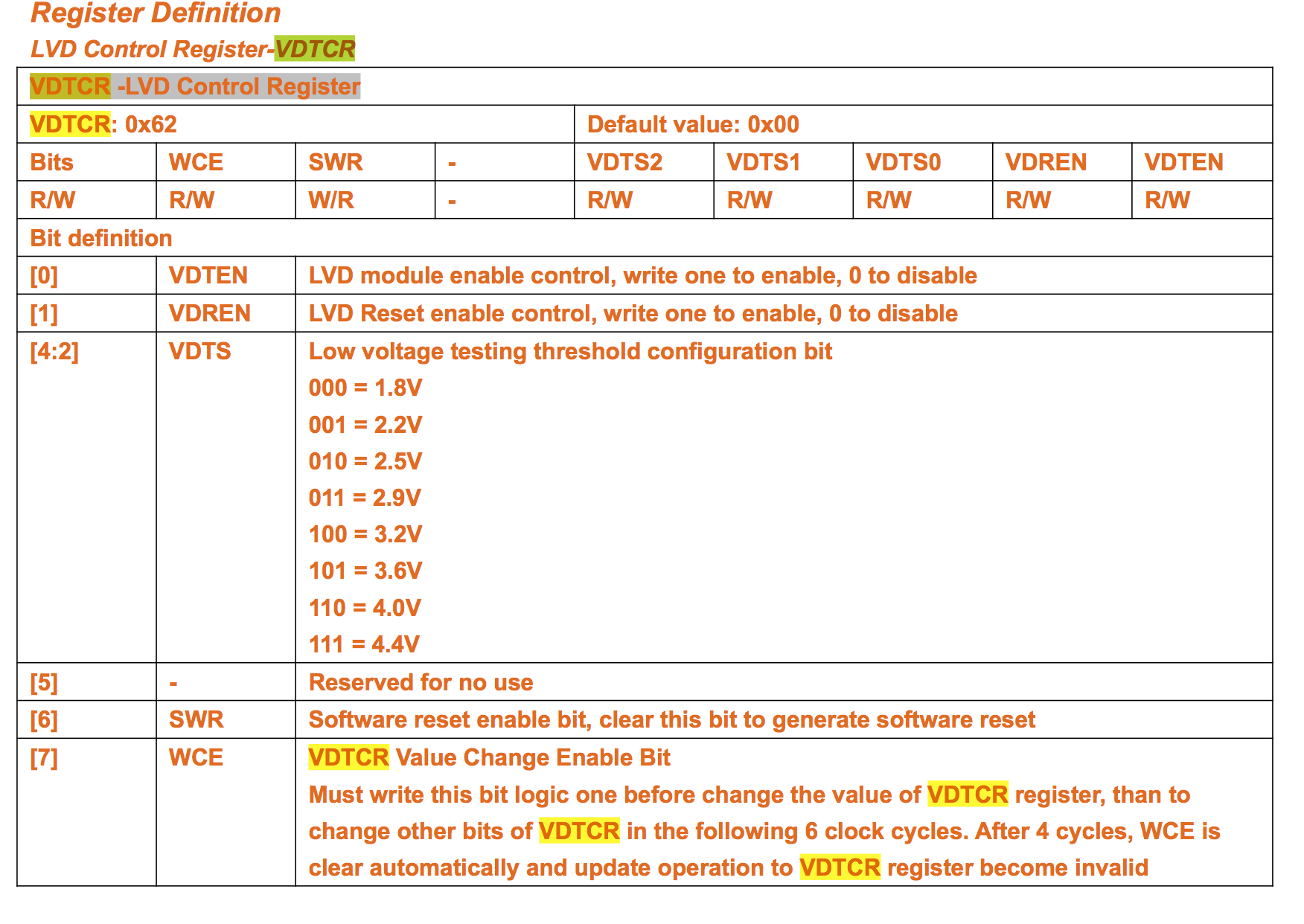
Everybody know here this picture below. From this memory map we can figure out, flash program memory content readable from RAM address 0x4000 and above. So every pgm_read_any() replaceable with a simple RAM read with 0x4000 RAM read offset. Every progmem related functions may redirected back to original RAM related codes with 0x4000 offset added. No need to double functions like memcpy_P, strchr_P, strcmp_P, strnlen_P and so on. PROGMEM modifier must have a new meaning.
I found in file C:\Users\LaZsolt\AppData\Local\Arduino15\packages\LGT8fx Boards\hardware\avr\1.0.5\cores\lgt8f\lgtx8p.h the definitions of LGT registers not optimal. This definitions tells to the compiler, which instrucions need to use for addressing an IO port: IN, OUT or LD, LDD, LDS instructions.
For example ATmega328PB and LGT328P has port E at same address.
In file C:\Users\Zsolt\AppData\Local\Arduino15\packages\arduino\tools\avr-gcc\7.3.0-atmel3.6.1-arduino5\avr\include\avr\iom328pb.h
#define PORTE _SFR_IO8(0x0E)
In file C:\Users\Zsolt\AppData\Local\Arduino15\packages\LGT8fx Boards\hardware\avr\1.0.5\cores\lgt8f\lgtx8p.h
#define IPORTE (*((volatile unsigned char *)0x2E))
...
#ifdef USE_EIO_EREG
...
#define PORTE IPORTE
...
#endif
The compiled code may be shorter, if every (volatile unsigned char *) port definition will be replaced to _SFR_IO8 or _SFR_MEM8 or _SFR_MEM16 .
Aren't both equivalent? I guess it is easy to test, I'll see if it makes a difference.
Code is prettier, but it seems like they are identical. I'm still very curious about what you said about pgm_read_any. If access can be made fast as RAM, it is certainly a game changer for some use cases.
Here are the results on a sketch that makes heavy use of IO registers:
- [CURRENT CORE]
Sketch uses 8614 bytes (29%) of program storage space. Maximum is 29696 bytes.
Global variables use 1871 bytes of dynamic memory.
- [_SFR_MEM16]
- --> I guess this is wrong/unnecessary, ~since IO addresses are all in the first 256 bytes~ since they all hold references to 8 bit registers
Sketch uses 8704 bytes (29%) of program storage space. Maximum is 29696 bytes.
Global variables use 1871 bytes of dynamic memory.
- [_SFR_MEM8]
Sketch uses 8614 bytes (29%) of program storage space. Maximum is 29696 bytes.
Global variables use 1871 bytes of dynamic memory.
_SFR_IO8 just adds 0x20 so the compiler would result in the same if the offsets were to be corrected.
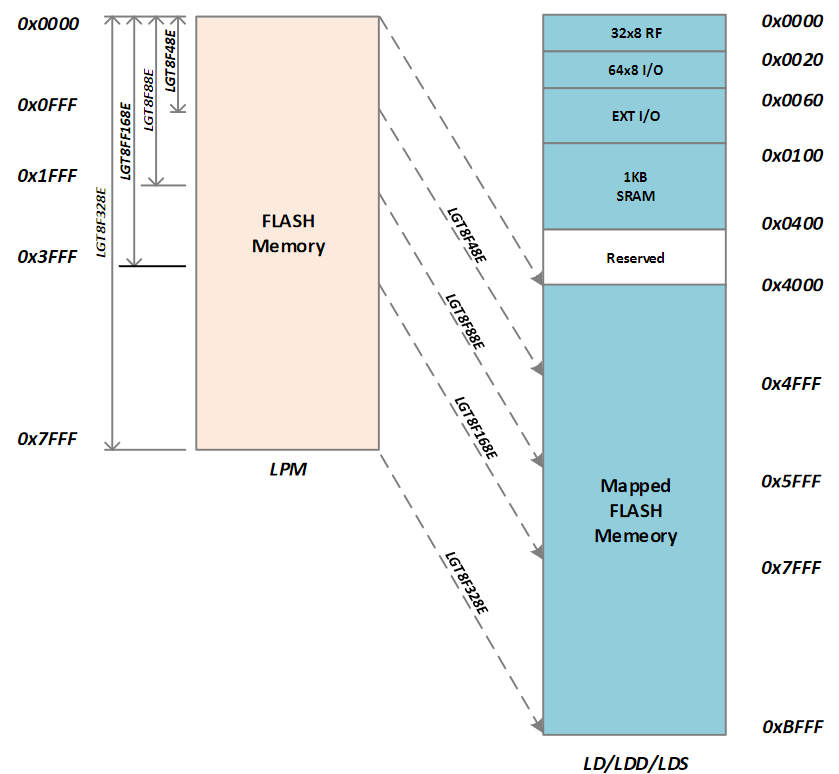
BTW, the P variant has the RAM a higher (starts in 0x2100 instead of 0x0400). I wonder what happens if one reads the reserved space 👽
_SFR_MEM16 is useful when read (or write) 16 bit AVR registers eg. ADC. This macro instructs the compiler read the lower byte first. https://github.com/arduino/ArduinoCore-avr/issues/344
Yes, you are right, I just came back to correct that 😆
I'm using timer 3 in an application and thought oh, instead of #define TCNT3 _SFR_MEM16(0x94) I should do #define TCNT3 _SFR_MEM8(0x94) and it stopped reading the top 8 bits
Demo for addressing re-mapped FLASH.
const char CharsInProgmem [] PROGMEM ="This is some text.";
char charbuffer[25];
void setup() {
Serial.begin(38400);
/* Read from progmem address */
uint16_t p_addr = (uint16_t) &CharsInProgmem;
Serial.println( p_addr,HEX );
while ( char c = pgm_read_byte(p_addr++) ) Serial.print( c );
Serial.println();
/* Read from re_mapped address */
char* p = (char*)( 0x4000 + (uint16_t) &CharsInProgmem );
Serial.println( (uint16_t) p,HEX );
while ( *p ) Serial.print( *(p++) );
Serial.println();
/* So this two functions are equivalent. */
memcpy_P( charbuffer, CharsInProgmem , sizeof(CharsInProgmem) );
memcpy ( charbuffer, (char*) ( 0x4000 + (uint16_t) &CharsInProgmem ), sizeof(CharsInProgmem) );
}
void loop() {
}
This is awesome! I made a simple test and measured your solution to be > 27% faster than using pgm_read. And it is way simpler also 🎉
This for example works perfectly:
Serial.println((char*) ( 0x4000 + (uint16_t) &CharsInProgmem ));
Benchmark based on your findings and code
const char CharsInProgmem [] PROGMEM ="Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.";
// #define TEST_OUTPUT_CONTENT // uncomment this to test that both read the same text
#ifdef TEST_OUTPUT_CONTENT
const uint32_t iterations = 2;
#else
const uint32_t iterations = 10000;
#endif
void setup() {
Serial.begin(38400);
volatile char c;
unsigned long start;
uint16_t p_addr;
start = millis();
for (uint32_t i = 0;i<iterations;i++){
p_addr = (uint16_t) &CharsInProgmem;
c = 1;
while ( c ){
c = pgm_read_byte(p_addr++);
#ifdef TEST_OUTPUT_CONTENT
Serial.print(c);
#endif
}
}
Serial.println();
Serial.print("pgm_read took: ");
Serial.println(millis() - start);
p_addr = ( 0x4000 + (uint16_t) &CharsInProgmem );
volatile char* p;
start = millis();
for (uint32_t i = 0;i<iterations;i++){
p = (char*)p_addr;
c = 1;
while ( c ){
c = *(p++);
#ifdef TEST_OUTPUT_CONTENT
Serial.print(c);
#endif
}
}
Serial.print("direct access took: ");
Serial.println(millis() - start);
Serial.println("direct print:");
Serial.println((char*) ( 0x4000 + (uint16_t) &CharsInProgmem ));
}
void loop() {
}
Output:
pgm_read took: 1989
direct access took: 1448
direct print:
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
@dbuezas : Nice benchmark and cool performance gain !
Though, I've noticed that the benchmark is slightly asymmetrical since the first dt includes an extra Serial.println(); and since the strings that are Serial.printed before the dt calculation are of different length.
So I slightly modified your code to calculate the dt before any Serial.printing :
start = millis() - start;
Serial.println();
Serial.print("pgm_read took: ");
Serial.println( start );
...
start = millis() - start;
Serial.print("direct access took: ");
Serial.println( start );
And the result is :
pgm_read took: 1808
direct access took: 1448
However, it surprises me because I was expecting a decrease with the direct access too, but it did not change. Why ?
Also, I was wondering what would be an actual performance gain if the variable c was actually used to do some calculation with it into the while loop.
const char CharsInProgmem [] PROGMEM ="Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.";
// #define TEST_OUTPUT_CONTENT // uncomment this to test that both read the same text
#ifdef TEST_OUTPUT_CONTENT
const uint32_t iterations = 2;
#else
const uint32_t iterations = 10000;
#endif
void setup() {
Serial.begin(38400);
volatile char c;
unsigned long start;
uint16_t p_addr;
uint32_t result = 0; // <-------------------- HERE
start = millis();
for (uint32_t i = 0;i<iterations;i++){
p_addr = (uint16_t) &CharsInProgmem;
c = 1;
while ( c ){
c = pgm_read_byte(p_addr++);
#ifdef TEST_OUTPUT_CONTENT
Serial.print(c);
#else
result += c; // <------------------ HERE
#endif
}
}
start = millis() - start; // <------------- HERE
Serial.println();
Serial.print("pgm_read took: ");
Serial.println( start ); // <------------ HERE
Serial.print("result: "); // <------------ HERE
Serial.println( result ); // <------------ HERE
// Serial.flush(); // <---------- HERE (just for test)
result = 0; // <------------ HERE
p_addr = ( 0x4000 + (uint16_t) &CharsInProgmem );
volatile char* p;
start = millis();
for (uint32_t i = 0;i<iterations;i++){
p = (char*)p_addr;
c = 1;
while ( c ){
c = *(p++);
#ifdef TEST_OUTPUT_CONTENT
Serial.print(c);
#else
result += c; // <----------------- HERE
#endif
}
}
start = millis() - start; // <---------------- HERE
Serial.print("direct access took: ");
Serial.println( start ); // <--------------- HERE
Serial.print("result: ");
Serial.println( result ); // <---------------- HERE
Serial.println("direct print:");
Serial.println((char*) ( 0x4000 + (uint16_t) &CharsInProgmem ));
}
void loop() {
}
And the result :
pgm_read took: 3793
result: 538740000
direct access took: 3252
result: 538740000
Which gives a gain of ~14%.
@dbuezas : Nice benchmark and cool performance gain !
Thanks! credit goes to @LaZsolt :)
benchmark is slightly asymmetrical
Oh, good point @SuperUserNameMan !
And it is probably proportionally much faster, since the while is adding some constant overhead to both. I think we could look at the resulting assembly code to be precise. That's also visible in your new test which does further operations with c.
However, it surprises me because I was expecting a decrease with the direct access too, but it did not change. Why ?
Serial is asynchronous so it could be that the message is kept in the serial buffer and send after the time is computed for the direct access code.
This is perfect to make a wave generator with the board, one can store precomputed waves in flash and access them with no overhead :)
Btw, @LaZsolt have you tried STORING to those addresses? does it actually write in flash also? 😮
@dbuezas :
Serial is asynchronous so it could be that the message is kept in the serial buffer and send after the time is computed for the direct access code.
I added a Serial.flush() between the two tests, but since i did not notice any difference with your benchmark, I replaced millis() with micros().
And I've found 52 µs of difference. On my new test, the difference is 92 µs.
Still, even if 15% increase of performance, that's a good trick to know.
credit goes to @LaZsolt :)
Sorry, I was so excited that I forgot : thanks @LaZsolt ! Nice finding !
@dbuezas :
Btw, @LaZsolt have you tried STORING to those addresses? does it actually write in flash also?
According the databook this address range readable only.
Although it was unlikely it was also writable, I'm glad that it's not. I can only imagine the number of bugs that could hide for people who forget that their ROM strings are supposed to be read only and they accidentally write to them (something as easy as a strcat) only to find their program goes completely crazy after that. So, as inconvenient as it may seem that you can't write with this method, be glad because it saves us from an even larger problem.
On Mon, Oct 12, 2020 at 12:16 PM LaZsolt [email protected] wrote:
@dbuezas https://github.com/dbuezas :
Btw, @LaZsolt https://github.com/LaZsolt have you tried STORING to those addresses? does it actually write in flash also?
According the databook this address range readable only.
— You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub https://github.com/dbuezas/lgt8fx/issues/33#issuecomment-707215526, or unsubscribe https://github.com/notifications/unsubscribe-auth/ACPEX7HADUBR5VQEI7TXFUTSKMTXRANCNFSM4PI266BA .
Bummer. I thought we'd have 20k of RAM until the flash dies.
I just tried it and it doesn't do anything.
Actually looking at some disassembled code, I think my benchmark is trash.
volatile uint16_t p_addr = (uint16_t)&CharsInProgmem;
4f2: 88 e7 ldi r24, 0x78 ; 120
4f4: 90 e0 ldi r25, 0x00 ; 0
4f6: 9a 83 std Y+2, r25 ; 0x02
4f8: 89 83 std Y+1, r24 ; 0x01
volatile char c1 = pgm_read_byte(p_addr);
4fa: e9 81 ldd r30, Y+1 ; 0x01
4fc: fa 81 ldd r31, Y+2 ; 0x02
4fe: e4 91 lpm r30, Z
500: ec 83 std Y+4, r30 ; 0x04
volatile char c2 = *((char*)p_addr);
502: e9 81 ldd r30, Y+1 ; 0x01
504: fa 81 ldd r31, Y+2 ; 0x02
506: 80 81 ld r24, Z
508: 8b 83 std Y+3, r24 ; 0x03
and both lpm and ld take 2 cycles.
I made another more direct benchmark
const char CharsInProgmem[] PROGMEM = "[18369 chars of text]";
void setup() {
Serial.begin(38400);
volatile char c;
unsigned long start;
unsigned long end;
uint16_t p_addr;
char* p;
// start pgm_read
p_addr = (uint16_t)&CharsInProgmem;
c = 1;
start = micros();
while (c) {
c = pgm_read_byte(p_addr++);
}
end = micros();
Serial.print("pgm_read took: ");
Serial.println(end - start);
// start direct access
p_addr = (0x4000 + (uint16_t)&CharsInProgmem);
p = (char*)p_addr;
c = 1;
start = micros();
while (c) {
c = *(p++);
}
end = micros();
Serial.print("direct access took: ");
Serial.println(end - start);
}
void loop() {}
and the result is:
pgm_read took: 5766 direct access took: 5808
So I think both methods are actually equivalent.
I also compared the size of the resulting code using only one method or the other one and the sketch uses exactly the same amount of space.
@dbuezas :
and both lpm and ld take 2 cycles.
LPM take 2 cycles, while LD 1 cycle in LGT. Not a big performance gain in a larger program.
What I saw in the datasheet was that it takes "1/2" so 1 or 2, I couldn't find what it depends on. Given the result of the test, wouldn't it be 2 ticks?
Actually looking at some disassembled code, I think my benchmark is trash.
@dbuezas : with GCC optimizing everything behind the scene, I'm not even sure how I would write a meaningful benchmark myself. Seems complicated to me.
So I think both methods are actually equivalent.
I tested the direct access method on a real project of mine this afternoon. I could not measure precisely the gain of performance for some technical reasons, but the average gain of performance I noticed was in the range of 10µs. And under certain circumstances, I also noticed a loss of performance in the range of 50µs which I could not explain (might just be a bug since my project is still WIP).
So I'd say that, even if it's tiny, there is a real gain of performance, but that the benefits will depend on each use-case.