pytorch-lr-finder
 pytorch-lr-finder copied to clipboard
pytorch-lr-finder copied to clipboard
Question: Number of iterations
I tried the LR finder with 100 and with 1000 iterations (all other parameters staying the same) and got very different recommendations for the LR - for 100 iterations it was 1.2e-3, and for 1000 iterations 3.3e-5. I tried training with both of these, and they don't produce optimal results compared to a more aggressive learning rate - 5e-2 (which is actually found by the 100 iterations to be the maximum LR).
What would be the ideal number of iterations that you would recommend? Would this number be calculated using model / dataset size in any way? I get the feeling that doing more iterations in general affects the finder, because the maximum learning rate is found faster. I did not look at the code, but I guess that the weights are not reset after each iteration - do you think it would be good to reset them, such that the previous iterations don't affect subsequent ones?
Hi @swigicat.
Since there isn't enough information about the model, dataset, and other configurations in your task, I can just give you some brief suggestions & explanations of this result:
-
Make sure you are using a reasonable but large enough learning rate as the
end_lrparameter forlr_finder.range_test(). Because we need to force the model overfit your dataset in order to find out the possible maximal learning rate without making the training unstable. It's usually recommended to use 1 or 10 as this parameter. -
As for the "suggested learning rate", I would have to say that it's still a topic in an active research area, so that it cannot be guaranteed that the algorithm we implemented for this suggestion will always return a good one. Also, in #44, we've discussed about the implementation of returning a suggested learning rate, and you will find that there have been a variety of algorithms proposed to solve this problem.
-
As you said that the suggested learning rates will be different with different iterations, it's actually can be easily affected by a fact: "the greater
num_iteris given, the finer scale oflr-losscurve we will get". Though it seems that 1.2e-3 and 3.3e-5 is quite different, they probably still locate in a similar interval (descending region) on thelr-losscurve. I would suggest you check out those plotted graphs. Besides, we also have to consider about distribution of dataset. If the dataset is quite imbalanced, it can easily affect the result you get since there are 900 additional batches were fed into the model when it going to run 1000 iterations. You can also check out #50 for further details about this. -
Since we don't know the actual number of iterations run in your task after picking the suggested learning rate, I would also recommend you investigating the loss-iteration curve of your training & validation dataset to see whether there is a "deep double descent" phenomenon. This is probably another cause of the result you got.
Regarding to the questions you asked:
What would be the ideal number of iterations that you would recommend?
100 is usually large enough to find a good range of learning rate. As for picking a proper initial learning rate from the result of range test, it really depends on the training strategy you are going to apply. In my case,
- Using SGD as the optimizer (without scheduler): choose a value which is slightly greater than the suggested value returned by this
lr_finder. - Using Adam as the optimizer (without scheduler): choose a smaller one instead.
- Using a cyclic scheduler (e.g. one cycle policy, cosine annealing): choose a larger one as the maximum learning rate, and use its 1/10 as the minimal learning rate. (see also section 4-1 in this paper, which is also written by Leslie N. Smith)
Would this number be calculated using model / dataset size in any way?
Currently I cannot give you a definite answer about this. But the number of iterations should not affect the result too much if the dataset is balanced when selected number is greater than 100. Therefore, I would say that preprocessings for dataset would be much more important than choosing the number of iterations for learning rate range test.
... do you think it would be good to reset them, such that the previous iterations don't affect subsequent ones?
I had tried before, but it didn't work well. I guess it's because the model would keep in the "untrained" state in each new iteration, and it makes this range test harder to show the changes under a different learning rate.
Those explanations might disappoint you, but I want to let you know that learning rate range test is still a good solution when you are trying to explore all proper model architectures for your task in the early stage.
Because learning rate is still an important hyper-parameter that can easily affect model performance. And you can use this library to find out proper models without wasting too much time and resource.
Then, if you want to maximize performance after adopting a proper model, I would suggest you trying some hyper-parameters tuning algorithms/libraries, e.g. Bayesian optimization, HyperBand, ray (library) etc.
Overall, there are still many active researches in this field. If you are interesting in it, you can stay tuned to this repository. And if you have any further questions, please feel free to let me know.
I agree with @swigicat , "I get the feeling that doing more iterations in general affects the finder, because the maximum learning rate is found faster. ". I got similar results for my experiments: different maximal lr for different num_iter.
I'm using Resnet r50 for face recognition, and the amount of datasets is quite huge (more than 18 million images).
- Num_iter = 100: default 100 is not enough, the loss does not decrease at all for only 100 iterations;
- Num_iter = 17k(0.5 epoch): the maximal lr achieving minimal loss is 0.6;
- Num_iter = 35k(1 epoch): the maximal lr achieving minimal loss is 0.3.
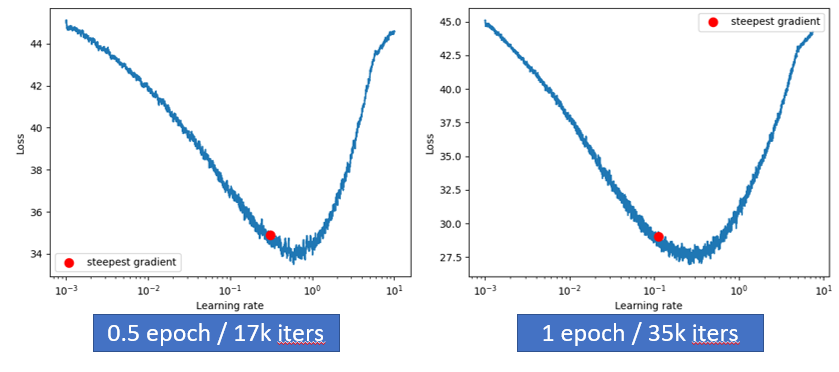
The question is: which one should I believe? Is lr range test applicable for large models/difficult tasks? One thing we can know from the experiments is: There is indeed relationship between the lr range results and num_iter, since the decreasing of loss benefit from both reasonable lr value and more iterations. When num_iter is large, the model has more chances to learn with more iterations, so the transition point of lr comes earlier than in smaller num_iter cases. I checked the original publication of CLR which proposed lr range test, the author suggests to use several epochs for num_iter. So I guess it's better to set up at least 1 epoch to get reasonable results and lr suggestions.
Hello I have a question. How many epochs would be recommended for LR range test?
@rose-jinyang, the original paper suggests that there's independence between the number of iterations and the resulting curve. My own experience tells me that it depends on the dataset and the neural network architecture. Some combinations show more independence than others.
In general, more iterations is better, but the trade-off is time. You should treat it like a hyperparameter, meaning that you should try some values and see how the curve looks. You essentially want to set it in such a way that the loss curve shows convergence and then divergence (a V or U shape like you see in @milliema's last comment).