Training on A100
Thank you for your great work. I finetune the 12b model on an 8-card A100 40G using fp16 and deepspeed stage=3, per-device-train-batch-size=2, and gradient_accumulation_steps=4. The processed dataset had 10,971,000 rows after filtering for truncated records. During training, I found that the speed was approximately 10.8 hours per 1% epoch data, so it would take about 45 days to complete one epoch. Is it normal for it to be this slow?
That's a lot of data for fine-tuning, maybe too much. After all, I think dolly saw about 10 epochs x 15k example for all of its fine tuning, which is a few percent of what you're trying to run.
Don't use fp16, let it use bf16. Why turn on gradient accumulation steps and reduce batch size - are you running OOM? that slows things down otherwise.
Your runtime seems kind of plausible, though I bet it could be faster. However, you're going to spend tens of thousands of dollars to see the whole dataset, so consider whether that's necessary vs just stopping at some checkpoint after it seems to converge.
Thank you for your response. I am trying to fine-tune Dolly's knowledge on Chinese data, so I have collected a considerable amount of data. However, I am experiencing CUDA OUT OF MEMORY errors when using bf16 on the A100 40G, and even batch size 4 is causing OOM issues. Therefore, I am using fp16 and gradient accumulation. The following is the GPU memory usage during training:
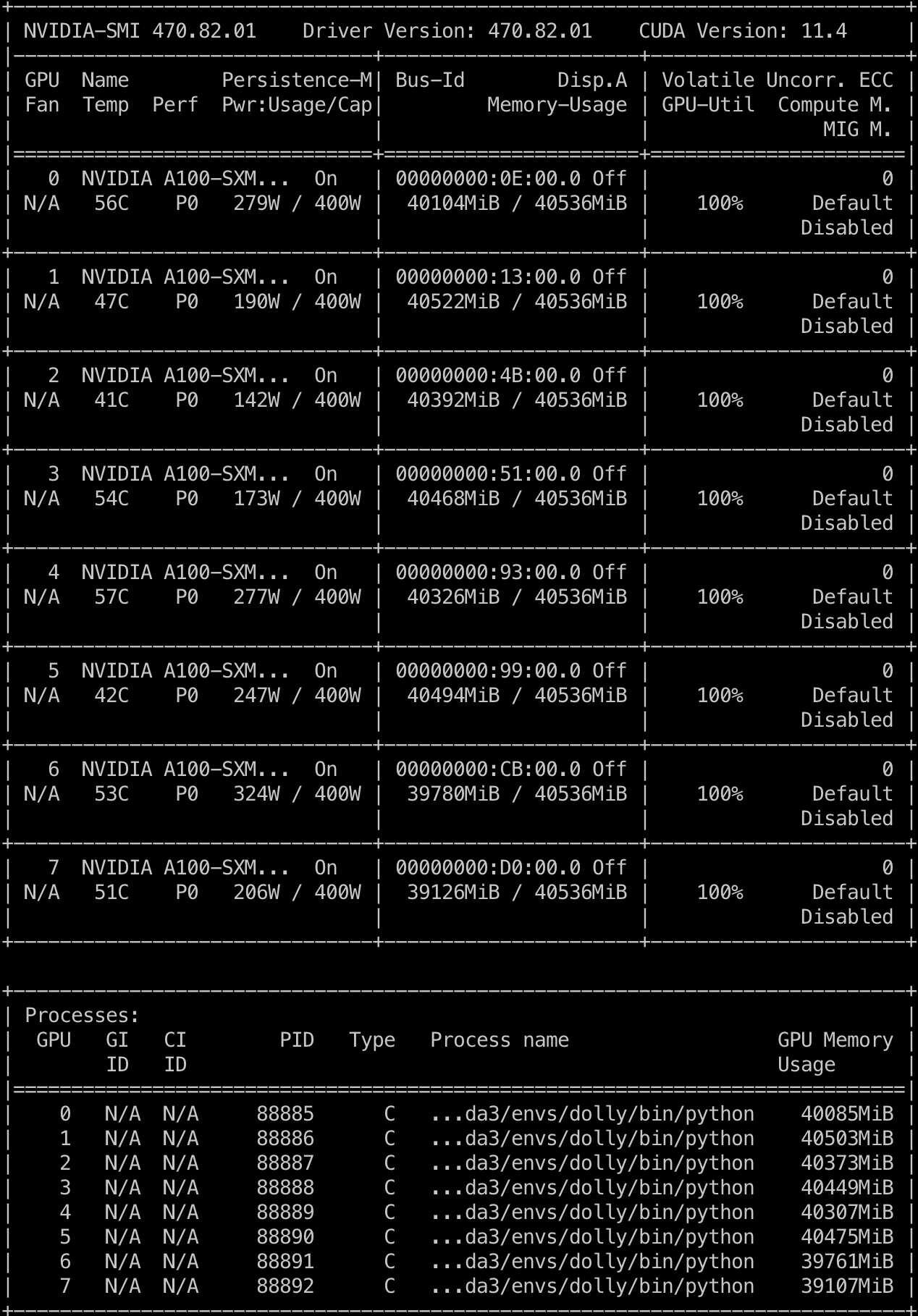
bf16 should still be used instead of fp16; it doesn't increase mem usage. OK, it's possible you do need more memory if your input tokenizes differently and you have long sequences. You are retraining the tokenizer too? the given tokenizer is for English language text.
Here's the issue at hand: with the same configuration and parameters, bf16 encounters OOM errors while fp16 does not. Considering that expanding the vocabulary will add additional untrained weights, I have not expanded the vocabulary, the given tokenizer based on Unicode can encode almost all Chinese characters.
I may understand your needs. Because the tokenizer of the existing Dolly model is only for English, it is meaningless if you want to train Chinese corpus on it. Therefore, if you want to train on Chinese corpus, you need to reconstruct the tokenizer for training. The existing Dolly model It doesn't solve your existing needs.
Right, does not make sense to fine-tune Pythia, either; it was pre-trained on the Pile, which is mostly English text.
https://github.com/facebookresearch/llama/blob/main/FAQ.md#4
I think this applies to Dolly as well.