terraform-provider-databricks
 terraform-provider-databricks copied to clipboard
terraform-provider-databricks copied to clipboard
Published
20 hours ago •
 databricks
databricks
node_type_id was not exported from the terraform exporter.
trafficstars
node_type_id was not exported from the terraform exporter.
As a result, when making an attempt to import the cluster definition using the terraform plan command, the value was (known after apply)
Ultimately when running the apply command, the ensuing error was
Error: cannot create cluster: Missing required field 'node_type_id'
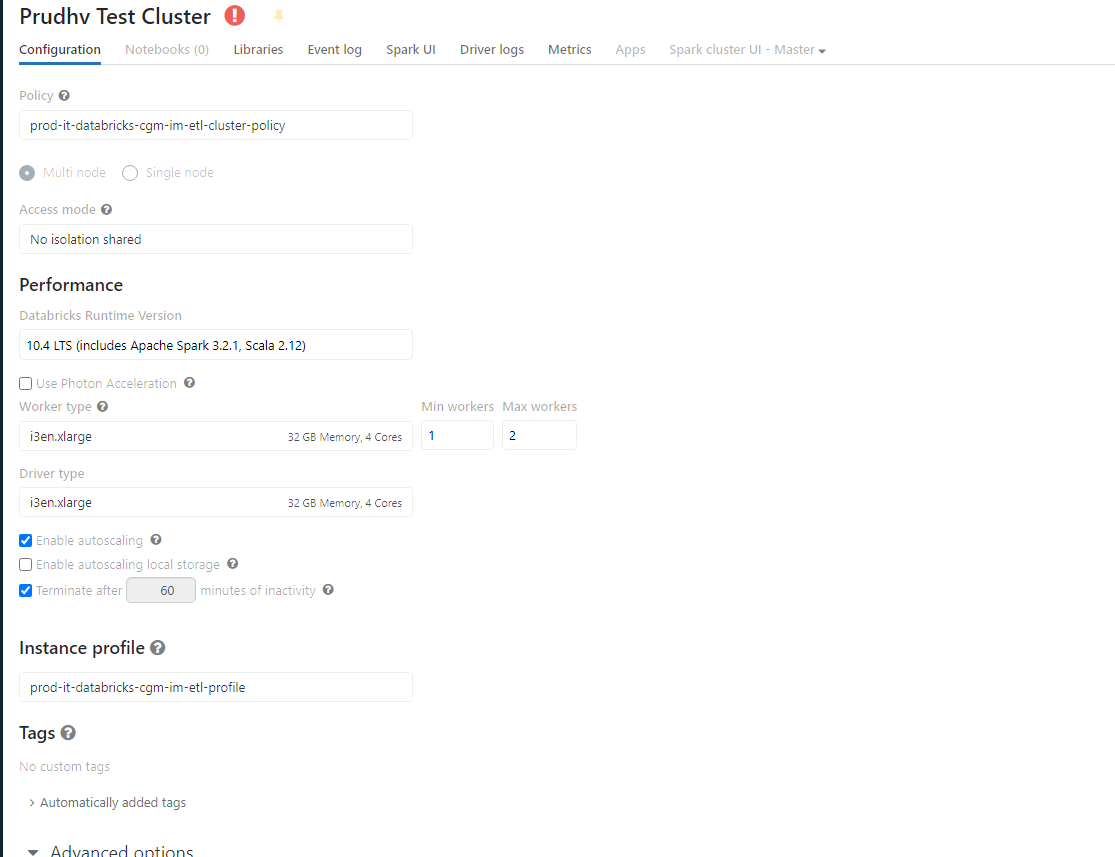
resource "databricks_cluster" "prudhv_test_cluster_0919_182702_4l7lidsj" {
spark_version = "10.4.x-scala2.12"
spark_env_vars = {
PYSPARK_PYTHON = "/databricks/python3/bin/python3"
}
spark_conf = {
"spark.hadoop.fs.s3a.server-side-encryption-algorithm" = "AES256"
"spark.hadoop.javax.jdo.option.ConnectionDriverName" = "org.mariadb.jdbc.Driver"
"spark.hadoop.javax.jdo.option.ConnectionPassword" = "{{secrets/xx_scopename/password}}"
"spark.hadoop.javax.jdo.option.ConnectionURL" = "jdbc:mysql://prod-rds-aws.us-west-2.rds.amazonaws.com:38000/qwerty"
"spark.hadoop.javax.jdo.option.ConnectionUserName" = "{{secrets/xx_scopename/user}}"
"spark.sql.hive.metastore.jars" = "maven"
"spark.sql.hive.metastore.version" = "2.3.0"
}
policy_id = databricks_cluster_policy.dr_it_databricks_cgm_im_etl_cluster_policy.id
init_scripts {
s3 {
region = "us-west-2"
destination = "s3://databrickss3bucketname/init-conf.sh"
}
}
init_scripts {
s3 {
region = "us-west-2"
destination = "s3://databrickss3bucketname/install_dmexpress.sh"
}
}
data_security_mode = "NONE"
custom_tags = {
app = "9221"
av_exempt = "no"
bu = "it"
clusterbusname = "Databricks cgm-im etl"
dr = "no"
env = "dr"
ha = "yes"
hostname = "g-databricksworker.glic.com"
"reaper:schedule" = "off"
zone = "private"
}
cluster_name = "Prudhv Test Cluster"
cluster_log_conf {
s3 {
region = "us-west-2"
enable_encryption = true
destination = "s3://databrickss3bucketname_cluster-logs/"
canned_acl = "bucket-owner-full-control"
}
}
aws_attributes {
zone_id = "us-west-2a"
spot_bid_price_percent = 100
instance_profile_arn = databricks_instance_profile.dr_it_databricks_cgm_im_etl_profile.id
first_on_demand = 1
availability = "SPOT_WITH_FALLBACK"
}
autotermination_minutes = 60
autoscale {
min_workers = 1
max_workers = 2
}
}