Unable to run df.head() after creating dummies
Hi,
My code runs OK, but when I create dummy features from my categorical variable I get an error trying to print the results:
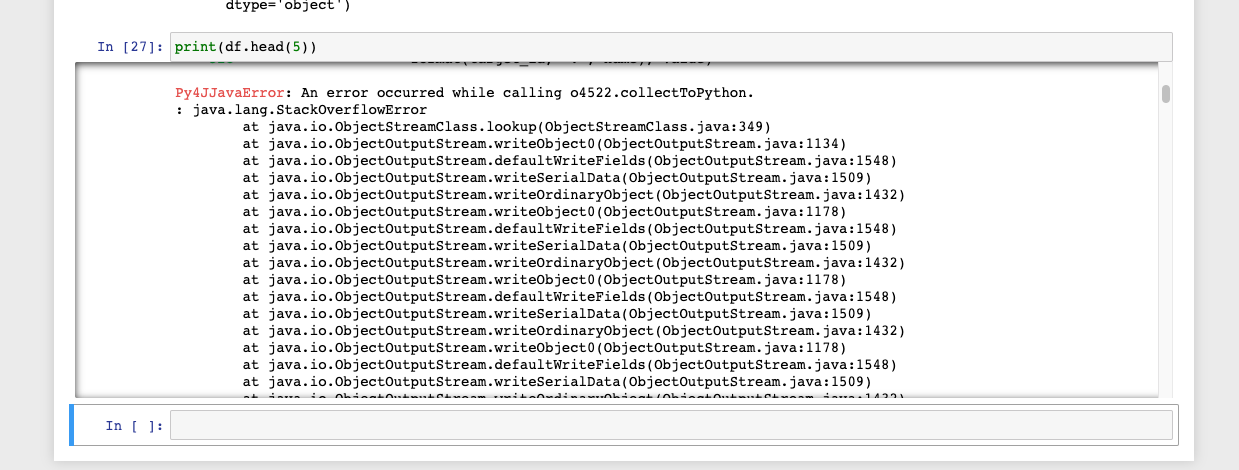
I have no idea what this means. If I ignore the fact that I cannot print my dataframe and continue, the rest of operations run OK. Also when I bring the data back to the head node as a Pandas df, I cannot run df.head() either.
Regards,
Ramon
Could you share a simple example to reproduce the error?
The examples in the document seems working finely.
>>> s = ks.Series(list('abca'))
>>> ks.get_dummies(s)
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
>>> ks.get_dummies(s).head(2)
a b c
0 1 0 0
1 0 1 0
>>> df = ks.DataFrame({'A': ['a', 'b', 'a'], 'B': ['b', 'a', 'c'], 'C': [1, 2, 3]})
>>> ks.get_dummies(df, prefix=['col1', 'col2'])
C col1_a col1_b col2_a col2_b col2_c
0 1 1 0 0 1 0
1 2 0 1 1 0 0
2 3 1 0 0 0 1
>>> ks.get_dummies(df, prefix=['col1', 'col2']).head(2)
C col1_a col1_b col2_a col2_b col2_c
0 1 1 0 0 1 0
1 2 0 1 1 0 0
``#libraries
from pyspark import SparkConf from pyspark.sql import SparkSession
import databricks.koalas as ks import numpy as np
#create spark session
conf = SparkConf().setAll([("spark.driver.memory", "2g"), ("spark.master", "local"), ("spark.executor.memory", "2g"), ("spark.memory.fraction", "0.6")]) spark = SparkSession.builder.config(conf = conf).getOrCreate()
#read and cache dataset df = spark.read.csv("/Users/ramonsotogarcia/Desktop/Data/autompg.csv", inferSchema = True, header = True).to_koalas() df.spark.cache() df.count()
#drop na
df.dropna(inplace = True)
#feature engineering
def select_brand(carname): return carname[3:-3].split(" ")[0]
df["brand"] = df["carname"].apply(lambda x: select_brand(x))
#recode features
df.loc[df["brand"] == "chevroelt", ["brand"]] = "chevrolet" df.loc[(df["brand"] == "vw") | (df["brand"] == "vokswagen"), ["brand"]] = "volkswagen" df.loc[df["brand"] == "mercedes", ["brand"]] = "mercedes-benz" df.loc[df["brand"] == "toyouta", ["brand"]] = "toyota" df.loc[df["brand"] == "maxda", ["brand"]] = "mazda" df.loc[df["modelyear"] == 1, ["modelyear"]] = 71
#get dummies
df = ks.get_dummies(df, columns = ["brand"], dtype = np.int32)
df.head(5) #error``
I must also say that it seems to be working fine if I ommit this step:
df.loc[df["brand"] == "chevroelt", ["brand"]] = "chevrolet"
df.loc[(df["brand"] == "vw") | (df["brand"] == "vokswagen"), ["brand"]] = "volkswagen"
df.loc[df["brand"] == "mercedes", ["brand"]] = "mercedes-benz"
df.loc[df["brand"] == "toyouta", ["brand"]] = "toyota"
df.loc[df["brand"] == "maxda", ["brand"]] = "mazda"
df.loc[df["modelyear"] == 1, ["modelyear"]] = 71
But I had to recode my data. Any idea why this is happening?