How to apply a function includes a class inside ? got the error: did not recognize Python value type when inferring an Arrow data type
Hi all , I am trying to scale the my computation with koalas (instead of pandas). I have a class and I try to apply one of the function from the class on a dataframe two columns. With pandas df it works as expected, but when I do with koalas df, it throws the error
Could not convert <__main__.XYZ object at 0x7f7746dfbef0> with type XYZ: did not recognize Python value type when inferring an Arrow data type
I share the notebook which has class definition and computation with both of way. Error is in cell (13). Do you have any idea which are has a bug (koalas or arrow) ?
https://github.com/akifcakir/questions/blob/master/class_apply.py
Koalas doesn't support the custom type as a return type from UDFs. How about:
>>> kdf['y_vectorized_lambdas'] = kdf.apply(lambda df: mul_func(df).myfunc(), axis=1)
>>> kdf
col1 col2 y_vectorized_lambdas
0 2 3 6
1 3 4 12
@ueshin thanks a lot for your answer, with this approach it completes the job in example notebook and my original case.

Nevertheless when I tried to run df.head() in original case, I am getting that error in below with a warning. I tried with spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "false") since in warning it says it set to true and run again applying function and head() but got same warning and error.
Your support would be appreciated, thanks in advance.
I have a cluster with this configuration.
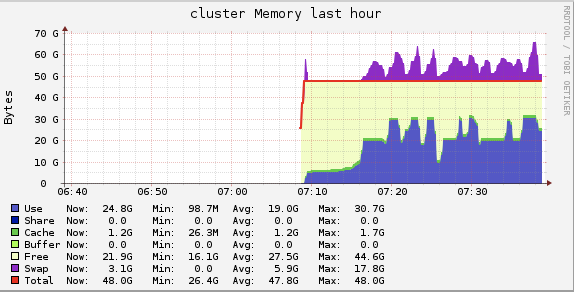
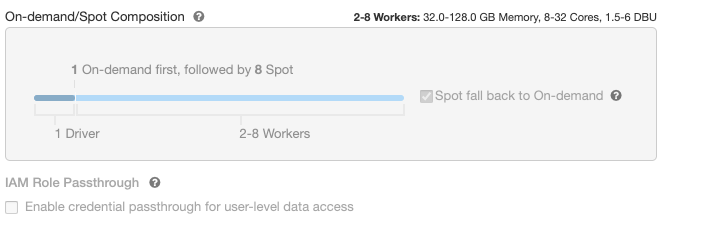 during the run, there were only 2 worker. And the cluster memory was like in below.
during the run, there were only 2 worker. And the cluster memory was like in below.
Warning Message
Out[44]: /databricks/spark/python/pyspark/sql/dataframe.py:2205: UserWarning: toPandas attempted Arrow optimization because 'spark.sql.execution.arrow.enabled' is set to true, but has reached the error below and can not continue. Note that 'spark.sql.execution.arrow.fallback.enabled' does not have an effect on failures in the middle of computation. An error occurred while calling o2312.getResult. : org.apache.spark.SparkException: Exception thrown in awaitResult: at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:358) at org.apache.spark.security.SocketAuthServer.getResult(SocketAuthServer.scala:67) at org.apache.spark.security.SocketAuthServer.getResult(SocketAuthServer.scala:63) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380) at py4j.Gateway.invoke(Gateway.java:295) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:251) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 43 in stage 6.0 failed 4 times, most recent failure: Lost task 43.3 in stage 6.0 (TID 214, 10.152.212.66, executor 1): java.net.SocketException: Connection reset at java.net.SocketInputStream.read(SocketInputStream.java:210) at java.net.SocketInputStream.read(SocketInputStream.java:141) at java.io.BufferedInputStream.fill(BufferedInputStream.java:246) at java.io.BufferedInputStream.read(BufferedInputStream.java:265) at java.io.DataInputStream.readInt(DataInputStream.java:387) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:181) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:144) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:494) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:440) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409) at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:125) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.doRunTask(Task.scala:140) at org.apache.spark.scheduler.Task.run(Task.scala:113) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$17.apply(Executor.scala:606) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1541) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:612) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
Error Message
Py4JJavaError Traceback (most recent call last) /databricks/python/lib/python3.7/site-packages/IPython/core/formatters.py in call(self, obj) 700 type_pprinters=self.type_printers, 701 deferred_pprinters=self.deferred_printers) --> 702 printer.pretty(obj) 703 printer.flush() 704 return stream.getvalue()
/databricks/python/lib/python3.7/site-packages/IPython/lib/pretty.py in pretty(self, obj) 400 if cls is not object
401 and callable(cls.dict.get('repr')): --> 402 return _repr_pprint(obj, self, cycle) 403 404 return _default_pprint(obj, self, cycle)/databricks/python/lib/python3.7/site-packages/IPython/lib/pretty.py in repr_pprint(obj, p, cycle) 695 """A pprint that just redirects to the normal repr function.""" 696 # Find newlines and replace them with p.break() --> 697 output = repr(obj) 698 for idx,output_line in enumerate(output.splitlines()): 699 if idx:
/local_disk0/pythonVirtualEnvDirs/virtualEnv-4f2887b9-a4b7-4433-9ec6-5fb3cab7d386/lib/python3.7/site-packages/databricks/koalas/usage_logging/init.py in wrapper(*args, **kwargs) 178 start = time.perf_counter() 179 try: --> 180 res = func(*args, **kwargs) 181 logger.log_success( 182 class_name, function_name, time.perf_counter() - start, signature
/local_disk0/pythonVirtualEnvDirs/virtualEnv-4f2887b9-a4b7-4433-9ec6-5fb3cab7d386/lib/python3.7/site-packages/databricks/koalas/frame.py in repr(self) 9963 return self._to_internal_pandas().to_string() 9964 -> 9965 pdf = self._get_or_create_repr_pandas_cache(max_display_count) 9966 pdf_length = len(pdf) 9967 pdf = pdf.iloc[:max_display_count]
/local_disk0/pythonVirtualEnvDirs/virtualEnv-4f2887b9-a4b7-4433-9ec6-5fb3cab7d386/lib/python3.7/site-packages/databricks/koalas/frame.py in _get_or_create_repr_pandas_cache(self, n) 9955 def _get_or_create_repr_pandas_cache(self, n): 9956 if not hasattr(self, "_repr_pandas_cache") or n not in self._repr_pandas_cache: -> 9957 self._repr_pandas_cache = {n: self.head(n + 1)._to_internal_pandas()} 9958 return self._repr_pandas_cache[n] 9959
/local_disk0/pythonVirtualEnvDirs/virtualEnv-4f2887b9-a4b7-4433-9ec6-5fb3cab7d386/lib/python3.7/site-packages/databricks/koalas/frame.py in _to_internal_pandas(self) 9951 This method is for internal use only. 9952 """ -> 9953 return self._internal.to_pandas_frame 9954 9955 def _get_or_create_repr_pandas_cache(self, n):
/local_disk0/pythonVirtualEnvDirs/virtualEnv-4f2887b9-a4b7-4433-9ec6-5fb3cab7d386/lib/python3.7/site-packages/databricks/koalas/utils.py in wrapped_lazy_property(self) 475 def wrapped_lazy_property(self): 476 if not hasattr(self, attr_name): --> 477 setattr(self, attr_name, fn(self)) 478 return getattr(self, attr_name) 479
/local_disk0/pythonVirtualEnvDirs/virtualEnv-4f2887b9-a4b7-4433-9ec6-5fb3cab7d386/lib/python3.7/site-packages/databricks/koalas/internal.py in to_pandas_frame(self) 741 """ Return as pandas DataFrame. """ 742 sdf = self.to_internal_spark_frame --> 743 pdf = sdf.toPandas() 744 if len(pdf) == 0 and len(sdf.schema) > 0: 745 pdf = pdf.astype(
/databricks/spark/python/pyspark/sql/dataframe.py in toPandas(self) 2185 # Rename columns to avoid duplicated column names. 2186 tmp_column_names = ['col_{}'.format(i) for i in range(len(self.columns))] -> 2187 batches = self.toDF(*tmp_column_names)._collectAsArrow() 2188 if len(batches) > 0: 2189 table = pyarrow.Table.from_batches(batches)
/databricks/spark/python/pyspark/sql/dataframe.py in _collectAsArrow(self) 2277 return list(_load_from_socket((port, auth_secret), ArrowStreamSerializer())) 2278 finally: -> 2279 jsocket_auth_server.getResult() # Join serving thread and raise any exceptions 2280 2281 ##########################################################################################
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py in call(self, *args) 1255 answer = self.gateway_client.send_command(command) 1256 return_value = get_return_value( -> 1257 answer, self.gateway_client, self.target_id, self.name) 1258 1259 for temp_arg in temp_args:
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw) 61 def deco(*a, **kw): 62 try: ---> 63 return f(*a, **kw) 64 except py4j.protocol.Py4JJavaError as e: 65 s = e.java_exception.toString()
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name) 326 raise Py4JJavaError( 327 "An error occurred while calling {0}{1}{2}.\n". --> 328 format(target_id, ".", name), value) 329 else: 330 raise Py4JError(
According to the error message, I guess you are using DBR 6.x.
If so, you should do spark.conf.set("spark.sql.execution.arrow.enabled", "false") instead of spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "false") if you want to disable Arrow optimization.
Thanks for the answer,
I tried with spark.conf.set("spark.sql.execution.arrow.enabled", "false") and it run after 38 min it crashed with the error in below. Also it scaled up to 8 worker during the run.
org.apache.spark.SparkException: Job aborted due to stage failure: Task 51 in stage 19.0 failed 4 times, most recent failure: Lost task 51.3 in stage 19.0 (TID 642, 10.152.211.228, executor 0): org.apache.spark.SparkException: Python worker exited unexpectedly (crashed)
Py4JJavaError Traceback (most recent call last) /databricks/python/lib/python3.7/site-packages/IPython/core/formatters.py in call(self, obj) 700 type_pprinters=self.type_printers, 701 deferred_pprinters=self.deferred_printers) --> 702 printer.pretty(obj) 703 printer.flush() 704 return stream.getvalue()
/databricks/python/lib/python3.7/site-packages/IPython/lib/pretty.py in pretty(self, obj) 400 if cls is not object
401 and callable(cls.dict.get('repr')): --> 402 return _repr_pprint(obj, self, cycle) 403 404 return _default_pprint(obj, self, cycle)/databricks/python/lib/python3.7/site-packages/IPython/lib/pretty.py in repr_pprint(obj, p, cycle) 695 """A pprint that just redirects to the normal repr function.""" 696 # Find newlines and replace them with p.break() --> 697 output = repr(obj) 698 for idx,output_line in enumerate(output.splitlines()): 699 if idx:
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/usage_logging/init.py in wrapper(*args, **kwargs) 178 start = time.perf_counter() 179 try: --> 180 res = func(*args, **kwargs) 181 logger.log_success( 182 class_name, function_name, time.perf_counter() - start, signature
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/frame.py in repr(self) 9963 return self._to_internal_pandas().to_string() 9964 -> 9965 pdf = self._get_or_create_repr_pandas_cache(max_display_count) 9966 pdf_length = len(pdf) 9967 pdf = pdf.iloc[:max_display_count]
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/frame.py in _get_or_create_repr_pandas_cache(self, n) 9955 def _get_or_create_repr_pandas_cache(self, n): 9956 if not hasattr(self, "_repr_pandas_cache") or n not in self._repr_pandas_cache: -> 9957 self._repr_pandas_cache = {n: self.head(n + 1)._to_internal_pandas()} 9958 return self._repr_pandas_cache[n] 9959
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/frame.py in _to_internal_pandas(self) 9951 This method is for internal use only. 9952 """ -> 9953 return self._internal.to_pandas_frame 9954 9955 def _get_or_create_repr_pandas_cache(self, n):
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/utils.py in wrapped_lazy_property(self) 475 def wrapped_lazy_property(self): 476 if not hasattr(self, attr_name): --> 477 setattr(self, attr_name, fn(self)) 478 return getattr(self, attr_name) 479
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/internal.py in to_pandas_frame(self) 741 """ Return as pandas DataFrame. """ 742 sdf = self.to_internal_spark_frame --> 743 pdf = sdf.toPandas() 744 if len(pdf) == 0 and len(sdf.schema) > 0: 745 pdf = pdf.astype(
/databricks/spark/python/pyspark/sql/dataframe.py in toPandas(self) 2207 2208 # Below is toPandas without Arrow optimization. -> 2209 pdf = pd.DataFrame.from_records(self.collect(), columns=self.columns) 2210 column_counter = Counter(self.columns) 2211
/databricks/spark/python/pyspark/sql/dataframe.py in collect(self) 553 # Default path used in OSS Spark / for non-DF-ACL clusters: 554 with SCCallSiteSync(self._sc) as css: --> 555 sock_info = self._jdf.collectToPython() 556 return list(_load_from_socket(sock_info, BatchedSerializer(PickleSerializer()))) 557
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py in call(self, *args) 1255 answer = self.gateway_client.send_command(command) 1256 return_value = get_return_value( -> 1257 answer, self.gateway_client, self.target_id, self.name) 1258 1259 for temp_arg in temp_args:
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw) 61 def deco(*a, **kw): 62 try: ---> 63 return f(*a, **kw) 64 except py4j.protocol.Py4JJavaError as e: 65 s = e.java_exception.toString()
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name) 326 raise Py4JJavaError( 327 "An error occurred while calling {0}{1}{2}.\n". --> 328 format(target_id, ".", name), value) 329 else: 330 raise Py4JError(
Py4JJavaError: An error occurred while calling o2341.collectToPython. : org.apache.spark.SparkException: Job aborted due to stage failure: Task 51 in stage 19.0 failed 4 times, most recent failure: Lost task 51.3 in stage 19.0 (TID 642, 10.152.211.228, executor 0): org.apache.spark.SparkException: Python worker exited unexpectedly (crashed) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$3.applyOrElse(PythonRunner.scala:574) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$3.applyOrElse(PythonRunner.scala:563) at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:200) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:144) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:494) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:440) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409) at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:125) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.doRunTask(Task.scala:140) at org.apache.spark.scheduler.Task.run(Task.scala:113) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$17.apply(Executor.scala:606) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1541) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:612) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.io.EOFException at java.io.DataInputStream.readInt(DataInputStream.java:392) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:181) ... 17 more
Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2362) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2350) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2349) at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2349) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:1102) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:1102) at scala.Option.foreach(Option.scala:257) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1102) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2582) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2529) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2517) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:897) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2280) at org.apache.spark.sql.execution.collect.Collector.runSparkJobs(Collector.scala:270) at org.apache.spark.sql.execution.collect.Collector.collect(Collector.scala:280) at org.apache.spark.sql.execution.collect.Collector$.collect(Collector.scala:80) at org.apache.spark.sql.execution.collect.Collector$.collect(Collector.scala:86) at org.apache.spark.sql.execution.ResultCacheManager.getOrComputeResult(ResultCacheManager.scala:508) at org.apache.spark.sql.execution.CollectLimitExec.executeCollectResult(limit.scala:57) at org.apache.spark.sql.Dataset$$anonfun$50.apply(Dataset.scala:3367) at org.apache.spark.sql.Dataset$$anonfun$50.apply(Dataset.scala:3366) at org.apache.spark.sql.Dataset$$anonfun$54.apply(Dataset.scala:3501) at org.apache.spark.sql.Dataset$$anonfun$54.apply(Dataset.scala:3496) at org.apache.spark.sql.execution.SQLExecution$$anonfun$withCustomExecutionEnv$1$$anonfun$apply$1.apply(SQLExecution.scala:112) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:232) at org.apache.spark.sql.execution.SQLExecution$$anonfun$withCustomExecutionEnv$1.apply(SQLExecution.scala:98) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:835) at org.apache.spark.sql.execution.SQLExecution$.withCustomExecutionEnv(SQLExecution.scala:74) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:184) at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$withAction(Dataset.scala:3496) at org.apache.spark.sql.Dataset.collectToPython(Dataset.scala:3366) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380) at py4j.Gateway.invoke(Gateway.java:295) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:251) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.spark.SparkException: Python worker exited unexpectedly (crashed) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$3.applyOrElse(PythonRunner.scala:574) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$3.applyOrElse(PythonRunner.scala:563) at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:200) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:144) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:494) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:440) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409) at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:125) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.doRunTask(Task.scala:140) at org.apache.spark.scheduler.Task.run(Task.scala:113) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$17.apply(Executor.scala:606) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1541) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:612) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ... 1 more Caused by: java.io.EOFException at java.io.DataInputStream.readInt(DataInputStream.java:392) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:181) ... 17 more
Py4JJavaError Traceback (most recent call last) /databricks/python/lib/python3.7/site-packages/IPython/core/formatters.py in call(self, obj) 343 method = get_real_method(obj, self.print_method) 344 if method is not None: --> 345 return method() 346 return None 347 else:
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/usage_logging/init.py in wrapper(*args, **kwargs) 178 start = time.perf_counter() 179 try: --> 180 res = func(*args, **kwargs) 181 logger.log_success( 182 class_name, function_name, time.perf_counter() - start, signature
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/frame.py in repr_html(self) 9986 return self._to_internal_pandas().to_html(notebook=True, bold_rows=bold_rows) 9987 -> 9988 pdf = self._get_or_create_repr_pandas_cache(max_display_count) 9989 pdf_length = len(pdf) 9990 pdf = pdf.iloc[:max_display_count]
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/frame.py in _get_or_create_repr_pandas_cache(self, n) 9955 def _get_or_create_repr_pandas_cache(self, n): 9956 if not hasattr(self, "_repr_pandas_cache") or n not in self._repr_pandas_cache: -> 9957 self._repr_pandas_cache = {n: self.head(n + 1)._to_internal_pandas()} 9958 return self._repr_pandas_cache[n] 9959
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/frame.py in _to_internal_pandas(self) 9951 This method is for internal use only. 9952 """ -> 9953 return self._internal.to_pandas_frame 9954 9955 def _get_or_create_repr_pandas_cache(self, n):
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/utils.py in wrapped_lazy_property(self) 475 def wrapped_lazy_property(self): 476 if not hasattr(self, attr_name): --> 477 setattr(self, attr_name, fn(self)) 478 return getattr(self, attr_name) 479
/local_disk0/pythonVirtualEnvDirs/virtualEnv-08a98497-95e8-475e-8374-626b748e9eba/lib/python3.7/site-packages/databricks/koalas/internal.py in to_pandas_frame(self) 741 """ Return as pandas DataFrame. """ 742 sdf = self.to_internal_spark_frame --> 743 pdf = sdf.toPandas() 744 if len(pdf) == 0 and len(sdf.schema) > 0: 745 pdf = pdf.astype(
/databricks/spark/python/pyspark/sql/dataframe.py in toPandas(self) 2207 2208 # Below is toPandas without Arrow optimization. -> 2209 pdf = pd.DataFrame.from_records(self.collect(), columns=self.columns) 2210 column_counter = Counter(self.columns) 2211
/databricks/spark/python/pyspark/sql/dataframe.py in collect(self) 553 # Default path used in OSS Spark / for non-DF-ACL clusters: 554 with SCCallSiteSync(self._sc) as css: --> 555 sock_info = self._jdf.collectToPython() 556 return list(_load_from_socket(sock_info, BatchedSerializer(PickleSerializer()))) 557
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py in call(self, *args) 1255 answer = self.gateway_client.send_command(command) 1256 return_value = get_return_value( -> 1257 answer, self.gateway_client, self.target_id, self.name) 1258 1259 for temp_arg in temp_args:
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw) 61 def deco(*a, **kw): 62 try: ---> 63 return f(*a, **kw) 64 except py4j.protocol.Py4JJavaError as e: 65 s = e.java_exception.toString()
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name) 326 raise Py4JJavaError( 327 "An error occurred while calling {0}{1}{2}.\n". --> 328 format(target_id, ".", name), value) 329 else: 330 raise Py4JError(
Py4JJavaError: An error occurred while calling o5231.collectToPython. : org.apache.spark.SparkException: Job aborted due to stage failure: Task 191 in stage 23.0 failed 4 times, most recent failure: Lost task 191.3 in stage 23.0 (TID 856, 10.152.212.128, executor 3): org.apache.spark.SparkException: Python worker exited unexpectedly (crashed) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$3.applyOrElse(PythonRunner.scala:574) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$3.applyOrElse(PythonRunner.scala:563) at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:200) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:144) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:494) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:440) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409) at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:125) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.doRunTask(Task.scala:140) at org.apache.spark.scheduler.Task.run(Task.scala:113) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$17.apply(Executor.scala:606) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1541) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:612) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.io.EOFException at java.io.DataInputStream.readInt(DataInputStream.java:392) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:181) ... 17 more
Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:2362) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2350) at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:2349) at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2349) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:1102) at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:1102) at scala.Option.foreach(Option.scala:257) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1102) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2582) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2529) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2517) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:897) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2280) at org.apache.spark.sql.execution.collect.Collector.runSparkJobs(Collector.scala:270) at org.apache.spark.sql.execution.collect.Collector.collect(Collector.scala:280) at org.apache.spark.sql.execution.collect.Collector$.collect(Collector.scala:80) at org.apache.spark.sql.execution.collect.Collector$.collect(Collector.scala:86) at org.apache.spark.sql.execution.ResultCacheManager.getOrComputeResult(ResultCacheManager.scala:508) at org.apache.spark.sql.execution.CollectLimitExec.executeCollectResult(limit.scala:57) at org.apache.spark.sql.Dataset$$anonfun$50.apply(Dataset.scala:3367) at org.apache.spark.sql.Dataset$$anonfun$50.apply(Dataset.scala:3366) at org.apache.spark.sql.Dataset$$anonfun$54.apply(Dataset.scala:3501) at org.apache.spark.sql.Dataset$$anonfun$54.apply(Dataset.scala:3496) at org.apache.spark.sql.execution.SQLExecution$$anonfun$withCustomExecutionEnv$1$$anonfun$apply$1.apply(SQLExecution.scala:112) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:232) at org.apache.spark.sql.execution.SQLExecution$$anonfun$withCustomExecutionEnv$1.apply(SQLExecution.scala:98) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:835) at org.apache.spark.sql.execution.SQLExecution$.withCustomExecutionEnv(SQLExecution.scala:74) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:184) at org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$withAction(Dataset.scala:3496) at org.apache.spark.sql.Dataset.collectToPython(Dataset.scala:3366) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380) at py4j.Gateway.invoke(Gateway.java:295) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:251) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.spark.SparkException: Python worker exited unexpectedly (crashed) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$3.applyOrElse(PythonRunner.scala:574) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$3.applyOrElse(PythonRunner.scala:563) at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:200) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:144) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:494) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:440) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409) at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:125) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.doRunTask(Task.scala:140) at org.apache.spark.scheduler.Task.run(Task.scala:113) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$17.apply(Executor.scala:606) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1541) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:612) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ... 1 more Caused by: java.io.EOFException at java.io.DataInputStream.readInt(DataInputStream.java:392) at org.apache.spark.sql.execution.python.ArrowPythonRunner$$anon$1.read(ArrowPythonRunner.scala:181) ... 17 more