weiboSpider
 weiboSpider copied to clipboard
weiboSpider copied to clipboard
新浪微博爬虫,用python爬取新浪微博数据

- 问:请说明需要什么新功能。 答:想把数据存到postgreSQL数据库里 - 问:请说明添加该功能的意义。(非必填) 答:
- 问:请说明需要什么新功能。 答: 能开发出获取评论的功能么?万分感谢! - 问:请说明添加该功能的意义。(非必填) 答:因为这样可能可以拯救好多人的生命,很多心理有问题的人,好多都是在评论里才找得到
你好,运行spider.py时17行出现问题 from . import config_util, datetime_util ImportError: attempted relative import with no known parent package 包括之后的几行也出现目录错误的问题,我python版本是3.7,求解答
安装时 pip install -r requirements.txt 提示 bash: pip: command not found,请问我是哪里做错了?谢谢!
现有的MongoDB设置文档描述感觉不是很清楚,尤其是"dba_name"和"dba_password"。 当MongoDB只有一个用户时,如果仿照config_sample.json中的格式填入: ``` "mongo_config": { "connection_string": "mongodb://admin:password@localhost:27017/weibo", "dba_name": "admin", "dba_password": "password" } ``` 会产生如下报错: ``` pymongo.errors.OperationFailure: Another user is already authenticated to this database. You must logout first. ``` 将"dba_name"和"dba_password"改为空字符串也会产生同样报错。改为null或移除"dba_name"和"dba_password"均不可行。我自己找到的解决方法是去除uri中的username和password部分,或者在设置文件中将"dba_name"和"dba_password"改为空格`"...
- 问:请说明需要什么新功能。 答:建议增加更小访问量下的等待时间的设置 - 问:请说明添加该功能的意义。(非必填) 答:目前等待时间的设置是在每n页内容爬取完之后的,但一页里面其实就有20个微博,如果微博里面还有图片/视频的话,那1页的访问就会产生30个左右的访问量,很容易造成被随机ban, 所以建议在util.handl_html中追加等待时间的设置,这样可以避免极短时间内大大量访问,避免被随机ban。 我的亲生经历, 爬取13000条左右的微博(大概600多页),如果只用现在的等待时间设置,即便将每页的等待时间设置成2分钟,仍然有可能在爬取200多页的时候被ban。(实际上就是被随机ban了,有时候50多页被ban,也有时候70多页被ban,最多一次大概220多页被ban) 但在util.handl_html中增加了1s的等待时间后,就能顺利爬取到全部微博而不被ban了。 如果结束时间不用now,而用具体日期的话,经常会少爬取到很多微博。
按照readme来获取的cookie,但是还是显示错误或已过期 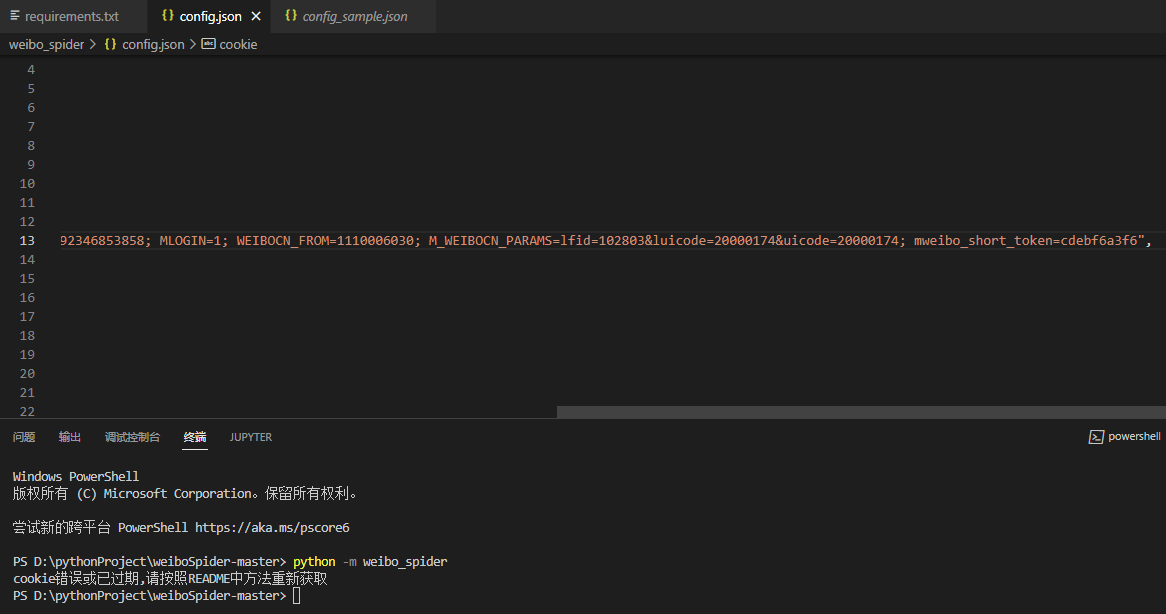
为了更好的解决问题,请认真回答下面的问题。等到问题解决,请及时关闭本issue。 - 问:请您指明哪个版本运行出错(github版/PyPi版/全部)? 答: - 问:您使用的是否是最新的程序(是/否)? 答: - 问:爬取任意用户都会运行出错吗(是/否)? 答: - 问:若只有爬特定微博时才出错,能否提供出错微博的weibo_id或url(非必填)? 答: - 问:若您已提供出错微博的weibo_id或url,可忽略此内容,否则能否提供出错账号的**user_id**及您配置的**since_date**,方便我们定位出错微博(非必填)? 答: - 问:如果方便,请您描述出错详情,最好附上错误提示。 答: