distributed
 distributed copied to clipboard
distributed copied to clipboard
Profiling Scheduler Performance
When running Dask with TLS security turned on, the scheduler can easily become bottlenecked by SSL communication. See the performance report below, in particular the "Scheduler Profile" tab.
https://gistcdn.githack.com/mrocklin/1d24fbac2c66364d8717952ee8827c64/raw/9c87343cb358b54eb26dbfe8b0714120c0f5ad81/report.html
I ran this on my laptop with the following code
import dask
from dask.distributed import Client, performance_report, wait
client = Client(security=True)
dask.config.set({"optimization.fuse.active": False})
df = dask.datasets.timeseries(start="2020-01-01", end="2020-01-31", partition_freq="1h", freq="60s").persist()
with performance_report("report.html"):
df2 = df.set_index("x").persist()
wait(df2)
When this is run on a larger cluster with many workers this problem becomes significantly worse. What are some ways that we can reduce the cost of secure communication?
Hrm, here is another performance report for when security is turned off. Tornado is still a significant cost.
https://gist.githubusercontent.com/mrocklin/5b1e870bc37875f03bf0a6fe0aaec4ba/raw/35cb4a2a803ebe6683f551fed1a17f07fb515c32/insecure.html
OK, I think that this is just down to python's socket.send costs.
I put a timer around the socket.send calls in tornado/iostream.py and came away with
3.37 s / 10764 = 313.11 us
We're spending 300-500us per call and making lots of calls. I can try to batch things a little bit on the worker side but that will only give us a factor increase. I'm curious how we can take communication overhead off of the main thread.
For reference, I got these numbers by instrumenting Tornado in the following way
diff --git a/tornado/iostream.py b/tornado/iostream.py
index 768b404b..f3d000bc 100644
--- a/tornado/iostream.py
+++ b/tornado/iostream.py
@@ -81,6 +81,38 @@ if sys.platform == "darwin":
_WINDOWS = sys.platform.startswith("win")
+
+import contextlib
+from collections import defaultdict
+from time import time
+from dask.utils import format_time
+
+total_time_data = defaultdict(float)
+counts_data = defaultdict(int)
+
+
[email protected]
+def duration(name: str) -> None:
+ start = time()
+
+ yield
+
+ stop = time()
+
+ total_time_data[name] += stop - start
+ counts_data[name] += 1
+
+
+import atexit
+
[email protected]
+def _():
+ for name in total_time_data:
+ duration = total_time_data[name]
+ count = counts_data[name]
+ print(name, format_time(duration), "/", count, "=", format_time(duration / count))
+
+
class StreamClosedError(IOError):
"""Exception raised by `IOStream` methods when the stream is closed.
@@ -1144,7 +1176,8 @@ class IOStream(BaseIOStream):
def write_to_fd(self, data: memoryview) -> int:
try:
- return self.socket.send(data) # type: ignore
+ with duration("send"):
+ return self.socket.send(data) # type: ignore
finally:
# Avoid keeping to data, which can be a memoryview.
# See https://github.com/tornadoweb/tornado/pull/2008
@@ -1564,7 +1597,8 @@ class SSLIOStream(IOStream):
def write_to_fd(self, data: memoryview) -> int:
try:
- return self.socket.send(data) # type: ignore
+ with duration("send"):
+ return self.socket.send(data) # type: ignore
except ssl.SSLError as e:
if e.args[0] == ssl.SSL_ERROR_WANT_WRITE:
# In Python 3.5+, SSLSocket.send raises a WANT_WRITE error if
@pitrou do you have thoughts here on if it is possible to avoid this 300us cost ?
Also, to get a better idea of what's happening, can you print all deciles rather than simply the average? The actual distribution should be insightful.
These numbers are actually with SSL turned off. I realize now that the title of the issue is confusing. I realized when diving into this that this is slow with normal TCP without security, so I've focused on that for now.
And yes, I'll get deciles shortly.
If SSL is turned off and this is a non-blocking socket (as it should be, since we're using Tornado), then the only reasonable explanation is GIL-induced measurement bias. The quantiles should probably help validate this hypothesis.
--------------------
send : 10562 events
0.01 %: 0.95 us
25.0 %: 20.98 us
50.0 %: 35.52 us
75.0 %: 47.21 us
99.9 %: 18.56 ms
This is surprising though. I would expect the 50% value to be around 300us. I'm double-checking the instrumentation.
I'm not surprised. Most calls are quite fast (it's just a non-blocking system call). A small fraction of the calls have to wait for the GIL before returning, and therefore take more than 10 ms.
In other words, you're just seeing the effects of the GIL on performance of a single thread in a multi-thread Python program. System calls like socket.send release the GIL so tend to attract GIL switches on them, which is why they can look so costly :-)
This tooling might be useful to better detect such situations: https://www.maartenbreddels.com/perf/jupyter/python/tracing/gil/2021/01/14/Tracing-the-Python-GIL.html
cc @maartenbreddels
Yeah, you've mentioned that calls like socket.send are likely masking some other call before. I think that this is the first time that I fully understand what is going on. Seeing the quantiles helped me. Thank you for directing me to that.
I'm still left with the question of "what is taking time and making things slow?" I don't have much experience profiling code at this level when the GIL is involved. @maartenbreddels, any suggestions?
I tried to reproduce it locally, but I get a wildly different report, dump of what I've done:
$ pip install distributed==2021.01.0
$ pip install dask==2020.12.0
$ dask-scheduler --host 0.0.0.0
$ dask-worker localhost:8786 --nthreads=3 --nprocs=4 --memory-limit=10G
import dask
from dask.distributed import Client, performance_report, wait
def main(args=None):
client = Client('127.0.0.1:8786')
dask.config.set({"optimization.fuse.active": False})
df = dask.datasets.timeseries(start="2020-01-01", end="2020-01-31", partition_freq="1h", freq="60s").persist()
with performance_report("report.html"):
df2 = df.set_index("x").persist()
wait(df2)
if __name__ == "__main__":
main()
$ /usr/bin/time -v python use_case/dask-scheduler.py dev
Command being timed: "python use_case/dask-scheduler.py"
User time (seconds): 2.02
System time (seconds): 3.61
Percent of CPU this job got: 21%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:26.09
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 133176
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 41883
Voluntary context switches: 3903
Involuntary context switches: 123225
Swaps: 0
File system inputs: 0
File system outputs: 20776
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
Reults in:

Which shows >10x more tasks.
Am I doing something wrong here?
A small fraction of the calls have to wait for the GIL before returning, and therefore take more than 10 ms.
@pitrou Just curious why you think 10ms, I'd guess 5ms from the default of sys.getswitchinterval
System calls like
socket.sendrelease the GIL so tend to attract GIL switches on them, which is why they can look so costly :-)
I've been thinking a bit what the best way is to describe why it is/looks so costly. Would you agree that it's not perse the GIL switch that is costly (e.g the thread context switch is relatively cheap), but that often releasing the GIL in a thread within 5ms, while other threads don't do that (like running pure Python code) will lead that thread too often having to wait for the GIL.
"what is taking time and making things slow?"
I think it is the attempt to return from the (Python) send function, which tries to obtain the GIL. The (Python) send function released the GIL, does the send syscall, which returns in 1us, but wanting to return to Python land, it first needs to acquire the GIL. If other threads are not as eager to release the GIL (such as pure Python code, which will do that only after 5ms, or a long running c-function that does not release the GIL), send will effectively take 5ms.
This is how I understand the situation described in https://bugs.python.org/issue7946 which I've went over a bit in https://github.com/maartenbreddels/fastblog/issues/3#issuecomment-760891430 (comment section of https://www.maartenbreddels.com/perf/jupyter/python/tracing/gil/2021/01/14/Tracing-the-Python-GIL.html )
I think giltracer might tell you if the picture painted here is correct, if that is the case, there are no good solutions I think. Workarounds/bandaids I can think of:
- call a GIL releasing function from the other threads (e.g
time.sleep(0)) to - call/change sys.setswitchinterval
Possibly you may be able to identify a c-function that does not release the GIL (unlikely), or you can make a strong case for doing a c-extension to work around this. This is actually the primary reason I build this tool and wrote the article, I want to make sure before building a C version of a ThreadPoolExector that it's worth it (and still not sure about it).
@pitrou Just curious why you think 10ms, I'd guess 5ms from the default of sys.getswitchinterval
Hmm, yes, you're right. I was thinking about the typical OS timeslice.
Would you agree that it's not perse the GIL switch that is costly (e.g the thread context switch is relatively cheap), but that often releasing the GIL in a thread within 5ms, while other threads don't do that (like running pure Python code) will lead that thread too often having to wait for the GIL.
I don't know if it's "too often". It depends what other threads are doing too. The distribution of durations can tell us how "often" that happens.
there are no good solutions I think
Before finding solutions, one would have to ask the question "does this need solving?". Even if you find ways to balance scheduling between the two Python threads (the one that does IO and the one that runs pure Python code), you'll still be executing the same workload in the same process execution time, just ordered differently.
So the question is: would it improve your overall performance (for example by providing data earlier to other nodes) if you managed to prioritize IO calls before pure Python code in the scheduler process?
I tried to reproduce it locally, but I get a wildly different report, dump of what I've done:
Yes, when I produced the original performance reports I forgot to call wait(df2) inside of the performance_report context manager. I fixed this so that when others ran the example they would get correct results, but I didn't update my wrong results in the links. Your results are more correct.
With regards to thread switching I'm not sure I understand what is happening. My understanding from what I read above is that if you have two threads trading off the GIL there is a multi-millisecond delay in handing off the GIL. This would surprise me. I generally expect lock-style objects to engage in 10us or so in Python. Why would the GIL be so much slower?
Before finding solutions, one would have to ask the question "does this need solving?". Even if you find ways to balance scheduling between the two Python threads (the one that does IO and the one that runs pure Python code), you'll still be executing the same workload in the same process execution time, just ordered differently.
Even if this doesn't improve performance I'm very curious about what would improve performance. I care as much about visibility here as anything else. People today are very curious about how to make the scheduler run faster. They're happy to pour engineering resources into it. Currently they're targetting various aspects of the scheduler, but I'm not confident that we're working in the right place. I am searching for more visibility into what is taking up time.
Another thing we could do here, if it would help, is try to keep the scheduler single-threaded. Currently we intentionally offload compression/decompression to a separate thread. To me this seems like a good idea, but that's because I assumed that engaging multiple threads didn't cause significant GIL issues. The 5-10ms number above has me confused (it's way higher than I would have expected). Would keeping things single-threaded improve performance and/or visibility?
My understanding from what I read above is that if you have two threads trading off the GIL there is a multi-millisecond delay in handing off the GIL.
Releasing the GIL is fast. Acquiring the GIL can lead to waits if the GIL is already held by someone else, which is what is being witnessed here :-)
What socket.send does is:
- release the GIL (fast)
- call the system call
send()to put data on the TCP buffer (medium-fast? a system call is not costless, and depending on the data size the copy may be slightly expensive as well) - acquire the GIL (slow if need to wait for some other thread to release it!)
Even if this doesn't improve performance I'm very curious about what would improve performance.
My opinion is that it would need one or both of these things:
- try to vectorize the scheduling algorithm (as discussed on another issue)
- rewrite the scheduler in another language such as Rust
Both things obviously non-trivial... By the way, given the amount of time that's regularly been consumed in investigating scheduler performance issues (or perceived as such), perhaps the "write in another language" possibility should be explored seriously.
The 5-10ms number above has me confused (it's way higher than I would have expected). Would keeping things single-threaded improve performance and/or visibility?
It would certainly make things easier to understand, but also would give worse performance. Offloading compression probably benefits overall performance, but also makes it slightly less predictable.
try to vectorize the scheduling algorithm (as discussed on another issue)
Yeah, I don't think this is feasible given Dask's execution model.
rewrite the scheduler in another language such as Rust
We're currently using Cython (you might find this work interesting, see recent PRs from @jakirkham). If we need to go to C++ we're open to that, and the state machine logic is being isolated with this option in mind.
However I'm also not convinced that that logic is the slow part of the system. I am comfortable rewriting in C++ if necessary, but I want to avoid the situation where we do that, and then find that it's not significantly faster. John has been able to increase the performance of the tricky scheduling logic considerably (the stuff that I would expect to be slow in Python) but this hasn't resulted in significant performance improvements overall, which has me concerned.
I'm open to moving to a lower level language, but I first want to understand the scope of code that we need to move over to have a good effect.
However I'm also not convinced that that logic is the slow part of the system.
I didn't mean that. There's probably no obvious hot spot (which is why an entire rewrite may be the solution, rather than some select optimizations in Cython).
There are two options for the scheduler, I think:
- Rewrite everything in C++
- Keep the networking and event management in Python, and rewrite only the scheduling logic in C++
Option 2 would be nice, if it makes sense.
My intuition is that the "death of a thousand cuts" that's the main performance limiter applies as much to the networking and event management as to the core scheduling logic.
But don't take my word for it, I haven't tried to profile the dask scheduler in years.
Adding @jcrist , who might find this conversation interesting. I think that he was looking at efficient Python networking recently.
Well one observation I've shared with Ben and maybe you as well is within the Scheduler there are a bunch of sends in transitions themselves. PR ( https://github.com/dask/distributed/pull/4365 ) fixes that by moving the sends out of the transitions and grouping them together. IDK if it would help the issues identified here, but I do think grouping communication a bit more closely together may generally be helpful regardless of what we do next.
Another thing to consider is that when we send a serialized message currently we do a few sends. First to tell how many buffers need to be sent. Next how big those buffers are (with UCX we also include whether they are on the CPU or GPU). Finally the buffers themselves. We may want to figure out how we can aggregate all of these into one message. Admittedly it's not entirely clear how one would do this with TCP. I believe (but could be wrong about this) there is a way to do this with UCX.
I do think grouping communication a bit more closely together may generally be helpful regardless of what we do next.
Agreed.
Another thing to consider is that when we send a serialized message currently we do a few sends.
Does IOStream buffer writes internally? I don't remember.
Sorry responded too quickly. I think we are doing the buffering with BatchedSend. Not sure if Tornado does some buffering as well. Though I must admit that part of the code I don't understand that well 😅
Forgot to add that Scheduler messages themselves usually have a simpler form and so don't necessarily need to be serialized as if they were something more complex (like a DataFrame or Array). Maybe we can exploit this when sending? Some thoughts on that in issue ( https://github.com/dask/distributed/issues/4376 ).
Results from running with you ref_trans2 branch . No strong difference or information here, but I did start adding some more detail in the higher quantiles.
--------------------
send : 15056 events
total 4.61 s
average 305.99 us
0.01 %: 0.95 us
25.0 %: 26.70 us
50.0 %: 37.19 us
75.0 %: 50.07 us
90.0 %: 196.58 us
99.0 %: 6.74 ms
99.9 %: 19.10 ms
Right, so it might make sense to start looking into protecting calling socket.send a ton. However what I'm really learning from this exercise is that socket.send isn't the problem, but rather that there is something else happening on another thread that we need to identify. I can get my laptop to spend 50% of its time on socket.send. I think that this means that some other activity that we don't understand is taking up 50% of our schedulign time.
I've turned off offloading to a separate thread for this. Something else is still going on.
I am comfortable rewriting in C++ if necessary, but I want to avoid the situation where we do that, and then find that it's not significantly faster.
That was the main motivation for the per4m/giltracer experiment, to make more educated decisions on what in Vaex to move to C++ .
I ran the scheduler under giltracer, and my first impression is that the GIL doesn't seem to be a large issue for the scheduler:
PID total(us) no gil%✅ has gil%❗ gil wait%❌
------- ----------- ----------- ------------ -------------
317188* 37572004.8 61.5 37.9 0.7
317278 37514923.8 90.3 0.6 9.1
317813 32484556.5 99.9 0.0 0.1
317814 32483914.5 99.8 0.0 0.1
1 thread needs to wait for the GIL a bit it seems, but I doubt it's a massive issue.
viztracer shows a lot of waiting:

with more zoom-in where the main thread waits for the GIL:

and another zoom-in (where a thread waits):
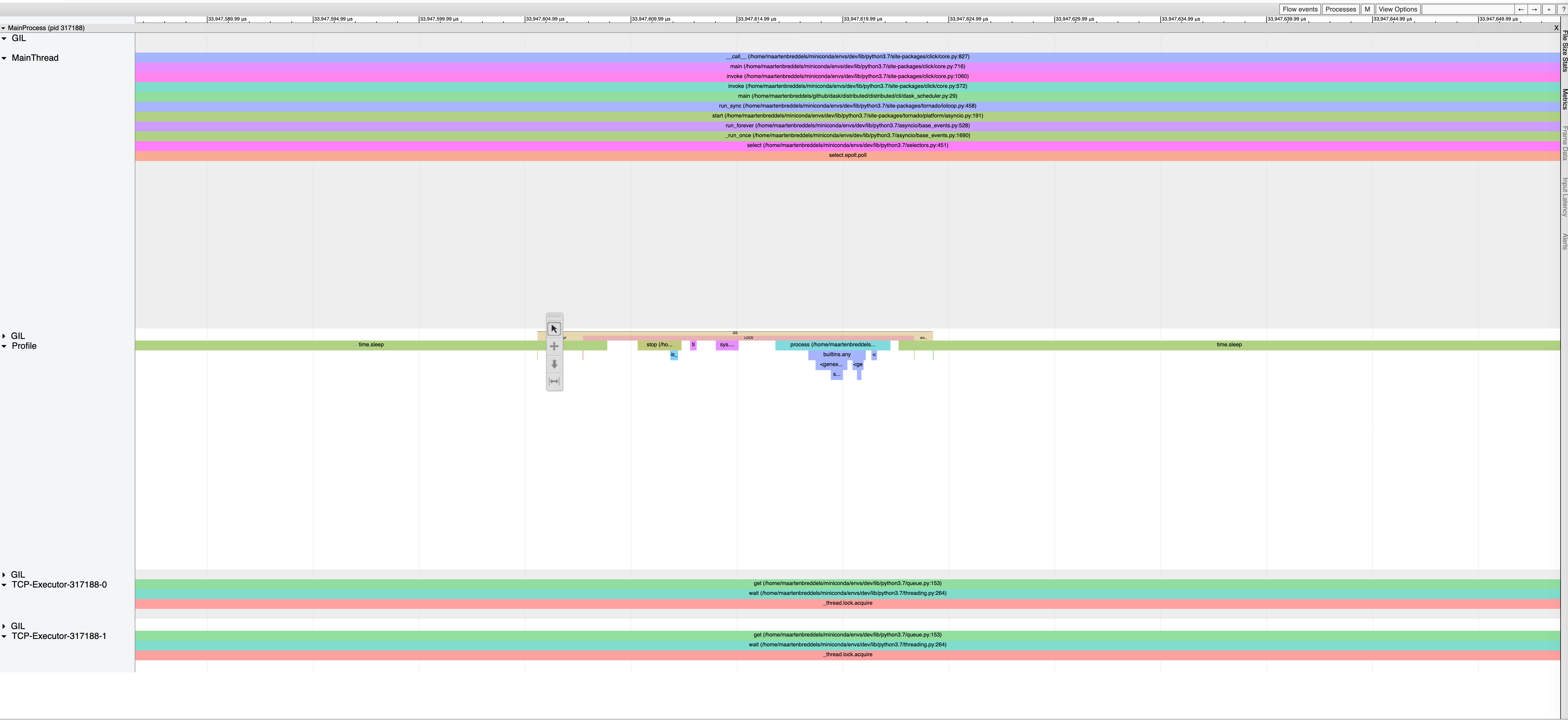
I also only count 400 send calls in the scheduler.
From what I see (just a quick look), I doubt the scheduler is the bottleneck here. Also, I see recognize https://github.com/tornadoweb/tornado/pull/2955 in the output:
