dask
 dask copied to clipboard
dask copied to clipboard
Blockwise optimization doesn't combine task names, like low-level fusion does
Users may be confused why tasks that they expect to run don't show up on the dashboard.
With low-level fusion, we concatenate the names of all the tasks together, so at least the name of the task (like read_csv-assign-getitem-add) gives you some hint that all those things are still happening. But with blockwise fusion, that same task would just be named add, which gives you no indication that your read_csv, assign, or getitem are contained within it.
In [1]: import dask.dataframe as dd
# long, all-blockwise operation
In [2]: df = dd.demo.make_timeseries().assign(z=lambda df: df.x + df.y).pipe(lambda df: df[["x", "y", "z"]] + 1)
In [3]: import distributed
In [4]: client = distributed.Client()
In [4]: pdf = df.persist()
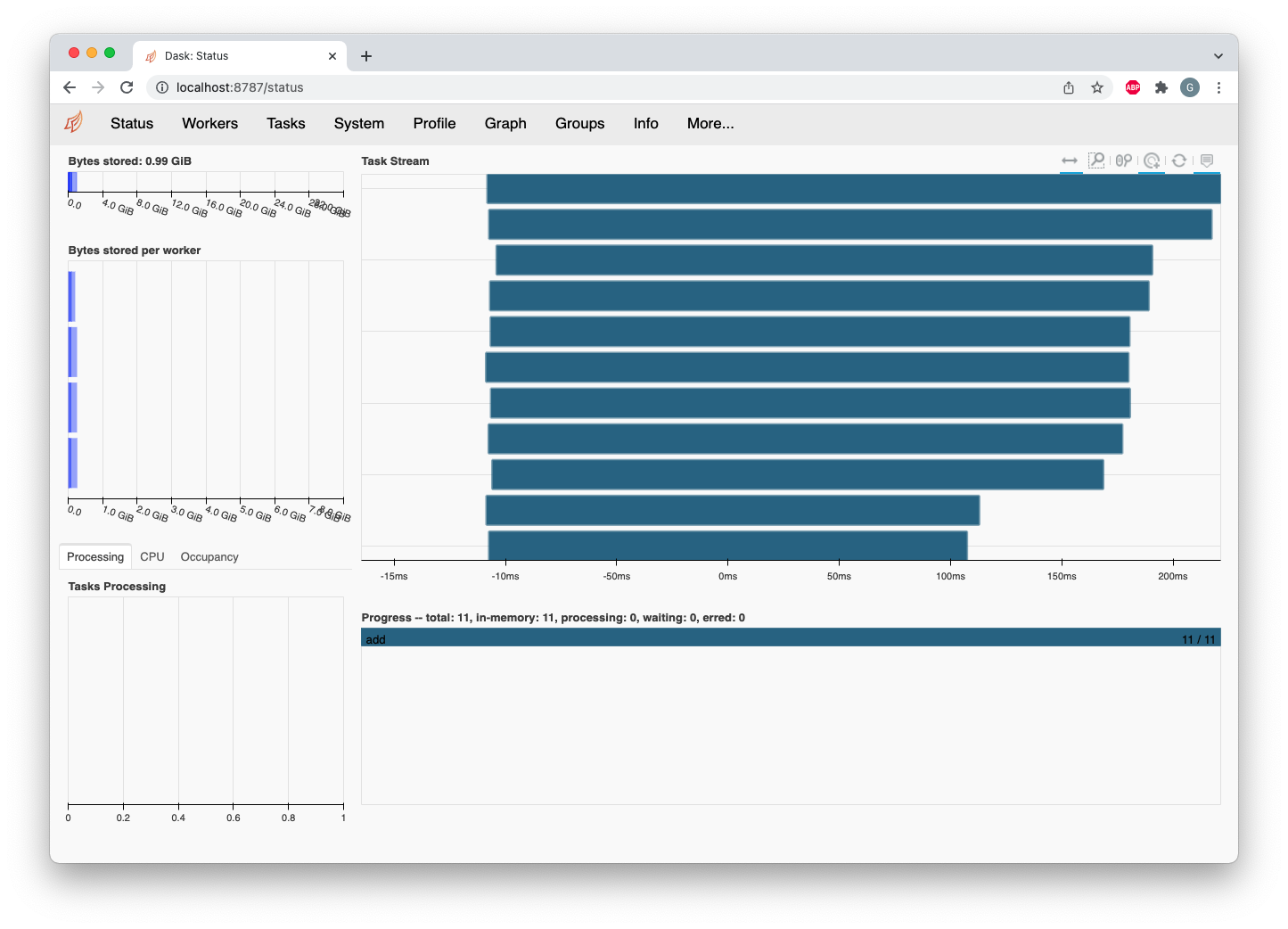
On the dashboard, the tasks just show up as add, so you might be confused what happened to all the other operations.
This could arguably be solved with better documentation (xref https://github.com/dask/dask/issues/8627), but I do think having the concatenated names is more user-friendly than having to find some obscure docs to understand this.
However, I recognize that if you change the name of the layer, you also have to change the names referenced in the dependent layers. That's just not currently possible with HLG layers—we could feasibly do it to MaterializedLayers, but in general, there's no rename_input_key interface on a Layer.
Furthermore, this is actually slightly violating the scheduler's assumptions about TaskPrefix keys. In my example above, the scheduler is going to learn a duration estimate for add tasks which actually includes that whole chain of operations, and will be quite wrong if I later submit (df + 1).compute().
Maybe we could add a task-group-key and task-prefix-key annotation to the rewritten layer, which the scheduler would recognize and use instead of key_split and key_split_group (and would ultimately be displayed on the dashboard)?
cc @rjzamora @jrbourbeau
I'm +1 on on having the concatenated name -- this information is really useful when debugging and trying to understand performance or what happened and when
Ah, right. I knew that blockwise fusion didn't change the name, but I didn't realize that "low-level" fusion actually did. In that case, we are indeed making the dashboard less intuitive with the move to blockwise fusion everywhere possible :/
I think your general idea to get the necessary information to the scheduler makes sense. Challenges like this are also making me wonder how much simpler things would be if we took the approach of #8633 for (non-culling) optimizations in general, and just applied optimizations like fusion eagerly as soon as a "fusable" layer was added to a collection. If we took that approach, we have the option of setting the name to whatever we want, because no dependencies exist yet.
Eager fusion seems reasonable to me. It probably simplifies the optimization code a bit too, and makes len(dsk) and the task counts show in reprs much more realistic.
I'm not sure how much of an undertaking that'll be, though? It probably requires changing every place where Blockwise layers are constructed, and explicitly deriving them from the previous layer. Naively, both this and https://github.com/dask/dask/pull/8633 would require every place where graph-construction code is written to "opt in" to this optimization; it wouldn't be applied automatically. This would even further increase the barrier to using HLGs effectively.
The better approach might be adding a framework to HighLevelGraph.from_collections for applying eager optimizations in some way. So there'd be compute-time full-graph optimizations as usual, and a new set of optimizations that can be applied at HLG construction time.
Either way, I bet it'll also break a lot of current tests :)
Since this seems like a moderately large undertaking, should we consider adding support for a task-group-key and task-prefix-key annotation on the scheduler for now as a stopgap?
Since this seems like a moderately large undertaking, should we consider adding support for a task-group-key and task-prefix-key annotation on the scheduler for now as a stopgap?
Right - Although eager optimizations may be pretty easy to implement, it would be a large enough change to require serious discussion. I can also imagine a few ugly edge cases and assume that many existing tests would break for sure :)
As long as the stopgap doesn't get out of hand, I agree that we shouldn't rely on eager optimizations yet (just wanted to highlight this as a posible motivation).
Just want to note that I've been using Dask to do some "actual data science" for the past few hours, and I've been repeatedly thrown off by misleading task names on the dashboard. Wondering things like "why is my cluster OOMing trying to do df.size.compute()," only to realize much later that size is fused onto the end of a shuffle, and the OOMing is actually because I've picked bad divisions for my set_index. As a normal user, I'd be so confused by this, and would probably never be able to figure it out. The dashboard loses a lot of its value when the names of tasks are somewhat meaningless.
I think we should consider this higher priority. As unappetizing as it is, https://github.com/dask/distributed/issues/5742 seems like a pretty easy fix to the UX problem right now.
Just noting again that we're seeing users in real life run into this. It makes it difficult to understand or diagnose performance at a glance when you think a task is one thing, but is actually something else.
xref There is also an actual functional problem with this besides mere UX https://github.com/dask/dask/issues/9888