dask-sql
 dask-sql copied to clipboard
dask-sql copied to clipboard
[QST] Remove SQL compatibility null handling from join code?
What is your question?
TLDR - there's some costly null handing in our join code to maintain SQL compatibility - should we remove this like we did with groupby null handling?
In #290, we had some discussion around the extent to which Dask-SQL should perform costly workarounds to maintain SQL compatibility - in that case, it was null-splitting operations happening for groupbys to maintain a specific null ordering, and we opted to remove this in general cases in #273.
Following up on that, another area where I notice we are doing costly workarounds to maintain SQL null handling is our _join_on_columns utility - in particular, we run an isna on all the join-by columns, picking out all null values so they won't return in the result:
https://github.com/dask-contrib/dask-sql/blob/5beaf35c7bdebe6626d3cf8d7217a00672b0bdbe/dask_sql/physical/rel/logical/join.py#L215-L226
Removing this check reduces our HLG for a standard join by a decent amount:
import cudf
import dask.dataframe as dd
from dask_sql import Context
c = Context()
df1 = cudf.DataFrame({"a": [1, 2, 3, 4, 5], "b": [6, None, 7, None, 8]})
df2 = cudf.DataFrame({"c": [6, 7, None, None, None], "d": [11, 12, 13, 14, 15]})
c.create_table("lhs", df1)
c.create_table("rhs", df2)
c.sql("SELECT * FROM lhs JOIN rhs ON b = c")
With null handling:
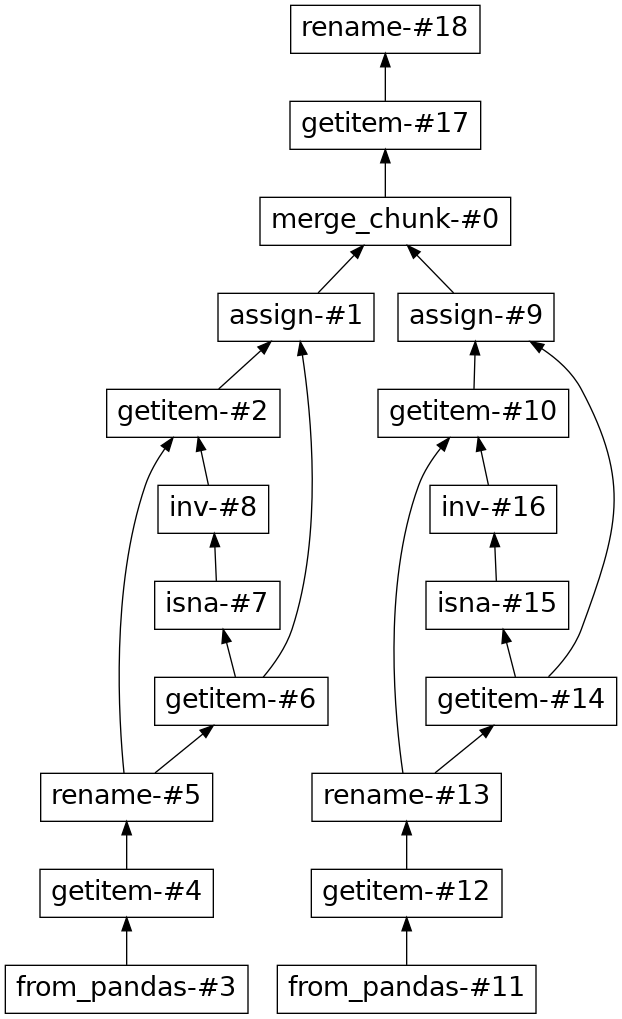
And without:
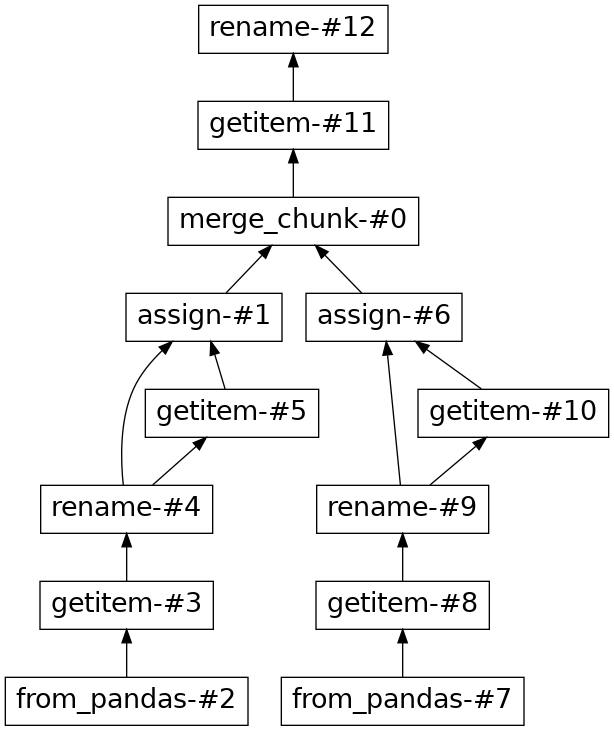
And similar to GROUP BY statements, there is a way for users to achieve a SQL compatible result, by performing a follow up WHERE filter after the initial JOIN to remove the null rows.
I'm interested in thoughts on removing this code, and modifying our compatibility tests to use the user workaround.
One difficulty I'm encountering in removing this code is that Calcite's SQL parser actually implicitly does its own optimizations if you add IS [NOT] NULL conditions to joins - for example, something like:
SELECT * FROM df1 JOIN df2 ON (
df1.b = df2.b AND df1.b IS NOT NULL
)
Would ignore the df1.b IS NOT NULL since a join operation "shouldn't" have nulls in its result. On top of forcing users to use explicit WHERE statements to filter out nulls from a join operation, this is also confusing behavior, as I imagine some users would use the above approach to drop nulls from a join and be surprised when it has no effect.
cc @jdye64 as we spoke about this