Proposal: Support batching of send and receive pub/sub messages for performance
The current PubSub model notifies consumers by making a roundtrip per message. A way to improve message throughput would be to allow consumers to declare the intention of consuming messages in batches. Processing messages in batches lead to the following optimizations:
- roundtrip reduction between dapr and consuming component by sending messages batches
- consumer computation by observing a message batch instead of a single item
Expected behavior: Subscribers can (optionally) choose to receive messages in batches.
Example of a subscriber's response where batching is requested:
{
"subscriptions": [
{
"topic": "A",
"maxBatchSize": "10"
}
]
}
The optional parameter maxBatchSize defines the maximum number of messages to be delivered in a single receive loop. By default, maxBatchSize should be 1.
Message checkpointing in batch mode are for all messages (all succeeded or failed).
Distributed tracing should track each message inside the batch in such a way that users can still find them in the target telemetry backend. In other words, if messages A, B and C were processed in the same batch, searching for message B telemetry should return the batch execution.
In order to enable receiving multiple messages the subscriber callback contract could be changed from:
// NewMessage is an event arriving from a message bus instance
type NewMessage struct {
Data []byte `json:"data"`
Topic string `json:"topic"`
Metadata map[string]string `json:"metadata"`
}
to
// Message is one event arriving from a message bus instance
type Message struct {
Data []byte `json:"data"`
Metadata map[string]string `json:"metadata"`
}
// NewMessages contains one or more events arriving from a message bus instance for a given topic
type NewMessages struct {
Messages []Message `json:"messages"`
Topic string `json:"topic"`
}
Impact
- Components Contrib: each implementation needs to handle the new property (impact on certification), defaults to "1" otherwise. Still need to change code so it can return an array of 1 and avoid compilation error.
- For GRPC, this is a breaking change given the change in proto change. Any example for GRPC will need to be fixed in every SDK as well.
- For HTTP, we can make use of the lack of structure and send the payload to subscriber as-is (CloudEvent) when batch size is configured to 1. When batch size is configured to greater value, the payload to subscriber is an array of CloudEvent.
Parent: #843 Note: At time of code checkin, submit a docs PR on this issue https://github.com/dapr/docs/issues/2407
@yaron2 @youngbupark @mukundansundar @msfussell This looks like a P1 to me. What do you think?
@yaron2 @youngbupark @mukundansundar @msfussell This looks like a P1 to me. What do you think?
I would like to see this as a P1 because it can drastically improve throughput and open up more high scale scenarios that rely on pub/sub.
Removing the breaking change label because the solution to this issue cannot be a breaking change anymore.
@yaron2 - any update of this feature? Especially interested for using with Azure EventHub adapter.
Dapr Pub/Sub Batching API Proposal
Requirements
Summarizing some requirements presented from earlier in this issue:
- Add an optional parameter
maxBatchSizedefines the maximum number of messages to be delivered in a single receive loop. - Distributed tracing should track each message inside the batch in such a way that users can still find them in the target telemetry backend.
- Pubsub batching feature cannot be a breaking API change.
One previously stated requirement that this proposal will not support is:
- Message check-pointing in batch mode are for all messages (all succeeded or failed).
We will discuss the issues with message acknowledgements and error handling separately in the API proposal sections below.
Additional Design Considerations
Although the initial issue description primarily discusses batch subscriptions, this proposal expands the discussion to include a Dapr batch publish API as well. It should be noted that:
- Batch publishing and batch subscribing are orthogonal APIs: some brokers support only one but not the other in their SDKs, and Dapr can similarly choose to provide either or both of them, which may vary by underlying component support.
- For a component that supports both batch publish and batch subscribe, a batch published through Dapr is not the same as a batch received through Dapr: any batch publish abstraction Dapr creates terminates at the broker, where its individual messages may be pushed to subscribers in a different assortment and batch size.
As such, this proposal treats the batch publish and subscribe APIs as largely independent of each other.
For both batch publish and subscribe APIs, the primary motivation for adding them is to improve the throughput of message processing in the system. It's useful to keep the performance reason in mind because it's possible to provide the batch APIs as a facade that may be counterproductive from a performance tuning perspective.
Specifically because of the architecture of Dapr, the Dapr APIs themselves incur an extra bit of latency between the Dapr sidecar and the app (compared to SDKs running in-proc with the app), in addition to the more significant roundtrip latency between Dapr and the broker service itself that is possibly in a different locality (such as a cloud provider). Effectively, there are two opportunities for batching benefits in any given pubsub request:
- Between the app (🟪) and the Dapr sidecar (🔷): determined by the Dapr API definition.
- Between the Dapr sidecar (🔷) and the broker (⚫): determined by the broker SDK support used in the pubsub component.
Considering the matrix of batch publishing scenarios depending on whether each is supported:
- 🟪⇉🔷⇉⚫: The existing behavior is simply that Dapr processes each message one-at-a-time and sends it to the broker that way.
- 🟪⇉🔷⇛⚫: Dapr does not provide a batch publish API, but the broker component can be configured to batch multiple messages implicitly for performance.
- e.g. GCP pubsub's SDK provides such an option.
- This may have robustness issues if Dapr does not know the underlying SDK is implicitly batching. If Dapr acknowledges each message synchronously but the broker SDK may not have sent the messages yet, a crash of the Dapr sidecar will cause those messages to be silently lost. This proposal does not address options related to this scenario given those concerns.
- 🟪⇛🔷⇉⚫: Dapr provides a batch publish API for brokers that do not in their SDK.
- This still has potential performance benefits though likely smaller gains relative to the broker support for it.
- Aside from the performance consideration, Dapr would like to support this case as a dev experience benefit, since a consistent API surface help makes the code more portable between different brokers.
- 🟪⇛🔷⇛⚫: Dapr allows apps to utilize batch publish functionality native to specific brokers.
- This seems to be a key scenario to support, as Dapr should not make a dev choose between effectively using a component, and using the component with Dapr.
Similarly, considering the batch receiving APIs:
- ⚫⇉🔷⇉🟪: Existing receiver handling behavior where messages are processed individually.
- ⚫⇛🔷⇉🟪: Dapr does not provide a batch receive API, but the broker component can be configured to fetch multiple messages at a time for performance.
- This encompasses more than strictly batching, but many of the existing pubsub components configure some kind of prefetching or queuing already, so the component implementations have some ability to optimize the longer leg of the latency without Dapr having to provide a batch receive API.
- This is out of scope for this proposal as component-specific optimizations that can be made independent of Dapr.
- ⚫⇉🔷⇛🟪: Dapr provides a batch receive API for brokers that do not in their SDK.
- Dapr would like to support this for the same code portability reasons as the publishing case.
- It turns out that very few broker SDKs provide an API for this, though there may be affordances provided for an app to batch acknowledge messages delivered individually.
- ⚫⇛🔷⇛🟪: Dapr allows apps to utilize batch receive functionality native to specific brokers.
- This is important to support for the same reasons as batch publishing, although compared to the publishing scenario, there are fewer components that natively support this.
The design proposals that follow :
- focus on supporting brokers that expose batching APIs (🟪⇛🔷⇛⚫ | ⚫⇛🔷⇛🟪).
- discuss supporting Dapr APIs without native broker integration as an extension (🟪⇛🔷⇉⚫ | ⚫⇉🔷⇛🟪).
Proposed Batch Publish API
Each SDK provides a convenience wrapper for creating a list of CloudEvents on behalf of the app.
from dapr.clients import DaprClient
with DaprClient() as d:
req_data = [
{'workplace-accidents': '0'},
{'workplace-accidents': '1'},
{'workplace-accidents': '352'}
]
# New method to publish batch of events to a topic
resp = d.publish_events(
pubsub_name='pubsub’,
topic='deathStarStatus’,
data=json.dumps(req_data)
)
# Print the request
print(req_data, flush=True)
There will be a new HTTP endpoint to handle the batch publish:
curl -X "POST" http://localhost:3500/v1.0/publish/batch/pubsub/deathStarStatus -H "Content-Type: application/json" -d '@data.json'
Variant: Reuse the existing HTTP endpoint:
curl -X "POST" http://localhost:3500/v1.0/publish/pubsub/deathStarStatus -H "Content-Type: application/json" -d '@data.json'
- Cons: There would still need to be a new, separate GRPC proto definition for batch publish, to avoid breaking the existing proto definition, so reusing the same endpoint breaks API parity between HTTP and GRPC.
The data.json file provided to the call contains a list of CloudEvents:
[
{
"specversion": "1.0",
"type": "com.dapr.event.sent",
"source": "https://the.empire.com/logistics",
"id": "a1c8c741-0e7c-46d7-afba-06f02aa9b1fb",
"pubsubname": "pubsub",
"topic": "deathStarStatus",
"traceid": "00-2583c3e5f33c8db92a2ba0e3488a6a63-328e7491ec6678de-01",
"datacontenttype": "application/json",
"data": {
"workplace-accidents": "0"
}
},
{
"specversion": "1.0",
"type": "com.dapr.event.sent",
"source": "https://the.empire.com/logistics",
"id": "632078ee-ed6a-4055-9f1f-a66b5c3a5c2d",
"pubsubname": "pubsub",
"topic": "deathStarStatus",
"traceid": "24-9eba4a91b94b22a0a5f39d9d12bb3de2-28fdc016724ac48a-fb",
"datacontenttype": "application/json",
"data": {
"workplace-accidents": "1"
}
},
{
"specversion": "1.0",
"type": "com.dapr.event.sent",
"source": "https://the.empire.com/logistics",
"id": "e2d39297-e605-486d-a8f9-54791383f3c6",
"pubsubname": "pubsub",
"topic": "deathStarStatus",
"traceid": "50-ab8f8650bcb552827b65af4e208b1478-32331abc36eed07a-1a",
"datacontenttype": "application/json",
"data": {
"workplace-accidents": "352"
}
}
]
Variant: Additionally provide a convenience HTTP endpoint that wraps batch of data with common
pubsubname,topic&metadatainto individual CloudEvents:curl -X "POST" http://localhost:3500/v1.0/publish/batch/pubsub/deathStarStatus -H "Content-Type: application/json" -d '[{'workplace-accidents': '0'},{'workplace-accidents': '1'},{'workplace-accidents': '352'}]'
- Cons: Assumes
datais JSON that can be enumerated by Dapr runtime. Adds bloat to the API surface, keeping in mind there would also need be an additional GRPC proto definition.
A couple of things to call out here:
- Individual CloudEvents in the batch may use binary-encoded data (
application/octet-stream) like regular messages. - The
topicandpubsubnameshould be the same for all events in the batch that match the endpoint.- In general, the broker APIs that support batch publish do not support publishing across topics in a batch, and Dapr would not want to support cross-publishing to different pubsubs in a single batch.
-
traceidfor a batch may be the same as for all messages in the batch (if all CloudEvent envelopes are generated by a Dapr SDK from the same context of the batch publish call) but does not have to be (if the app is providing custom CloudEvents viaapplication/cloudevents+json)
A batch publish will not be treated as a single transaction i.e. individual messages in a batch could succeed or fail. The underlying broker batch publish APIs seem to vary significantly in their error contracts that can range from:
- Returns a single error on batch operation (Azure Event Hubs).
- Returns a single error on first failed message in a batch (Azure Service Bus).
- Returns information on individual message success/failure (Kafka, if configured for it).
In order to support brokers that return individual success/failure on a batch, the Dapr batch publish API would also produce a HTTP response mapping the CloudEvent IDs to statuses, for example:
{
"statuses": [
{"id": "a1c8c741-0e7c-46d7-afba-06f02aa9b1fb", "status": "SUCCESS"},
{"id": "632078ee-ed6a-4055-9f1f-a66b5c3a5c2d", "status": "FAIL"},
{"id": "e2d39297-e605-486d-a8f9-54791383f3c6", "status": "SUCCESS"}
]
}
If any message status is a failure, the HTTP response code for the batch operation will be a failure.
In the case where the underlying broker neither provides transactional semantics (all pass/fail only) or granular pass/fail information, Dapr may attempt to infer which messages failed (e.g. assuming messages are processed in order of the batch and having the ID of the first failed message), but will err on the side of duplicate publishing (i.e. marking a successfully published message as failed so that the app retries).
Proposed publish feature interactions
- Batch publish will support TTL settings.
- The TTL can be different per message in the batch if using the HTTP endpoint and providing the CloudEvents directly, but we would probably only provide simplified SDK methods that set the TTL on a per-batch basis like the
topicandpubsubname.
- The TTL can be different per message in the batch if using the HTTP endpoint and providing the CloudEvents directly, but we would probably only provide simplified SDK methods that set the TTL on a per-batch basis like the
- Batch publish will not support raw payloads.
- As an initial simplification, Dapr relies on the CloudEvent envelope for each payload to enumerate the batch, which in its raw form could be binary data. We also rely on the CloudEvent ID for response status mapping to messages.
Candidate components with Go SDK to support batch publish
- Kafka (SyncProducer.SendMessages)
- Azure Service Bus (Topic.SendBatch)
- Azure Event Hubs (Hub.SendBatch) (Note: contingent on https://github.com/dapr/components-contrib/issues/951)
- GCP PubSub (Configure Topic.Publish batch options on each Publish)
- HazelCast (PublishAll)
Dapr batch publish without broker support
This can be added on given that Dapr batch publish does not provide transactional semantics on batch publish; the batch can be broken into individual messages and published iteratively, and the publish API is amenable to this as a fundamentally synchronous function call.
If Dapr wants to provide transactional semantics over a batch, then this becomes much harder to support independent of the broker - Dapr essentially has no way of ensuring all-or-nothing publishing unless the broker supports it in some capacity.
Proposed Batch Subscribe and Receive APIs
Subscribing declaratively using the Dapr Subscription CRD will indicate the batching configuration with a metadata property so that the subscription definition can be reused:
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: mySubscriber
spec:
subscriptions:
- pubsubname: pubsub
topic: deathStarStatus
route: /dsstatus
metadata:
maxbatchsize: 10
scopes:
- app1
- app2
Providing discovery of the subscription programmatically and handling the resulting batch call in code:
import flask
from flask import request, jsonify
from flask_cors import CORS
import json
import sys
app = flask.Flask(__name__)
CORS(app)
@app.route('/dapr/subscribe', methods=['GET'])
def subscribe():
subscriptions = [{'pubsubname': 'pubsub',
'topic': 'deathStarStatus',
'route': 'dsstatus',
'metadata': {
'maxbatchsize': '10',
}}]
return jsonify(subscriptions)
# Subscriptions with `maxbatchsize` should be routed to a new batch handler method
@app.route('/dsstatus/batch', methods=['POST'])
def dsstatus_subscriber():
print(f'dsstatus: {request.json}', flush=True)
response = { 'statuses':[] }
for msg in request.json['data']:
# Each msg in batch data is a CloudEvent
print('Processed message "{}" from topic "{}" with info "{}"'.format(
msg['id'], msg['topic'], msg['data']['workplace-accidents']),
flush=True)
# The app needs to track a status for each message and they can fail individually
response['statuses'].append({'id':msg['id'],'status':'SUCCESS'})
return json.dumps(response), 200, {'ContentType':'application/json'}
app.run()
Note that the HTTP status code only applies to the overall batch call:
- HTTP status code should only be set to 200 if all messages have status
SUCCESS - Any non-2xx HTTP status code is treated as failure and the action taken by Dapr is determined by the per message
status.- This is unlike the existing single message subscribe handling, where the
statusin the response body is optional and the HTTP status can be used instead.
- This is unlike the existing single message subscribe handling, where the
- If any
statusisRETRYor an error, the app may received all messages in the batch again depending on the granularity of ACK expected by the broker.- This is acceptable under the "at-least-once" semantics provided by Dapr pubsub.
The batch topic request will itself be a simple CloudEvent wrapper around the list of CloudEvents in the batch:
{
"specversion": "1.0",
"type": "com.dapr.event.sent.batch",
"source": "https://the.empire.com/logistics",
"id": "b90443c3-8607-4873-8e80-ac9a674e0648",
"traceid": "50-ab8f8650bcb552827b65af4e208b1478-32331abc36eed07a-1a",
"datacontenttype": "application/json",
"data": {
// Individual CloudEvents as in data.json ...
}
}
Also note that depending on the broker, the batch may only consist of a single message (maxbatchsize does not require the min to be > 1), and the double CloudEvent envelope can make this route less efficient if that is consistently the case.
To support GRPC, there will be a new GRPC proto defintion for OnTopicEvents that take new input TopicEventsRequest and returns new TopicEventsReponse types analogous to the request and response structures suggested for HTTP.
Proposed subscription feature interactions
- Batch subscribe will not support CloudEvent filtering (see #2582).
- Breaking apart a batch from a broker to re-queue into per route batches in the Dapr runtime introduces complexity and robustness challenges similar to Dapr batching without broker support.
- Batch subscribe will not support raw payloads.
- As an initial simplification, Dapr relies on the CloudEvent envelope for each payload to enumerate the batch, which in its raw form could be binary data. We also rely on the CloudEvent ID for response status mapping to messages.
- Batch subscribe will support TTL.
- Dapr runtime will scan the batch and drop individual events from the batch with expired TTL values.
- Batch subscribe will support dead-letter topics (see #2217).
- Given success/fail responses for individual messages from the client, each failed message can be routed to the DLQ.
Candidate components with Go SDK to support batch subscribe
- Redis (Polling with XREADGROUP and COUNT)
- AWS SNS/SQS (SNS ReceiveMessageInput configured with messageMaxNumber already, hard limit of 10/batch)
- Azure Event Hubs (Hub.Receive with ReceiveWithPrefetchCount) (Note: contingent on https://github.com/dapr/components-contrib/issues/951)
Some additional components that are likely candidates with known issues:
- Kafka (supports batching via Consumer.Fetch.Min, but it is only configurable by bytes not message count).
- Azure Service Bus (.NET SDK supports Subscription.ReceiveBatch, but not the Go SDK).
Dapr batch subscribe without broker support
In theory, this is possible with some minimal tradeoff in per-message delivery latency (i.e. Dapr simply accumulates a set of messages before calling the app to handle as a batch), but there wind up being several complicating factors in the design:
-
Dapr needs to manage its own batching thresholds for received messages in the absence of broker support
- Unlike a batch publish call which consists of a single, synchronous invocation to Dapr, when batching reception of messages, Dapr is usually waiting across multiple calls to itself.
- This means that Dapr needs to manage the max latency between receiving an event and sending out a batch of events, when it is not just the broker sending it a batch in a single request.
- Since this is ostensibly a performance-oriented feature, that latency needs to be tunable by the developer and exposed as part of the API as well. To that end, Dapr should expose a set of threshold metadata properties as part of the batch subscription definition as well. For example:
-
countThreshold: the threshold number of received messages that would trigger the app batch receive handler. -
bytesThreshold: the bytes threshold for received messages that would trigger the app batch receive handler. -
delayThresholdInMs: the maximum time in ms between a message being received and that message being sent to the batch receive handler.
-
Opens: If these parameters are introduced, should
maxbatchsizebe replaced bycountThreshold? My inclination is that they both need to be supported, being semantically different (countThresholdeffectively being the min batch size).I mention
bytesThresholdhere specifically for its affinity to Kafka and itsConsumer.Fetch.Minbut at the Dapr layer, it's not clear that support can be generalized across pubsub components for both count and byte size, and it may be difficult to rationalize to the dev when they're getting native behavior from the broker in one case, but a Dapr provided behavior in another. Overall, introducing more parameters into the design makes it more complicated for a developer to navigate, and subsequently tune efficiently. -
Dapr batched receiving interacts with component configuration in ways that make it non-portable
- Many broker SDK affordances to allow an app to batch process a set of individually delivered messages and acknowledge in a batch don't translate cleanly when used by Dapr because it is a middleman, not the acknowledging consumer.
- For robustness reasons, Dapr cannot ACK on behalf of an app while it is batching messages, because the Dapr sidecar crashing at that point would mean that the messages never get delivered.
- This means that Dapr must keep un-acked messages in-flight and alive while batching and then also while waiting for the app to reply to the batched messages. (e.g. by renewing lock extensions etc.)
- This ends up creating interactions between component configurations that manage component-specific properties related to ACKs and the receive queue, and the Dapr batch receive properties such as
maxbatchsizeor the proposed threshold properties likedelayThresholdInMs. - For example, NATS streaming already exposes
ackWaitTimeandmaxInFlightas component configuration today, and you could create worse performance outcomes with acountThreshold>maxInFlight, orackWaitTimeis too short relative todelayThresholdInMsand triggering a lot of unnecessary redeliveries.
- This ends up creating interactions between component configurations that manage component-specific properties related to ACKs and the receive queue, and the Dapr batch receive properties such as
- These interactions create a leaky abstraction where the Dapr batch receive API can violate the principle of least astonishment when changing component configurations or switching to a different component.
Opens: The possibility of a developer easily creating worse performance outcomes when using this feature makes me hesitant to recommend supporting it unless the community can suggest good guardrails for this.
Also, there's sufficient additional complexity in supporting this that it may be worthwhile to treat the exploration of a general Dapr batch receive API as an extension feature.
- Many broker SDK affordances to allow an app to batch process a set of individually delivered messages and acknowledge in a batch don't translate cleanly when used by Dapr because it is a middleman, not the acknowledging consumer.
Alternative Approaches
Instead of providing a Dapr pubsub batching API, there are a couple of alternative approaches that could be used to batch send/receive requests to/from a broker. For completeness, they are touched upon here, though they are beyond the scope presented in this issue and should be elaborated on elsewhere.
-
Add support for stream processing
- By exposing primitives for stream processing (e.g. websocket sessions), Dapr can provide the building blocks for apps to manage their own batching from brokers that many not support it in their API, and also enable other scenarios beyond pubsub batching.
- There limitations to a HTTP-based batching API such as timeouts and request size limits which would make the proposed implementation of a Dapr pubsub batching API inefficient for its stated purpose.
- A variant of this proposal is to only support batching for the GRPC transport and not HTTP. Based on the design principles of Dapr though, this is likely a non-starter until a broader discussion about maintaining HTTP/GRPC API parity happens.
- Considered out-of-scope for the purposes of this discussion; adding a pubsub batching API does no preclude support for stream processing later, and may provide an intentionally simplified experience even when stream processing is added.
-
Implement batching as bindings for brokers that support it
- Instead of making it a general feature of pubsub that may not be broadly supported in all components, specialize the batching to a binding input/output interface for the components that can support it for either publish or subscribe.
- As a performance-oriented feature, it also allows the component to specialize the interface and configuration that makes the most sense for it (e.g. Kafka request by min bytes only).
- A concern for this alternative is that there is no consistent way to provide per message tracing IDs when using bindings that way, and that is undesirable for Dapr observability.
Edit: Update based on the status of planning around EventHubs pubsub component.
I think it's important to keep in mind that the term "batching" can mean different things to different people. Some folks think of it as "multiple messages delivered in one chunk at a time" - which is what I think most of this issue is about. However, there are some folks who (correctly or not) say "batching" when they mean "I have millions of messages that need to be processed as quickly as possible". And to these folks a more accurate way to describe their need is to say something more like "I need to scale my processors" - especially if they don't have an in-order processing requirement, but are still using something like Kafka. Of course, the obvious issue with the former definition is that it often means the processing is serialized - so it won't work well at scale (like millions of messages in the latter case).
I think both scenarios are valid and needed, and it would be good if Dapr could provide guidance in the 2nd case.
@yaron2 why have you postponed this proposal to 1.9? I'm waiting for this feature for ages :(
Task List:
- [ ] Batch Publish HTTP/gRPC Implementation
- [ ] Bulk Suscribe HTTP/gRPC Implementation
- [ ] Raw Payload Support
- [ ] Tracing support
- [ ] Resiliency
- [ ] DLQ support
- [ ] Adding two component support - Kafka + Azure
- [ ] Component Conformance tests
- [ ] SDK integration
- [ ] Bulk Subscribe advanced
- [ ] Supporting incompatible components
- [ ] E2E tests
Batch Publish without broker support
Batch publish does not provide transactional semantics, the batch can be broken into individual messages and published individually.
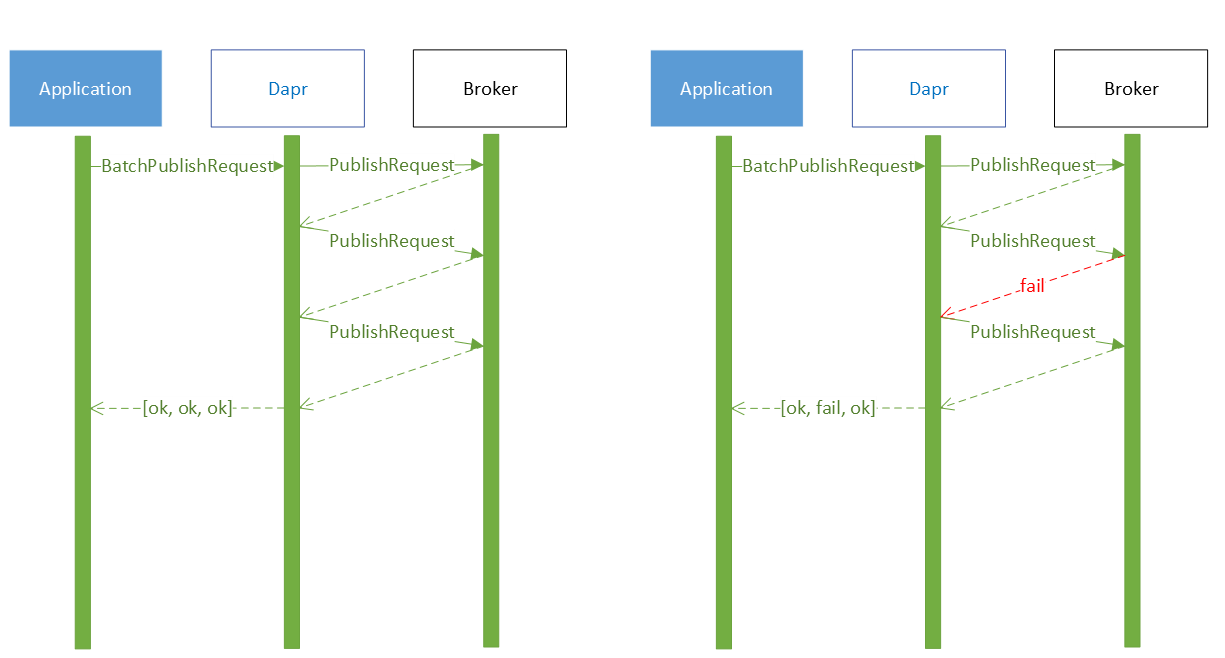
By default, the messages are published in parallel. This means that the messages may be received out of order. Here are two sequence diagrams to demonstrate the request flow.
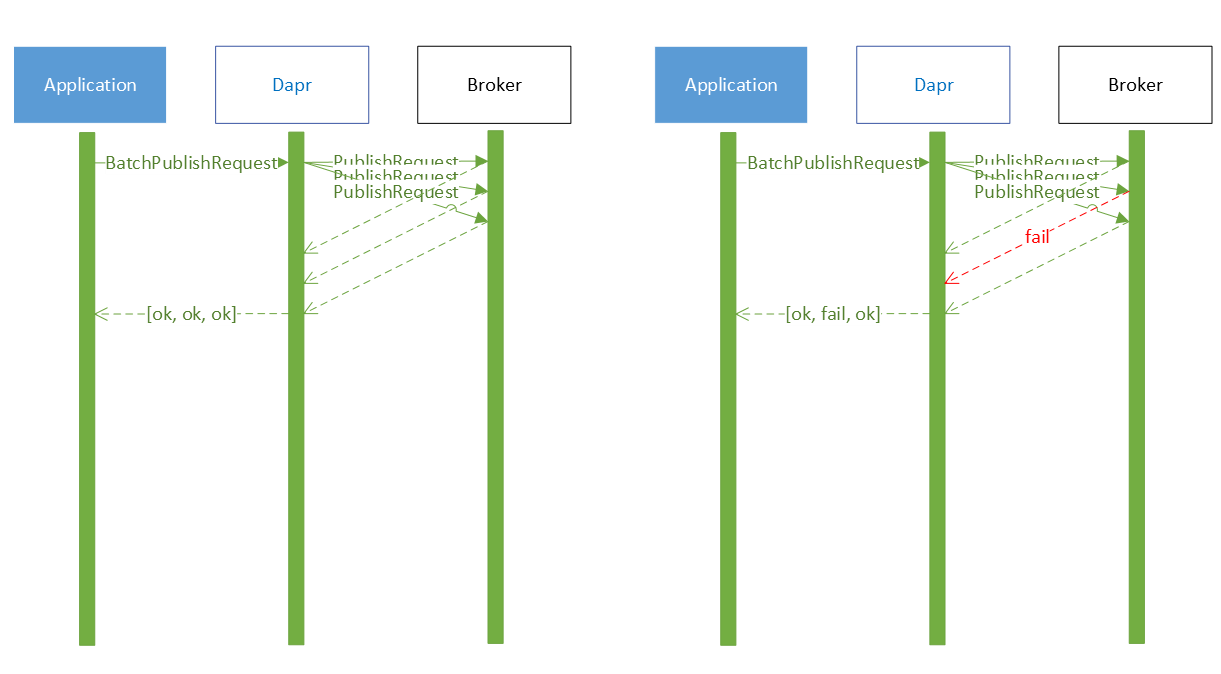
In case message ordering is required, the metadata batchPublishKeepOrder can be set to true. This will send the messages one after the other but is significantly slower than the above method (specially for larger batch sizes).
Batch subscribe without broker support
Batch subscribe will require the Dapr sidecar to maintain an in-memory storage to buffer messages. If a broker does not support batching, it will deliver messages to the sidecar one-by-one, and the sidecar will keep periodically sending the messages to the application in batches.
As discussed earlier in this proposal, Dapr will manage custom batching thresholds for received messages using the following metadata:
-
batchMinCount: minimum number of messages to trigger the app batch receive handler -
batchFetchLatencyMs: maximum milliseconds between subsequent triggers to the app batch receive handler
Note,
batchMinBytes, similar to Kafka’sConsumer.Fetch.Minwas considered but it won’t be supported for scenarios without broker support. Finding the size of data inside a struct in bytes is non-trivial for varied-length data structures.
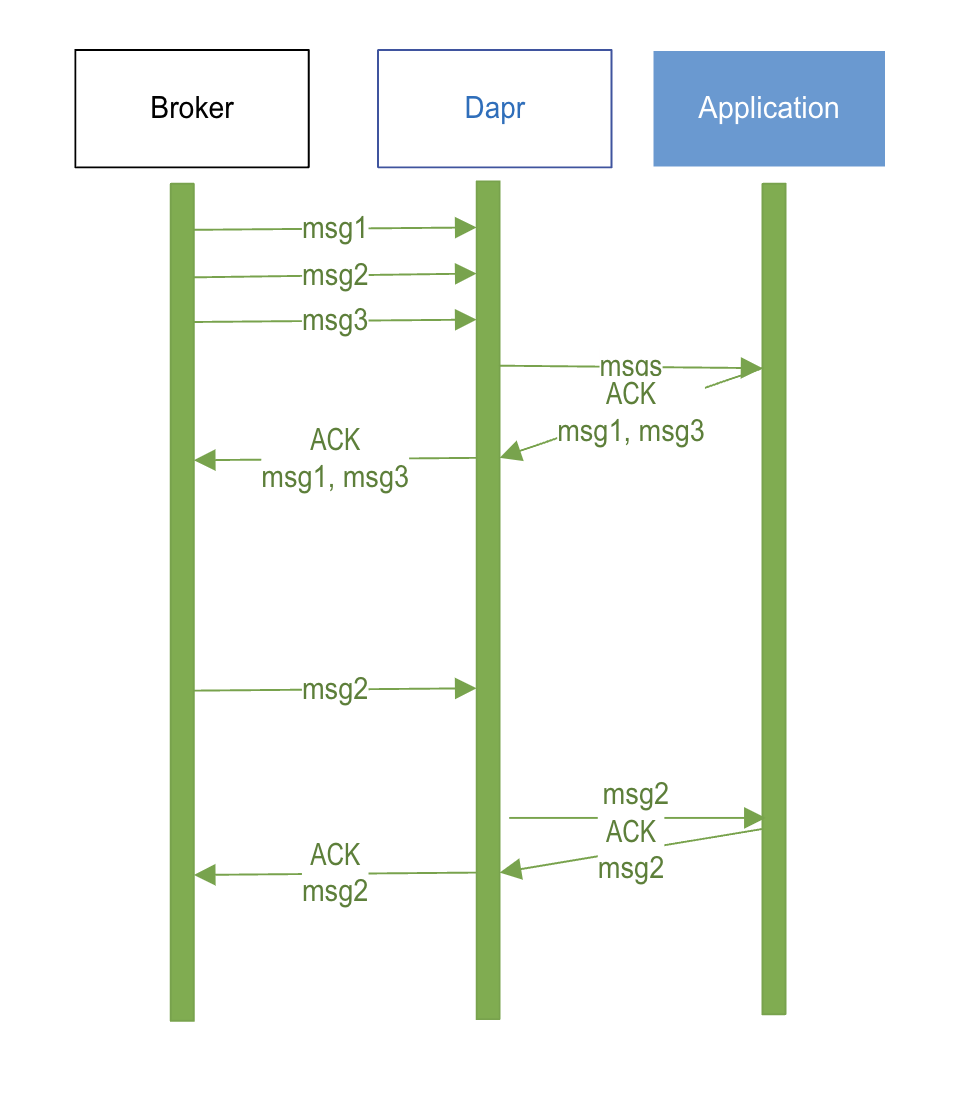
Note, Dapr won’t ACK to the broker on behalf of the application. This is because in case the Dapr sidecar crashes after ACKing a message and before delivering it to the application, it would result in that message to be lost.
Important: If the broker is set to retry a message when an ACK is not received within 5 seconds, and batchFetchLatencyMs and batchMinCount are configured to be too high, the broker might keep retrying all messages since ACKs will be never received in time. It is important to tune these parameters correctly. As suggested by @CodeMonkeyLeet above, this is an example of leaky abstraction and may cause scenarios to break when components are swapped, or configurations are updated.
Open: Are there any guardrails that can be put in place to prevent this scenario?
One way to deal with this is to not-implement batch subscribe. The sidecar will post messages as they arrive to the batch endpoint, wrapping a single message inside a batch request. This will not be highly performant, but it will comply with the batch API. In production, it might be a good expectation that users will hand-pick components with native batching support. This feature will enable them to still use batch-subscribe in dev/test with unsupported components and reuse the same application code.
Batch Subscribe:
Till now, this is how normal subscribe operation works in Dapr:
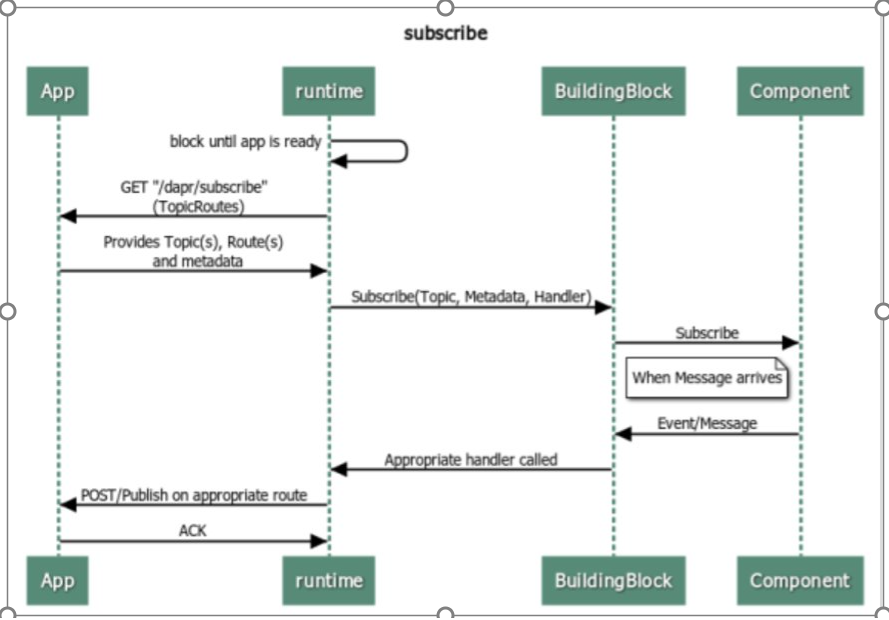
Well, Ideally this is how Batch Subscribe should flow like:
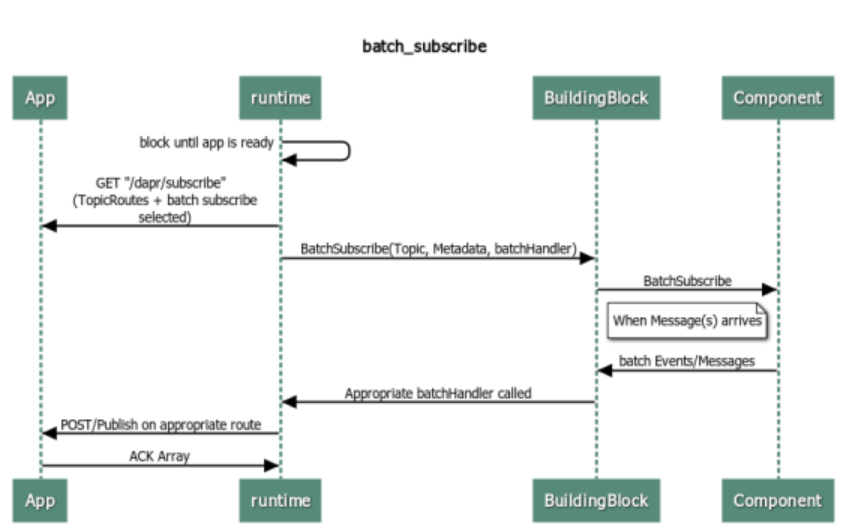
There is a separate handler for BatchSubscribe, which should allow multiple messages at once.
Design Considerations for Batch Subscribe in 1.9:
-
Consumption of messages in batches from broker.
-
With "/dapr/subscribe", an App can tell metadata options for
MaxBatchCount,MaxBatchLatencyInMillisecondsandMaxBatchSizeInBytesand it will be up to the building block how they are able to utilize: While collecting, messages in batches, there needs to be a way to control that how much can be consumed in that particular batch event, or else runtime may just keep on collecting from the broker for a long time and may not actually forward it to App in a timely fashion. There-in comes the usage of MaxbatchCount - to control max size of batch. Even further, if it is taking time beyond a certain threshold, MaxBatchLatencyInMilliseconds should timeout and this particular batch should be considered to have reached its capacity and taken further by runtime to be forwarded to App. Similar to MaxBatchCount, MaxBatchSizeInBytes can be used to control maximum Cap. -
Now, there are multiple cloudEvent messages to be sent at once to App. Hence, there needs to be a way to wrap them together. A cloudEvent wrapper on top of multiple cloudEvent messages will do the job, as per current standards. These individual messages are nothing but byte arrays, which a final cloudEvent wrapper would need to wrap all messages: {
"specversion": "1.0",
"type": "com.dapr.event.sent.batch",
"source": "https://the.empire.com/logistics",
"id": "b90443c3-8607-4873-8e80-ac9a674e0648",
"traceid": "50-ab8f8650bcb552827b65af4e208b1478-32331abc36eed07a-1a",
"datacontenttype": "application/json",
"data": { // Repeated NewBatchLeafMessage ... } }
-
As per the discussion above: Internal struct to allow metadata per message:
type NewBatchMessage struct {
Messages []NewBatchLeafMessage json:"messages"
Topic string json:"topic"
Metadata map[string]string json:"metadata"
ContentType *string json:"contentType,omitempty"
}
type NewBatchLeafMessage struct {
Data []byte json:"data"
ContentType *string json:"contentType,omitempty"
Metadata map[string]string json:"metadata"
}
-
Tracing uses Publisher traceId as its parent like in normal publish-subscribe. No knowledge of particular batch/bulk in which it came:
-
Response will have an array of status replies
response = { 'statuses':[] }The app needs to track a status for each message and they can fail individually:`response['statuses'].append({'id':msg['id'],'status':'SUCCESS'})` -
Bulk in nature i.e. as per status replies, particular messages will get RETRY/DROP
-
In Initial version, CloudEvent Support Only.
Proposed Batch Publish API
Each SDK provides a convenience wrapper for creating a list of CloudEvents on behalf of the app.
from dapr.clients import DaprClient
with DaprClient() as d:
req_data = [
{'workplace-accidents': '0'},
{'workplace-accidents': '1'},
{'workplace-accidents': '352'}
]
# New method to publish batch of events to a topic
resp = d.publish_events(
pubsub_name='pubsub’,
topic='deathStarStatus’,
data=json.dumps(req_data)
)
# Print the request
print(req_data, flush=True)
There will be a new HTTP endpoint to handle the batch publish:
curl -X "POST" http://localhost:3500/v1.0/publish/batch/pubsub/deathStarStatus -H "Content-Type: application/json" -d '@data.json'
Option 1
If the data.json file provided to the call contains a list of CloudEvents, it will look like the following:
[
{
"specversion": "1.0",
"type": "com.dapr.event.sent",
"source": "https://the.empire.com/logistics",
"id": "a1c8c741-0e7c-46d7-afba-06f02aa9b1fb",
"pubsubname": "pubsub",
"topic": "deathStarStatus",
"traceid": "00-2583c3e5f33c8db92a2ba0e3488a6a63-328e7491ec6678de-01",
"datacontenttype": "application/json",
"data": {
"workplace-accidents": "0"
}
},
{
"specversion": "1.0",
"type": "com.dapr.event.sent",
"source": "https://the.empire.com/logistics",
"id": "632078ee-ed6a-4055-9f1f-a66b5c3a5c2d",
"pubsubname": "pubsub",
"topic": "deathStarStatus",
"traceid": "24-9eba4a91b94b22a0a5f39d9d12bb3de2-28fdc016724ac48a-fb",
"datacontenttype": "application/json",
"data": {
"workplace-accidents": "1"
}
},
{
"specversion": "1.0",
"type": "com.dapr.event.sent",
"source": "https://the.empire.com/logistics",
"id": "e2d39297-e605-486d-a8f9-54791383f3c6",
"pubsubname": "pubsub",
"topic": "deathStarStatus",
"traceid": "50-ab8f8650bcb552827b65af4e208b1478-32331abc36eed07a-1a",
"datacontenttype": "application/json",
"data": {
"workplace-accidents": "352"
}
}
]
If raw playload is needed in the batch, we can still have a list of cloud events sent to the endpoint with metadata.raw_payload field set true. In which case only the data filed will be sent to be published to the broker.
The main issue with this structure is that individual event cannot have event level metadata.
If event level metadata is needed, a different structure is needed for the same, additionally a new complex structure will also easily support different format of events.
Option 2 (Recommended)
Consider a struct like the following:
type BatchEntry struct {
EntryID string /// Unique within request
Data []byte
DataContentType string
Metadata map[string]string
}
Here we have
- Event level metadata (can passing in attributes or TTL for individual events)
- Event level content type which can be used to specify what type of content the data is
- EntryID field to map the individual responses back as discussed below
- Data field which contains the actual data
The new data.json will look like the following for cloudevents data:
[
{
"entryId": "4fe",
"data": {
"specversion": "1.0",
"type": "com.dapr.event.sent",
"source": "https://the.empire.com/logistics",
"id": "a1c8c741-0e7c-46d7-afba-06f02aa9b1fb",
"pubsubname": "pubsub",
"topic": "deathStarStatus",
"traceid": "00-2583c3e5f33c8db92a2ba0e3488a6a63-328e7491ec6678de-01",
"datacontenttype": "application/json",
"data": {
"workplace-accidents": "0"
}
},
"metadata" : {
"ttlInSeconds": 100
},
"dataContentType": "application/cloudevents+json"
},
{
"entryId": "4ff",
"data": {
"specversion": "1.0",
"type": "com.dapr.event.sent",
"source": "https://the.empire.com/logistics",
"id": "a1c8c741-0e7c-46d7-afba-06234aa91fff",
"pubsubname": "pubsub",
"topic": "deathStarStatus",
"traceid": "00-2583c3e5f33c8db92a2ba0e3488a6a63-328e74918362c78de-02",
"datacontenttype": "application/json",
"data": {
"workplace-accidents": "2"
}
},
"metadata" : {
"ttlInSeconds": 10
},
"dataContentType": "application/cloudevents+json"
},
]
For raw payload it will look something like this:
[
{
"entryId": "1",
"data": "test1",
"metadata" : {
"ttlInSeconds" : 10
},
"dataContentType": "text/plain"
},
{
"entryId": "2",
"data": "test2",
"metadata" : {},
"dataContentType": "text/plain"
},
]
A couple of things to call out here:
- ~Current request level metadata fields will not be supported at request level.~ The
raw_payloadfield alone will be supported as a request level metadata. - The
topicandpubsubnameshould be the same for all events in the batch that match the endpoint.- In general, the broker APIs that support batch publish do not support publishing across topics in a batch, and Dapr would not want to support cross-publishing to different pubsubs in a single batch.
-
entryIdfield should be unique within that request. -
traceidfor a batch will different for all messages in the batch and will have a common traceParent generated by Dapr for the batch publish call.
A batch publish will not be treated as a single transaction i.e. individual messages in a batch could succeed or fail. The underlying broker batch publish APIs seem to vary significantly in their error contracts that can range from:
- Returns a single error on batch operation (Azure Event Hubs).
- Returns a single error on first failed message in a batch (Azure Service Bus).
- Returns information on individual message success/failure
In order to support brokers that return individual success/failure on a batch, the Dapr batch publish API would also produce a HTTP response mapping the CloudEvent IDs to statuses, for example:
{
"statuses": [
{"entryId": "a1c8c741-0e7c-46d7-afba-06f02aa9b1fb", "status": "SUCCESS"},
{"entryId": "632078ee-ed6a-4055-9f1f-a66b5c3a5c2d", "status": "FAIL"},
{"entryId": "e2d39297-e605-486d-a8f9-54791383f3c6", "status": "SUCCESS"}
]
}
If any message status is a failure, the HTTP response code for the batch operation will be a failure.
In the case where the underlying broker neither provides transactional semantics (all pass/fail only) or granular pass/fail information, Dapr may attempt to infer which messages failed (e.g. assuming messages are processed in order of the batch and having the ID of the first failed message), but will err on the side of duplicate publishing (i.e. marking a successfully published message as failed so that the app retries).
@yaron2 @artursouza thoughts?
I like Option 2 with some modifications:
- Rename that o bulk since it will be aligned with the terminology we use for state operations in bulk with no transaction guarantees.
- Change Data to
interface{}since it will allow that to be a cloud event object or byte array based on content-type. Also, renameDatatoEventsince it will be odd to calldata.datain code (event.datareads better). - entryId should be optional and default to 1, 2, 3, 4 sequence. It will cover most of the scenarios.
I like Option 2 with some modifications:
- Rename that o bulk since it will be aligned with the terminology we use for state operations in bulk with no transaction guarantees.
I do not think we should rename the API or objects in it to bulk. There is only generally widely accepted concept of batch publish and nothing wrt to bulk.
- Change Data to
interface{}since it will allow that to be a cloud event object or byte array based on content-type. Why not have everything as byte array and then check if it can be a cloud event based ondataContentType. We have had this discussion previously wrt interface between dapr/dapr and dapr/components-contrib
Also, rename
DatatoEventsince it will be odd to calldata.datain code (event.datareads better).
+1
- entryId should be optional and default to 1, 2, 3, 4 sequence. It will cover most of the scenarios.
I think this should be mandatory. Otherwise we are assuming an implicit order based on how we read the data and it might be confusing for the application if it receives a response suddenly with an ID that it has no knowledge of.
cc @artursouza @yaron2
I like Option 2 with some modifications:
- Rename that o bulk since it will be aligned with the terminology we use for state operations in bulk with no transaction guarantees.
I do not think we should rename the API or objects in it to bulk. There is only generally widely accepted concept of batch publish and nothing wrt to bulk.
We did have a discussion about Batch vs Bulk and the main difference was that Batch would save all messages as a single write while Bulk would not have that guarantee. This distinction is important. We cannot use Batch and Bulk interchangeably.
- Change Data to
interface{}since it will allow that to be a cloud event object or byte array based on content-type. Why not have everything as byte array and then check if it can be a cloud event based ondataContentType. We have had this discussion previously wrt interface between dapr/dapr and dapr/components-contribAlso, rename
DatatoEventsince it will be odd to calldata.datain code (event.datareads better).+1
- entryId should be optional and default to 1, 2, 3, 4 sequence. It will cover most of the scenarios.
I think this should be mandatory. Otherwise we are assuming an implicit order based on how we read the data and it might be confusing for the application if it receives a response suddenly with an ID that it has no knowledge of. This is odd. Adding a random ID to each message only for Bulk publish is odd. The non-bulk API does not require that. I see SDKs making this "depend on order" thing for convenience just because the runtime does not do it.
cc @artursouza @yaron2
We did have a discussion about Batch vs Bulk and the main difference was that Batch would save all messages as a single write while Bulk would not have that guarantee. This distinction is important. We cannot use Batch and Bulk interchangeably
Agree, this is the path of least surprise for the user. Batch and Bulk carry very different guarantees. While pub/sub terms do not usually use Bulk, Dapr does have the Bulk concept so this would be aligned with other APIs today.
entryId should be optional and default to 1, 2, 3, 4 sequence. It will cover most of the scenarios.
I would rather have entryId be optional to to reduce boilerplate code from the user's perspective. For the Batch API, there should be no entryId at all.
I would rather have entryId be optional to to reduce boilerplate code from the user's perspective. For the Batch API, there should be no entryId at all.
@yaron2 If we rename to operations and struct to bulk to align with other Dapr APIs, then what does the above comment that it is not required for Batch API imply?
@artursouza @yaron2 Are we aligned on the functionality being defined by this API? That since publishing and subscribing to messages will not be transactional (individual messages can fail or succeed if there is broker support for it), based on the previous comments this will then be called bulk publish and subscribe to be consistent with the other Dapr APIs even though that is not a term used in pub/sub?
Batch Subscribe:
Till now, this is how normal subscribe operation works in Dapr:
Well, Ideally this is how Batch Subscribe should flow like:
There is a separate handler for BatchSubscribe, which should allow multiple messages at once.
Design Considerations for Batch Subscribe in 1.9:
- Consumption of messages in batches from broker.
- With "/dapr/subscribe", an App can tell metadata options for
MaxBatchCount,MaxBatchLatencyInMillisecondsandMaxBatchSizeInBytesand it will be up to the building block how they are able to utilize: While collecting, messages in batches, there needs to be a way to control that how much can be consumed in that particular batch event, or else runtime may just keep on collecting from the broker for a long time and may not actually forward it to App in a timely fashion. There-in comes the usage of MaxbatchCount - to control max size of batch. Even further, if it is taking time beyond a certain threshold, MaxBatchLatencyInMilliseconds should timeout and this particular batch should be considered to have reached its capacity and taken further by runtime to be forwarded to App. Similar to MaxBatchCount, MaxBatchSizeInBytes can be used to control maximum Cap.- Now, there are multiple cloudEvent messages to be sent at once to App. Hence, there needs to be a way to wrap them together. A cloudEvent wrapper on top of multiple cloudEvent messages will do the job, as per current standards. These individual messages are nothing but byte arrays, which a final cloudEvent wrapper would need to wrap all messages: { "specversion": "1.0", "type": "com.dapr.event.sent.batch", "source": "https://the.empire.com/logistics", "id": "b90443c3-8607-4873-8e80-ac9a674e0648", "traceid": "50-ab8f8650bcb552827b65af4e208b1478-32331abc36eed07a-1a", "datacontenttype": "application/json", "data": { // Repeated NewBatchLeafMessage ... } }
- As per the discussion above: Internal struct to allow metadata per message:
type NewBatchMessage struct { Messages []NewBatchLeafMessage `json:"messages"` Topic string `json:"topic"` Metadata map[string]string `json:"metadata"` ContentType *string `json:"contentType,omitempty"` }type NewBatchLeafMessage struct { Data []byte `json:"data"` ContentType *string `json:"contentType,omitempty"` Metadata map[string]string `json:"metadata"` }
- Tracing uses Publisher traceId as its parent like in normal publish-subscribe. No knowledge of particular batch/bulk in which it came:
- Response will have an array of status replies
response = { 'statuses':[] }The app needs to track a status for each message and they can fail individually:`response['statuses'].append({'id':msg['id'],'status':'SUCCESS'})`- Bulk in nature i.e. as per status replies, particular messages will get RETRY/DROP
- In Initial version, CloudEvent Support Only.
Even though structs for Bulk Subscribe were defined under previous comment (specifically point no. 4) but I think it will be better to define structs etc. more clearly and explicitly. And, also bring forth few changes that seem considerable.
How bulkSubscribe be triggered?
App can define "bulkSubscribe" to be true inside metadata for response for "/dapr/subscribe":
app.get('/dapr/subscribe', (_req, res) => {
res.json([
{
pubsubname: "orderpubsub",
topic: "orders",
route: "orders",
metadata: {
bulkSubscribe: "true",
maxBatchCount: "8",
// maxBatchLatencyMilliSeconds: "",
// maxBatchSizeBytes: "",
}
},
]);
});
Other config options like, maxBatchCount, maxBatchLatencyMilliSeconds and maxBatchSizeBytes can be also defined here in metadata.
In what form data is propagated to App in case of bulk subscribe?
Option 1 (Recommended)
To be able to support metadata per entry in bulk message, Subscribe is also using this kind of struct:
For http:
When cloudevent is sent:
type BulkMessageAppEntry struct {
EntryID string `json:"entryID"`
Event map[string]interface{} `json:"event"`
ContentType string `json:"contentType,omitempty"`
Metadata map[string]string `json:"metadata"`
}
[
{
"entryId": "1",
"event": {
"specversion": "1.0",
"type": "com.dapr.event.sent.bulk",
"source": "105b06d2-2140-41db-929a-6b56656b2c49",
"id": "267d9b02-bd8b-488a-88da-3c50a8706951",
"pubsubname": "pubsub",
"topic": "orderpubsub",
"traceid": "00-04bb137635da153d366d867e04a2cd3b-dc448165ff0884bf-01",
"datacontenttype": "application/json",
"data": {
"orderId": "1"
}
},
"metadata" : {
"key1": "value1"
},
"contentType": "application/cloudevents+json"
},
{
"entryId": "2",
"event": {
"specversion": "1.0",
"type": "com.dapr.event.sent.bulk",
"source": "105b06d2-2140-41db-929a-6b56656b2c49",
"id": "1938bb32-a1d3-4e40-9fbf-b1c468ec1821",
"pubsubname": "pubsub",
"topic": "orderpubsub",
"traceid": "00-3d97a493b10c3604685480fb6d3c2f1d-31b1022ed3d42633-01",
"datacontenttype": "application/json",
"data": {
"orderId": "2"
}
},
"metadata" : {
"key2": "value2"
},
"dataContentType": "application/cloudevents+json"
},
]
When rawPayload is sent(rawPayload: "true" in metadata for "/dapr/subscribe"):
type BulkMessageAppEntry struct {
EntryID string `json:"entryID"`
Event string `json:"event"`
ContentType string `json:"contentType,omitempty"`
Metadata map[string]string `json:"metadata"`
}
{"events":
[
{
"entryId": "1",
"event": "eyJvcmRlcklkIjoxfQ==",
"metadata" : {
"key1": "value1"
},
"contentType": "application/octet-stream"
},
{
"entryId": "2",
"event": "eyJvcmRlcklkIjoyfQ==",
"metadata" : {
"key2": "value2"
},
"dataContentType": "application/octet-stream"
},
],
"pubsubname": "orderpubsub",
"topic": "orders",
}
And, this BulkMessageEntry.Event will contain rawPayload in base64 encoded form. This is in sync with base64 encoded being sent today for rawPayload subscribe in http for simple Subscribe.
This Option seems to be in sync with what is also being done for BulkPublish.
For grpc:
BulkMessageEntry {
bytes event = 1;
string data_content_type = 2;
map<string,string> metadata = 3;
string entryID = 4;
}
TopicEventBulkRequest {
string pubsub_name = 1;
string topic = 2;
repeated BulkMessageEntry events = 3;
map<string, string> metadata = 4;
string path = 5;
}
Here, response from App would be:
{
"statuses": [
{"entryId": "1", "status": "DROP"},
{"entryId": "2", "status": "RETRY"},
{"entryId": "3", "status": "SUCCESS"}
]
}
Option 2
Always using cloudEvent - even when rawPayload is being sent, create a RawPayload (like currently done via pubsub.FromRawPayload func):
For http:
type BulkMessageEntry struct {
Event map[string]interface{} `json:"event"`
ContentType string `json:"contentType,omitempty"`
Metadata map[string]string `json:"metadata"`
}
Here, in case of rawPayload, App will need to base64 decode and then use id from cloudEvent to send back response per entry in bulk:
Here, response from App would be:
{
"statuses": [
{"id": "1938bb32-a1d3-4e40-9fbf-b1c468ec1821", "status": "DROP"},
{"id": "85f941e7-5cb8-4914-bbe3-1138a9fd4c25", "status": "RETRY"},
{"id": "267d9b02-bd8b-488a-88da-3c50a8706951", "status": "SUCCESS"}
]
}
Option 3
Wrapping all entries inside a bulk message inside a super-cloudEvent. It doesn't seem to be of any particular use. It was the point number 3 in previous comment but that deosn't seem to be required.
@artursouza @yaron2 wdyt?
Alright, I thought that I have already defined
Batch Subscribe:
Till now, this is how normal subscribe operation works in Dapr:
- Consumption of messages in batches from broker.
- With "/dapr/subscribe", an App can tell metadata options for
MaxBatchCount,MaxBatchLatencyInMillisecondsandMaxBatchSizeInBytesand it will be up to the building block how they are able to utilize: While collecting, messages in batches, there needs to be a way to control that how much can be consumed in that particular batch event, or else runtime may just keep on collecting from the broker for a long time and may not actually forward it to App in a timely fashion. There-in comes the usage of MaxbatchCount - to control max size of batch. Even further, if it is taking time beyond a certain threshold, MaxBatchLatencyInMilliseconds should timeout and this particular batch should be considered to have reached its capacity and taken further by runtime to be forwarded to App. Similar to MaxBatchCount, MaxBatchSizeInBytes can be used to control maximum Cap.- Now, there are multiple cloudEvent messages to be sent at once to App. Hence, there needs to be a way to wrap them together. A cloudEvent wrapper on top of multiple cloudEvent messages will do the job, as per current standards. These individual messages are nothing but byte arrays, which a final cloudEvent wrapper would need to wrap all messages: { "specversion": "1.0", "type": "com.dapr.event.sent.batch", "source": "https://the.empire.com/logistics", "id": "b90443c3-8607-4873-8e80-ac9a674e0648", "traceid": "50-ab8f8650bcb552827b65af4e208b1478-32331abc36eed07a-1a", "datacontenttype": "application/json", "data": { // Repeated NewBatchLeafMessage ... } }
- As per the discussion above: Internal struct to allow metadata per message:
type NewBatchMessage struct { Messages []NewBatchLeafMessage `json:"messages"` Topic string `json:"topic"` Metadata map[string]string `json:"metadata"` ContentType *string `json:"contentType,omitempty"` }type NewBatchLeafMessage struct { Data []byte `json:"data"` ContentType *string `json:"contentType,omitempty"` Metadata map[string]string `json:"metadata"` }
- Tracing uses Publisher traceId as its parent like in normal publish-subscribe. No knowledge of particular batch/bulk in which it came:
- Response will have an array of status replies
response = { 'statuses':[] }The app needs to track a status for each message and they can fail individually:`response['statuses'].append({'id':msg['id'],'status':'SUCCESS'})`- Bulk in nature i.e. as per status replies, particular messages will get RETRY/DROP
- In Initial version, CloudEvent Support Only.
Even though structs for Bulk Subscribe were defined under previous comment (specifically point no. 4) but I think it will be better to define structs etc. more clearly and explicitly. And, also bring forth few changes that seem considerable.
How bulkSubscribe be triggered?
App can define "bulkSubscribe" to be true inside metadata for response for "/dapr/subscribe":
app.get('/dapr/subscribe', (_req, res) => { res.json([ { pubsubname: "orderpubsub", topic: "orders", route: "orders", metadata: { bulkSubscribe: "true", maxBatchCount: "8", // maxBatchLatencyMilliSeconds: "", // maxBatchSizeBytes: "", } }, ]); });Other config options like, maxBatchCount, maxBatchLatencyMilliSeconds and maxBatchSizeBytes can be also defined here in metadata.
In what form data is propagated to App in case of bulk subscribe?
Option 1 (Recommended)
To be able to support metadata per entry in bulk message, Subscribe is also using this kind of struct:
For http:
When cloudevent is sent:
type BulkMessageAppEntry struct { EntryID string `json:"entryID"` Event map[string]interface{} `json:"event"` ContentType string `json:"contentType,omitempty"` Metadata map[string]string `json:"metadata"` }[ { "entryId": "1", "event": { "specversion": "1.0", "type": "com.dapr.event.sent.bulk", "source": "105b06d2-2140-41db-929a-6b56656b2c49", "id": "267d9b02-bd8b-488a-88da-3c50a8706951", "pubsubname": "pubsub", "topic": "orderpubsub", "traceid": "00-04bb137635da153d366d867e04a2cd3b-dc448165ff0884bf-01", "datacontenttype": "application/json", "data": { "orderId": "1" } }, "metadata" : { "key1": "value1" }, "contentType": "application/cloudevents+json" }, { "entryId": "2", "event": { "specversion": "1.0", "type": "com.dapr.event.sent.bulk", "source": "105b06d2-2140-41db-929a-6b56656b2c49", "id": "1938bb32-a1d3-4e40-9fbf-b1c468ec1821", "pubsubname": "pubsub", "topic": "orderpubsub", "traceid": "00-3d97a493b10c3604685480fb6d3c2f1d-31b1022ed3d42633-01", "datacontenttype": "application/json", "data": { "orderId": "2" } }, "metadata" : { "key2": "value2" }, "dataContentType": "application/cloudevents+json" }, ]When rawPayload is sent(rawPayload: "true" in metadata for "/dapr/subscribe"):
type BulkMessageAppEntry struct { EntryID string `json:"entryID"` Event string `json:"event"` ContentType string `json:"contentType,omitempty"` Metadata map[string]string `json:"metadata"` }{"events": [ { "entryId": "1", "event": "eyJvcmRlcklkIjoxfQ==", "metadata" : { "key1": "value1" }, "contentType": "application/octet-stream" }, { "entryId": "2", "event": "eyJvcmRlcklkIjoyfQ==", "metadata" : { "key2": "value2" }, "dataContentType": "application/octet-stream" }, ], "pubsubname": "orderpubsub", "topic": "orders", }And, this BulkMessageEntry.Event will contain rawPayload in base64 encoded form. This is in sync with base64 encoded being sent today for rawPayload subscribe in http for simple Subscribe. Difference is that right now, base64 encoded is a cloud event consisting of rawPayload data as well, but now it will be only rawpayload data.
This seems to be in sync with what is also being done for BulkPublish.
For grpc:
BulkMessageEntry { bytes event = 1; string data_content_type = 2; map<string,string> metadata = 3; string entryID = 4; }TopicEventBulkRequest { string pubsub_name = 1; string topic = 2; repeated BulkMessageEntry events = 3; map<string, string> metadata = 4; string path = 5; }Here, response from App would be:
{ "statuses": [ {"entryId": "1", "status": "DROP"}, {"entryId": "2", "status": "RETRY"}, {"entryId": "3", "status": "SUCCESS"} ] }Option 2
Always using cloudEvent - even when rawPayload is being sent, create a RawPayload (like currently done via pubsub.FromRawPayload func):
For http:
type BulkMessageEntry struct { Event map[string]interface{} `json:"event"` ContentType string `json:"contentType,omitempty"` Metadata map[string]string `json:"metadata"` }Here, in case of rawPayload, App will need to base64 decode and then use id from cloudEvent to send back response per entry in bulk:
Here, response from App would be:
{ "statuses": [ {"id": "1938bb32-a1d3-4e40-9fbf-b1c468ec1821", "status": "DROP"}, {"id": "85f941e7-5cb8-4914-bbe3-1138a9fd4c25", "status": "RETRY"}, {"id": "267d9b02-bd8b-488a-88da-3c50a8706951", "status": "SUCCESS"} ] }Option 3
Wrapping all entries inside a bulk message inside a super-cloudEvent. It doesn't seem to be of any particular use. It was the point number 3 in previous comment but that deosn't seem to be required.
@artursouza @yaron2 wdyt?
I agree with Option 1.
@artursouza @yaron2 As discussed offline, setting the metrics as per the following definition
`component/pubsub_egress/bulk/count` --> this is count of the operation being called (BulkPublish)
`component/pubsub_egress/bulk/latency` --> latency of the operation
`component/pubsub_egress/bulk/event_count` -- for each event posted this count will be incremented
later once the BulkPublish API is out of Alpha Status and in GA, we will have a merged metric that tracks the count of events posted through both single publish and bulk publish. For now both the counts will be separate.
For bulk subscribe, for gRPC side, we need a new API for Apps in proto definitions.
If we introduce a new API in existing service AppCallback, then it becomes a breaking change for existing Apps, when they start to use Dapr 1.9. So, @mukundansundar suggested me using a new service which can be like an extension to AppCallback service, just like AppCallbackHealthCheck.
So, I will be creating a new service and API in it:
// AppCallbackBulkSubscribe V1 is an optional extension to AppCallback V1 to opt
// for Bulk Subscription.
service AppCallbackBulkSubscribe {
// Subscribes bulk events from Pubsub
rpc OnBulkTopicEventAlpha1(TopicEventBulkRequest) returns (TopicEventBulkResponse) {}
}
@artursouza @yaron2 I hope that is fine.
Task List merged into feature branch in dapr/dapr or components-contrib:
- [x] Bulk Publish HTTP/gRPC Implementation -> PRs (#5127)(#5213)
- [x] Bulk Suscribe HTTP/gRPC Implementation --> PRs(#5154)(#5177)
- [x] Raw Payload Support -> done as part of impl PRs
- [x] Tracing support -> done as part of impl PRs
- [ ] Resiliency -> moved to 1.10 (in built retries on a component basis is there as part of impl eg: Kafka https://github.com/dapr/components-contrib/pull/2067)
- [x] DLQ support -> done as part of subscribe impl PRs
- [x] Adding two component support - Kafka + Azure ->
- [x] Kafka PRs (https://github.com/dapr/components-contrib/pull/2059)(https://github.com/dapr/components-contrib/pull/2067)
- [x] Azure SB PRs (https://github.com/dapr/components-contrib/pull/2106)(https://github.com/dapr/components-contrib/pull/2100)
- [x] Azure EH Bulk Publish PR (https://github.com/dapr/components-contrib/pull/2119)
- [x] Component Conformance tests
- [x] Basic Bulk publish and normal subscribe conformance PR (https://github.com/dapr/components-contrib/pull/2103)
- [x] Basic Bulk Subscribe conformance PR (https://github.com/dapr/components-contrib/pull/2113)
- [ ] SDK integration -> in progress
- [ ] Java SDK Issue (https://github.com/dapr/java-sdk/issues/778)
- [ ] Bulk publish in Java (https://github.com/dapr/java-sdk/pull/789)
- [ ] JS SDK Issue (https://github.com/dapr/js-sdk/issues/360)
- [ ] Go SDK Issue (https://github.com/dapr/go-sdk/issues/325)
- [ ] .NET SDK Issue (https://github.com/dapr/dotnet-sdk/issues/958)
- [ ] Python SDK Issue (https://github.com/dapr/python-sdk/issues/464)
- [ ] Java SDK Issue (https://github.com/dapr/java-sdk/issues/778)
- [x] Supporting incompatible components -> Default impl of Bulk Publish and Subscribe merged as part of impl PRs
- [x] E2E tests
- [x] Basic compatibility between bulk publish and normal subscribe successful test -> Part of impl PRs for bulk publish (#5127)(#5213)
- [x] Basic compatibility between normal publish and bulk subscribe test --> Part of impl PR for grpc bulk subscribe
- [x] Docs Issues
- [ ] Bulk Pubsub docs (https://github.com/dapr/docs/issues/2783)
- [ ] ASB Support (https://github.com/dapr/docs/issues/2813)
- [ ] Az EH Support (https://github.com/dapr/docs/issues/2804)
- [ ] Kafka Support (https://github.com/dapr/docs/issues/2825)
For bulk subscribe, for gRPC side, we need a new API for Apps in proto definitions. If we introduce a new API in existing
service AppCallback, then it becomes a breaking change for existing Apps, when they start to use Dapr 1.9. So, @mukundansundar suggested me using a new service which can be like an extension to AppCallback service, just likeAppCallbackHealthCheck.So, I will be creating a new service and API in it:
// AppCallbackBulkSubscribe V1 is an optional extension to AppCallback V1 to opt // for Bulk Subscription. service AppCallbackBulkSubscribe { // Subscribes bulk events from Pubsub rpc OnBulkTopicEventAlpha1(TopicEventBulkRequest) returns (TopicEventBulkResponse) {} }@artursouza @yaron2 I hope that is fine.
Can you please explain why adding a new method to the existing app callback will result in a breaking change?
For bulk subscribe, for gRPC side, we need a new API for Apps in proto definitions. If we introduce a new API in existing
service AppCallback, then it becomes a breaking change for existing Apps, when they start to use Dapr 1.9. So, @mukundansundar suggested me using a new service which can be like an extension to AppCallback service, just likeAppCallbackHealthCheck. So, I will be creating a new service and API in it:// AppCallbackBulkSubscribe V1 is an optional extension to AppCallback V1 to opt // for Bulk Subscription. service AppCallbackBulkSubscribe { // Subscribes bulk events from Pubsub rpc OnBulkTopicEventAlpha1(TopicEventBulkRequest) returns (TopicEventBulkResponse) {} }@artursouza @yaron2 I hope that is fine.
Can you please explain why adding a new method to the existing app callback will result in a breaking change?
It will be a new rpc for BulkSubscribe, if we add it to exiting AppCallback, then when existing apps upgrade Dapr 1.9, they will need to necessarily implement this rpc, even if they don't use this feature. Hence, it will be a breaking change for them.
But, on adding to a new Service, they can optionally Register for this Service.
I don't think adding a new service is a good way, though the reason makes sense at this time.
Because we can use this reason every time when we plan to add something new in appcallback, and we will add more and ore services......
I can't image how many services will we add in the future.
I suggest to stop adding new service at this time.
What is the way out for this one then?
Can we name new service in such a way that any new Alpha RPCs can be added to it, something like AppCallbackAlpha and when the rpc graduates, only then we add it to AppCallback?
Based on our discussion @yaron2, @artursouza we will have one service called AppCallbackAlpha which will contain all the APIs that are in Alpha stage and once it graduates to stable stage, we will most probably create a breaking change in AppCallback with the new stable API.