QTensor
 QTensor copied to clipboard
QTensor copied to clipboard
Compression
- Cost estimation takes into account number of (de)compressions, memory limit, etc.
Usage:
compressed_contraction_cost(tn, peo, mem_limit, compression_ratio)Memory limit is assumed to be log2(number of elements) = log2(number of bytes/16) - Cost estimation example
qtensor/compression/test_cost_estimation.py
@mkshah5
I'm trying to build sz compression as described in README_python.md.
I get the following error:
DynamicByteArray.c:13:10: fatal error: DynamicByteArray.h: No such file or directory
13 | #include "DynamicByteArray.h"
| ^~~~~~~~~~~~~~~~~~~~
compilation terminated.
I found the file in the main SZ repo (sz/include dir). I tried cloning the repo and passing -I ../SZ/sz/include flag but it is giving more errors:
sz_p_q.c:284:9: error: unknown type name ‘TightDataPointStorageD’
284 | TightDataPointStorageD* tdps;
| ^~~~~~~~~~~~~~~~~~~~~~
sz_p_q.c:286:9: warning: implicit declaration of function ‘new_TightDataPointStorageD’ [-Wimplicit-function-declaration]
286 | new_TightDataPointStorageD(&tdps, dataLength, exactDataNum,
| ^~~~~~~~~~~~~~~~~~~~~~~~~~
sz_p_q.c:287:48: error: request for member ‘array’ in something not a structure or union
287 | type, exactMidByteArray->array, exactMidByteArray->size,
| ^~
sz_p_q.c:287:74: error: request for member ‘size’ in something not a structure or union
287 | type, exactMidByteArray->array, exactMidByteArray->size,
| ^~
sz_p_q.c:288:42: error: request for member ‘array’ in something not a structure or union
288 | exactLeadNumArray->array,
| ^~
sz_p_q.c:289:37: error: request for member ‘array’ in something not a structure or union
289 | resiBitArray->array, resiBitArray->size,
| ^~
sz_p_q.c:289:58: error: request for member ‘size’ in something not a structure or union
289 | resiBitArray->array, resiBitArray->size,
| ^~
sz_p_q.c:292:9: error: request for member ‘plus_bits’ in something not a structure or union
292 | tdps->plus_bits = confparams_cpr->plus_bits;
| ^~
sz_p_q.c:295:9: warning: implicit declaration of function ‘free_DIA’ [-Wimplicit-function-declaration]
295 | free_DIA(exactLeadNumArray);
| ^~~~~~~~
sz_p_q.c:302:9: warning: implicit declaration of function ‘freeTopLevelTableWideInterval’ [-Wimplicit-function-declaration]
302 | freeTopLevelTableWideInterval(&levelTable);
| ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~
sz_p_q.c: At top level:
sz_p_q.c:308:151: error: unknown type name ‘bool’
308 | unsigned char* signs, bool* positive, double min, double max, double nearZero){
| ^~~~
sz_p_q.c:5:1: note: ‘bool’ is defined in header ‘<stdbool.h>’; did you forget to ‘#include <stdbool.h>’?
4 | #include <math.h>
+++ |+#include <stdbool.h>
5 | void updateLossyCompElement_Double(unsigned char* curBytes, unsigned char* preBytes,
sz_p_q.c:341:137: error: unknown type name ‘bool’
341 | double computeRangeSize_double_MSST19(double* oriData, size_t size, double* valueRangeSize, double* medianValue, unsigned char * signs, bool* positive, double* nearZero)
| ^~~~
sz_p_q.c:341:137: note: ‘bool’ is defined in header ‘<stdbool.h>’; did you forget to ‘#include <stdbool.h>’?
@mkshah5 compression with arbitrary dtype seems to work for small tensors (tested float32, float64, and complex128), but fails on larger tensor. What I do is adjust num_elements to be larger if the dtype is larger: https://github.com/danlkv/QTensor/blob/fd3888e41bf984b8a854f0ddbf0824b5a8fff279/qtensor/compression/CompressedTensor.py#L52 Here's what I get when trying to compress:
pytest -sk test_compressors
[...]
.(2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2) <qtensor.compression.CompressedTensor.CUSZCompressor object at 0x7fc02f81b640> <class 'numpy.float64'>
Num elements 524288
CUDA Error: no error
GPU compression timing: 0.330432 ms
CUDA error at cuszx_entry.cu:611 code=700(cudaErrorIllegalAddress) "cudaMemcpy(outSize, d_outSize, sizeof(size_t), cudaMemcpyDeviceToHost)"
Could you please take a look?
@mkshah5 compression with arbitrary dtype seems to work for small tensors (tested float32, float64, and complex128), but fails on larger tensor. What I do is adjust num_elements to be larger if the dtype is larger:
https://github.com/danlkv/QTensor/blob/fd3888e41bf984b8a854f0ddbf0824b5a8fff279/qtensor/compression/CompressedTensor.py#L52
Here's what I get when trying to compress:
pytest -sk test_compressors [...] .(2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2) <qtensor.compression.CompressedTensor.CUSZCompressor object at 0x7fc02f81b640> <class 'numpy.float64'> Num elements 524288 CUDA Error: no error GPU compression timing: 0.330432 ms CUDA error at cuszx_entry.cu:611 code=700(cudaErrorIllegalAddress) "cudaMemcpy(outSize, d_outSize, sizeof(size_t), cudaMemcpyDeviceToHost)"Could you please take a look?
@danlkv cuSZx currently works only for single precision floating point. Is double precision floating point needed?
I think the issue is that it doesn't make sense to treat single float64 as two float32s:) I tested complex64 and it works ok. Let's go with complex64 from now on I guess.
@mkshah5 I think using complex64 maybe actually is better. If one is using lossy compression simulator, they might tolerate loss in precision. After all, it's the same precision-memory tradeoff. Additionally, my guess is that using single-precision numbers may have a better tradeoff than using compression.
All in all, using single-precision can be justified as a part of the compression buisness, unless it introduces some kind of bad systematic error that cusz doesn't.
@mkshah5 It seems there is a memory leak when I compress data. Take a look at this test file: https://github.com/danlkv/QTensor/blob/9b787d17c0f877a44ed3e4310cad5519fec0754a/qtensor/compression/tests/test_memory_leak.py
If you run pytest -sk leak in qtensor/compression/tests folder the memory starts to grow without bounds, even though I free the compressed data.
@mkshah5 I added some cudaFree for arrays that were allocated. https://github.com/danlkv/QTensor/blob/e86e30331bb2cbb634da83daf654cfd4156f346a/qtensor/compression/szx/src/cuszx_entry.cu#L620-L624 It seems there are quite a few malloc-s going on for each compression. Could this significantly slow down the simulation? Additionally, we might want move the timing call https://github.com/danlkv/QTensor/blob/e86e30331bb2cbb634da83daf654cfd4156f346a/qtensor/compression/szx/src/cuszx_entry.cu#L564 to before the malloc-s so that the compression time includes the time for malloc.
There's another thing that got my attention: I ran the simulation with nvprof and noticed that device_post_proc function takes a lot of time. In the code, it is called with block size of 1. https://github.com/danlkv/QTensor/blob/e86e30331bb2cbb634da83daf654cfd4156f346a/qtensor/compression/szx/src/cuszx_entry.cu#LL608
My understanding was that we usually want to have a block size of ~32-128 to utilize parallelism. What is the reason for running this kernel with <<<1, 1>>>?
There's another thing that got my attention: I ran the simulation with
nvprofand noticed thatdevice_post_procfunction takes a lot of time. In the code, it is called with block size of 1. https://github.com/danlkv/QTensor/blob/e86e30331bb2cbb634da83daf654cfd4156f346a/qtensor/compression/szx/src/cuszx_entry.cu#LL608My understanding was that we usually want to have a block size of ~32-128 to utilize parallelism. What is the reason for running this kernel with
<<<1, 1>>>?
The device_post_proc function originally ran on CPU in SZx, I moved it to a GPU kernel so that all of the post-processing activity can stay on the device. This portion is a fairly serial process, but I can take a look to see if there is any parallelism we can exploit. As is, this function essentially is built for single thread use, where the thread groups all the generated data into the final compressed structure.
@mkshah5 I added some
cudaFreefor arrays that were allocated.https://github.com/danlkv/QTensor/blob/e86e30331bb2cbb634da83daf654cfd4156f346a/qtensor/compression/szx/src/cuszx_entry.cu#L620-L624
It seems there are quite a few malloc-s going on for each compression. Could this significantly slow down the simulation? Additionally, we might want move the timing call https://github.com/danlkv/QTensor/blob/e86e30331bb2cbb634da83daf654cfd4156f346a/qtensor/compression/szx/src/cuszx_entry.cu#L564
to before the malloc-s so that the compression time includes the time for malloc.
Thank you for adding the cudaFree() calls. I can also take a look and see if there are additional frees needed to avoid memory leaks. The mallocs() are needed for the intermediate metadata and are later grouped together by device_post_proc for the final compressed version. Could compression run asynchronously? If so, we could have the GPU compress some data while there is some tensor operations going on simultaneously, masking compression cost to some degree.
@mkshah5 I've been running the simulations and unfortunately at some point they fail with CUDA error at cuszx_entry.cu:987 code=700(cudaErrorIllegalAddress) "cudaMalloc(&d_newdata, nbBlocks_h*bs*sizeof(float))"
Additionally, I noticed that over time the compression ratio (data_size/compressed_size) gets smaller and slowly convergest to 1. When it gets to 1, the crash happens.
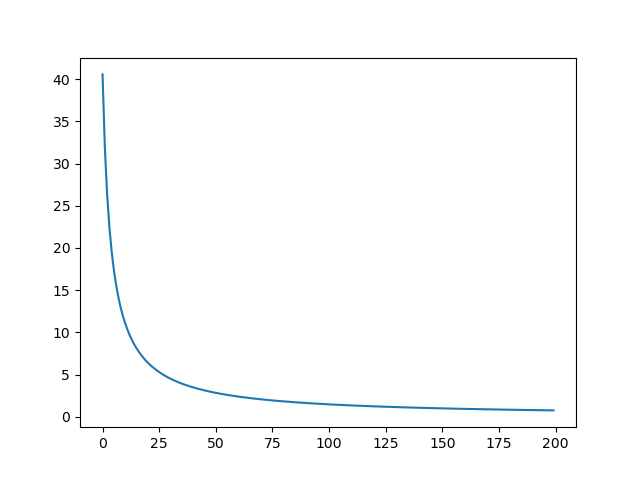
I did a small test based on test_memory_leak where I repeatedly compress and decompres for 200 times in chain. The compression ratio drops significantly. This is what it looks like for the current test file:
Could compression run asynchronously? If so, we could have the GPU compress some data while there is some tensor operations going on simultaneously, masking compression cost to some degree.
Yes, this is something that potentially can be done. I don't have a lot of experience with GPU programming, so I'm not sure how to achieve this. It seems we would need to use two cuda streams?
@mkshah5 I've been running the simulations and unfortunately at some point they fail with
CUDA error at cuszx_entry.cu:987 code=700(cudaErrorIllegalAddress) "cudaMalloc(&d_newdata, nbBlocks_h*bs*sizeof(float))"Additionally, I noticed that over time the compression ratio (data_size/compressed_size) gets smaller and slowly convergest to 1. When it gets to 1, the crash happens.
I did a small test based on test_memory_leak where I repeatedly compress and decompres for 200 times in chain. The compression ratio drops significantly. This is what it looks like for the current test file:
I will take a look at this, I am guessing there is still some sort of memory leak.
Could compression run asynchronously? If so, we could have the GPU compress some data while there is some tensor operations going on simultaneously, masking compression cost to some degree.
Yes, this is something that potentially can be done. I don't have a lot of experience with GPU programming, so I'm not sure how to achieve this. It seems we would need to use two cuda streams?
We can try using multiple streams. CuPy has support for multiple streams, maybe if the CuPy operations are using a non-default stream?
@mkshah5 I've been running the simulations and unfortunately at some point they fail with
CUDA error at cuszx_entry.cu:987 code=700(cudaErrorIllegalAddress) "cudaMalloc(&d_newdata, nbBlocks_h*bs*sizeof(float))"Additionally, I noticed that over time the compression ratio (data_size/compressed_size) gets smaller and slowly convergest to 1. When it gets to 1, the crash happens.
I did a small test based on test_memory_leak where I repeatedly compress and decompres for 200 times in chain. The compression ratio drops significantly. This is what it looks like for the current test file:
This compression ratio degradation seems to have been fixed with the latest commit. There was an incorrect variable initialization. When running test_memory_leak, there seems to be consistent CR now. I'll keep looking for memory leaks that may be causing the CUDA error you mentioned here. Are there any particular sizes for input data that you notice have this error?
When running test_memory_leak, there seems to be consistent CR now. I'll keep looking for memory leaks that may be causing the CUDA error you mentioned here. Are there any particular sizes for input data that you notice have this error?
I can confirm that the CR issue is fixed, thank you! Now it's running well and I didn't have the "illegal address" error so far. I can also see that compression actually matters, allowing to simulate larger circuits that otherwise don't fit in memory.
@danlkv Commit 12dd9c0 has some updates to the post processing of the device compress function. Based on tests with test_memory_leak, the compress function (including mallocs, memcpys, and kernel runs) is about 7-10x faster. I am going to take a look at the preprocessing for decompress next and find ways to optimize this portion.
Referenced commit: https://github.com/danlkv/QTensor/pull/41/commits/12dd9c0e89500008b44c2f28196835b5a87f27ed
@mkshah5 I'm getting some strange compression timings:
Compression end timestamp: 6482.277344 ms
CUDA Error: no error
Compress: Measure: 6.961s, 256.00MB -> 2.22MB (115.254 in/out ratio)
CUDA Error: no error
GPU decompression timing: 1.585152 ms
@mkshah5 I'm getting some strange compression timings:
Compression end timestamp: 6482.277344 ms CUDA Error: no error Compress: Measure: 6.961s, 256.00MB -> 2.22MB (115.254 in/out ratio) CUDA Error: no error GPU decompression timing: 1.585152 ms
I can take a look. Can you send me the data that you are trying to compress or how should I reproduce this?
I pushed a preprocessing file. The circuit is pretty large, but you can see the timings early on before it gets too big.
To test, go to bench/qc_simulation and run ./main.py simulate ./data/preprocess/qaoa_maxcut/3reg_N256_p1.jsonterms_Otamaki_120_M30 ./data/simulations/qaoa_maxcut/{in_file}_cM{M} --sim qtensor -M 25 --backend=cupy --compress=szx
I will be pushing a commit later tonight, it should be faster but I am trying to find an even faster solution.On Mar 16, 2023, at 8:41 AM, Danil Lykov @.***> wrote: @mkshah5 Any updates on the compression speed?
—Reply to this email directly, view it on GitHub, or unsubscribe.You are receiving this because you were mentioned.Message ID: @.***>
@mkshah5 Thanks! I am seeing around 0.1-1 GB/s throughput. Sometimes I see some inconsistency between python and c time measures:
CUDA Error: no error
GPU decompression timing: 1.644544 ms
Decompress: Measure: 12.007s, 33.51MB -> 2048.00MB (0.016 in/out ratio)
Here the actual time is 10x larger than measured by C. What could be the cause of this?
@mkshah5 I added a smaller instance for local tests. Run from bench/qc_simulation:
./main.py simulate ./data/preprocess/qaoa_maxcut/3reg_N52_p3.jsonterms_Otamaki_3_M30 ./data/simulations/qaoa_maxcut/{in_file}_cM{M} --sim qtensor -M 25 --backend=cupy --compress=szx
This creates a json file with stats for each compression/decompression.
@mkshah5 I can see that decompression times dropped by ~100x, that's great! The compression throughput is now the bottleneck, being about 0.2 GB/s. Is it possible to improve this?
@mkshah5 I can see that decompression times dropped by ~100x, that's great! The compression throughput is now the bottleneck, being about 0.2 GB/s. Is it possible to improve this?
I have been working on this, unfortunately I am running out of optimizations to perform. Have you tried using a non-default CUDA stream such that we can have overlapping execution of the compressor and the simulation? This may hide some of the compress latency.
https://github.com/danlkv/QTensor/pull/41/commits/0af7bc6b8139b02392c00cdb3ad145dcf9b02283
This commit should actually be significantly better for compress throughput :-). I recommend testing this on your local machine.
This is the test script I use for benchmark (it's a bit smaller than the previous one):
./main.py simulate ./data/preprocess/qaoa_maxcut/3reg_N52_p3.jsonterms_Otamaki_3_M30 ./data/simulations/qaoa_maxcut/{in_file}_cM{M} --sim qtensor -M 25,26,27 --backend=cupy --compress=szx```
@mkshah5 Here's a line profile fo cuszx_wrapper compression:
Total time: 3.50393 s
File: /home/danlkv/qsim/QTensor/qtensor/compression/szx/src/cuszx_wrapper.py
Function: cuszx_device_compress at line 71
Line # Hits Time Per Hit % Time Line Contents
==============================================================
71 @profile
72 def cuszx_device_compress(oriData, absErrBound, nbEle, blockSize,threshold):
73 14 15.3 1.1 0.0 start = time.time()
74 14 1907.0 136.2 0.1 __cuszx_device_compress = get_device_compress()
75
76 14 7.0 0.5 0.0 load = time.time()
77 14 11.1 0.8 0.0 variable = ctypes.c_size_t(0)
78 14 21.5 1.5 0.0 outSize = ctypes.pointer(variable)
79 14 1700882.0 121491.6 48.5 absErrBound = absErrBound*(cp.amax(oriData.get())-cp.amin(oriData.get()))
80 14 1660203.0 118585.9 47.4 threshold = threshold*(cp.amax(oriData.get())-cp.amin(oriData.get()))
81 14 251.8 18.0 0.0 oriData_p = ctypes.cast(oriData.data.ptr, ctypes.POINTER(c_float))
82
83 14 140586.0 10041.9 4.0 o_bytes = __cuszx_device_compress(oriData_p, outSize,np.float32(absErrBound), np.ulonglong(nbEle), np.int32(blockSize),np.float32(threshold))
84 14 38.9 2.8 0.0 end = time.time()
85
86 14 5.0 0.4 0.0 return o_bytes, outSize
@mkshah5
Why do you have .get()?
Returns a copy of the array on host memory.
I hope this doesn't mean we copy the data 4 times to host and back 🥲
Also, this code calculates the same thing twice:
79 absErrBound = absErrBound*(cp.amax(oriData.get())-cp.amin(oriData.get()))
1 threshold = threshold*(cp.amax(oriData.get())-cp.amin(oriData.get()))