asammdf
 asammdf copied to clipboard
asammdf copied to clipboard
Problem with timestamps when reading different channels.
Python version
'python=3.8.8 (default, Apr 13 2021, 15:08:03) [MSC v.1916 64 bit (AMD64)]'
'os=Windows-10-10.0.18362-SP0'
'numpy=1.21.4'
'asammdf=6.4.4'
Code
MDF version
4.11
Code snippet
tyres = ["FALI", "FALO", "FARI", "FARO", "RALO", "RARO"]
required_channels += ["TIRE2_" + tyre + "_TireLocation",
"TIRE2_" + tyre + "_TirePressure_ext",
"TIRE1_" + tyre + "_TireTemperature",
"TIRE1_" + tyre + "_TirePressThreshDetec",
"TIRE2_" + tyre + "_Tire_Ref_Pressure_ext"]
mdf = MDF('Malta_Data/E214E01752T_R1__211110_080325.mf4', channels=required_channels).to_dataframe(time_as_date=True, empty_channels='skip', reduce_memory_usage=True)
Description
This is the data that I have when reading through asamMDF GUI in windows.
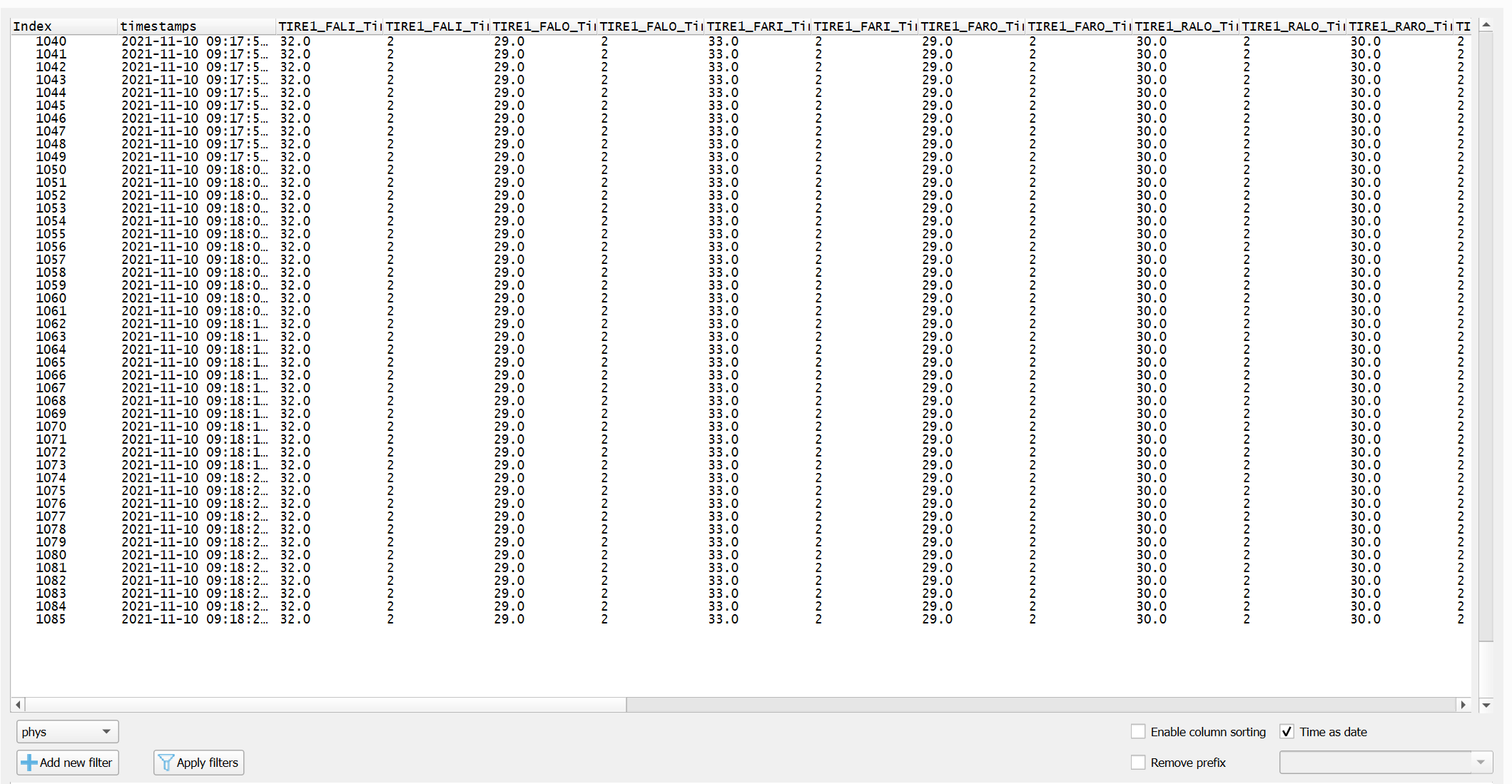
It contains 1085 rows. However, the records are not the same when I import and read them through asammdf library with Python
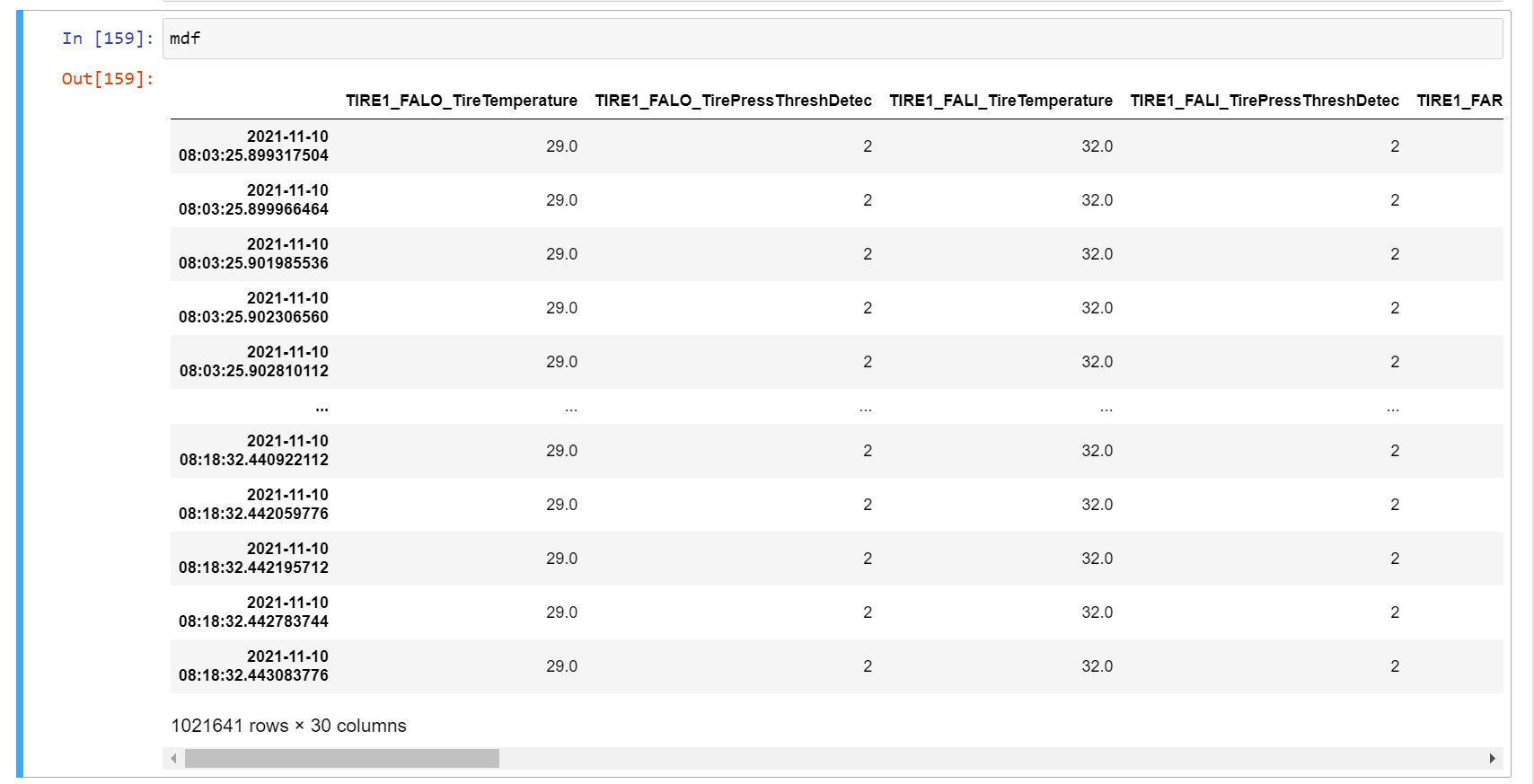
Here, it shows that I have 1021641 rows The columns that I select in asamMDF GUI and in asamMDF with Python are the same.
Can anyone provide me with a solution to fix that?
Really appreciated.
Hello,
do you use exactly the same channels in the GUI and using the API?
Maybe the channels appear multiple times in the file. What is the output of this?
mdf = MDF(filename)
for name in required_channels:
print(name, mdf.channels_db[name])
Yeah, I also think that the channels appear multiple times in the file.
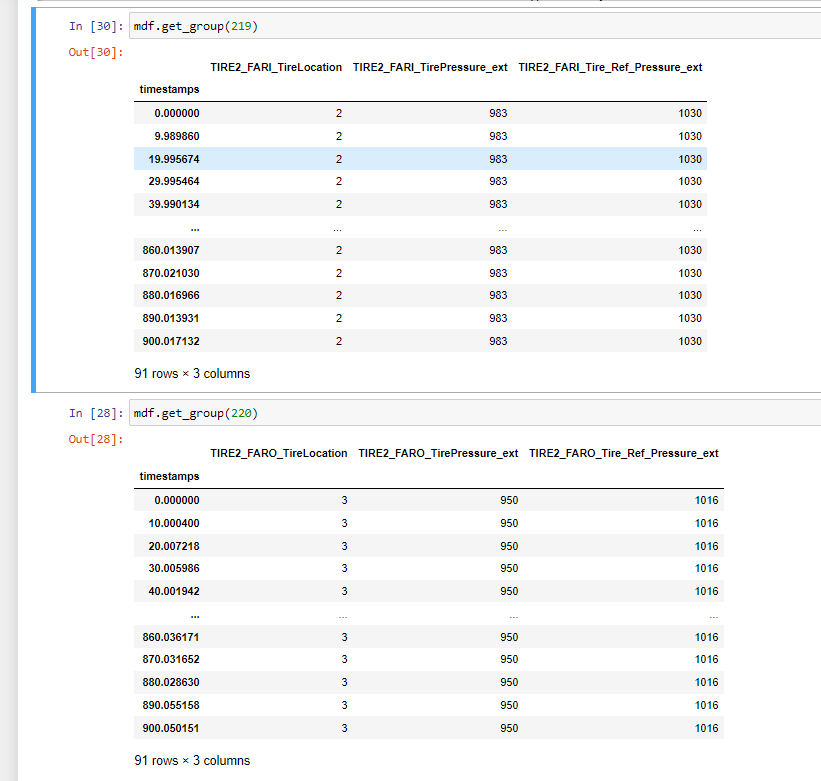
This is the output from the code you provided above 👍
TIRE2_FALI_TireLocation ((93, 1), (218, 1))
TIRE2_FALI_TirePressure_ext ((93, 2), (218, 2))
TIRE1_FALI_TireTemperature ((87, 3), (212, 3))
TIRE1_FALI_TirePressThreshDetec ((87, 9), (212, 9))
TIRE2_FALI_Tire_Ref_Pressure_ext ((93, 3), (218, 3))
TIRE2_FALO_TireLocation ((92, 1), (217, 1))
TIRE2_FALO_TirePressure_ext ((92, 2), (217, 2))
TIRE1_FALO_TireTemperature ((86, 3), (211, 3))
TIRE1_FALO_TirePressThreshDetec ((86, 9), (211, 9))
TIRE2_FALO_Tire_Ref_Pressure_ext ((92, 3), (217, 3))
TIRE2_FARI_TireLocation ((96, 1), (219, 1))
TIRE2_FARI_TirePressure_ext ((96, 2), (219, 2))
TIRE1_FARI_TireTemperature ((90, 3), (213, 3))
TIRE1_FARI_TirePressThreshDetec ((90, 9), (213, 9))
TIRE2_FARI_Tire_Ref_Pressure_ext ((96, 3), (219, 3))
TIRE2_FARO_TireLocation ((97, 1), (220, 1))
TIRE2_FARO_TirePressure_ext ((97, 2), (220, 2))
TIRE1_FARO_TireTemperature ((91, 3), (214, 3))
TIRE1_FARO_TirePressThreshDetec ((91, 9), (214, 9))
TIRE2_FARO_Tire_Ref_Pressure_ext ((97, 3), (220, 3))
TIRE2_RALO_TireLocation ((94, 1), (221, 1))
TIRE2_RALO_TirePressure_ext ((94, 2), (221, 2))
TIRE1_RALO_TireTemperature ((88, 3), (215, 3))
TIRE1_RALO_TirePressThreshDetec ((88, 9), (215, 9))
TIRE2_RALO_Tire_Ref_Pressure_ext ((94, 3), (221, 3))
TIRE2_RARO_TireLocation ((95, 1), (222, 1))
TIRE2_RARO_TirePressure_ext ((95, 2), (222, 2))
TIRE1_RARO_TireTemperature ((89, 3), (216, 3))
TIRE1_RARO_TirePressThreshDetec ((89, 9), (216, 9))
TIRE2_RARO_Tire_Ref_Pressure_ext ((95, 3), (222, 3))
I think the Asam GUI merges all the nearest timestamps records together. Is there anyway to do the same in asamMDF python ?
I need to check in the morning how the channels are selected in both cases. How do you create the Tabular window in the GUI: drag and drop from the channels tree or using the search dialog?
I need to check in the morning how the channels are selected in both cases. How do you create the Tabular window in the GUI: drag and drop from the channels tree or using the search dialog?
I just select multiple channels from the list on the left then drag and drop.
Looking forward to your solution. Thank you so much
Do you have the "Internal file view" or the "Natural sort" for the channels tree?
Do you have the "Internal file view" or the "Natural sort" for the channels tree?
I choose Natural Sort for the channels tree
when you use the API all the channels are exported in the dataframe. Some of the channels have a high sampling rate, and in the end all the channels are interpolated using the union of all unique time stamps, resulting in a large 1021641 rows dataframe
For the GUI you are probably selecting the occurrences with a small sampling rate, and the Tabular window has only 1085 rows
when you use the API all the channels are exported in the dataframe. Some of the channels have a high sampling rate, and in the end all the channels are interpolated using the union of all unique time stamps, resulting in a large 1021641 rows dataframe
For the GUI you are probably selecting the occurrences with a small sampling rate, and the Tabular window has only 1085 rows
Is there anyway I can do minimize the dataframe ?since I have multiple mdf4 files and it will be really hard for me to do analysis later if I have this amount of rows for each mdf4 file.
Yes. You can avoid the interpolation by reading one dataframe for each group. You can use the function iter_groups for this. Example:
from pathlib import Path
from asammdf import MDF
path = Path("my_file.mdf")
channels = ["channel_1", "channel_2"]
with MDF(path) as mdf:
filtered_mdf = mdf.filter(channels)
dataframes = list(filtered_mdf.iter_groups())