viet-asr
 viet-asr copied to clipboard
viet-asr copied to clipboard
Published
20 hours ago •
 dangvansam
dangvansam
VietASR - Vietnamese Automatic Speech Recognition
VietASR (Vietnamese Automatic Speech Recognition)
⚡ Some experiment with NeMo ⚡ Result
- Model: QuartzNet is a smaller version of Jaser model
- I list the word error rate (WER) with and without LM of major ASR tasks.
| Task | CER (%) | WER (%) | +LM WER (%) |
|---|---|---|---|
| VIVOS (TEST) | 6.80 | 18.02 | 15.72 |
| VLSP2018 | 6.87 | 16.26 | N/A |
| VLSP2020 T1 | 14.73 | 30.96 | N/A |
| VLSP2020 T2 | 41.67 | 69.15 | N/A |
Model was trained with ~500 hours Vietnamese speech dataset, was collected from youtube, radio, call center(8k), text to speech data and some public dataset (vlsp, vivos, fpt). It is very small model (13M parameters) make it inference so fast ⚡
Installation
- ctcdecoder, kemlm for LM Decode
pip install ds-ctcdecoder - and some python libraries:
torch, numpy, librosa, flask, flask_socketio, requests,...
Demo
- Vietnamese Model (pretrained):
python flask_upload_record_vn.py - Video demo in Youtube:
- v1: https://youtu.be/P3mhEngL1us
- v2: https://youtu.be/o9NpWi3VUHs
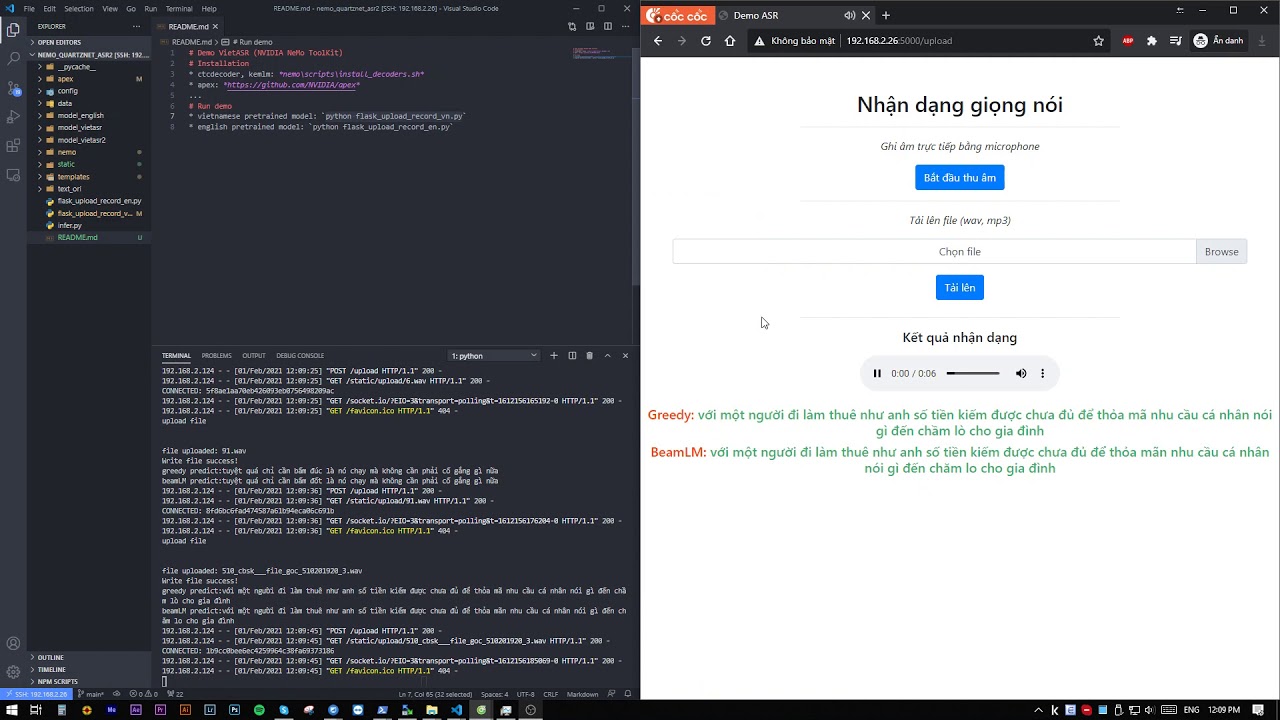
- English Model (pretrained):
python flask_upload_record_en.py
TODO
- Conformer Model
- Transformer LM instead of kenlm
- Data augumentation: speed, noise, pitch shift, time shift,...
- FastAPI
Citation
@article{kuchaiev2019nemo,
title={Nemo: a toolkit for building ai applications using neural modules},
author={Kuchaiev, Oleksii and Li, Jason and Nguyen, Huyen and Hrinchuk, Oleksii and Leary, Ryan and Ginsburg, Boris and Kriman, Samuel and Beliaev, Stanislav and Lavrukhin, Vitaly and Cook, Jack and others},
journal={arXiv preprint arXiv:1909.09577},
year={2019}
}
Metadata
90
Stars
42
Forks
Watchers
Owner
Metadata
VietASR - Vietnamese Automatic Speech Recognition