Alexandre Flament
Alexandre Flament
Possible solution: * disable wikidata (actually it would help the wikidata servers which are already hammered with a lot SPARQL queries). * enable duckduckgo_definition.
> Is there a check if the page exist before trying to fetch the data? TLDR: no, but * may be * it is possible to optimize the response time...
> Another problem is that the IP is read from a header. * Caddy: https://caddyserver.com/docs/caddyfile/directives/reverse_proxy#defaults * Traefik: https://doc.traefik.io/traefik/v2.1/routing/entrypoints/#forwarded-header
> 'Hash plugin' uses server CPU and this functionality doesn't need to be necessary wanted what the public hoster want's to provide to users Note: If you enable the image...
In both cases we have to change settings.yml. * `blocked_plugins` is compatible with the existing configurations, but it adds a third options about the plugins. * `plugins` breaks the compatibility...
I'm in favor of something like this: ```yaml plugins: searx.plugins.self_info: load: false # plugin in searx.plugins are automatically loaded, "load: false" prevent to load on a plugin searx.plugins.hash_plugin: enabled_by_default: false...
FWIW, I don't have the issue on my personal instance
Still on my instance: | :fr | :de | | --- | --- | | 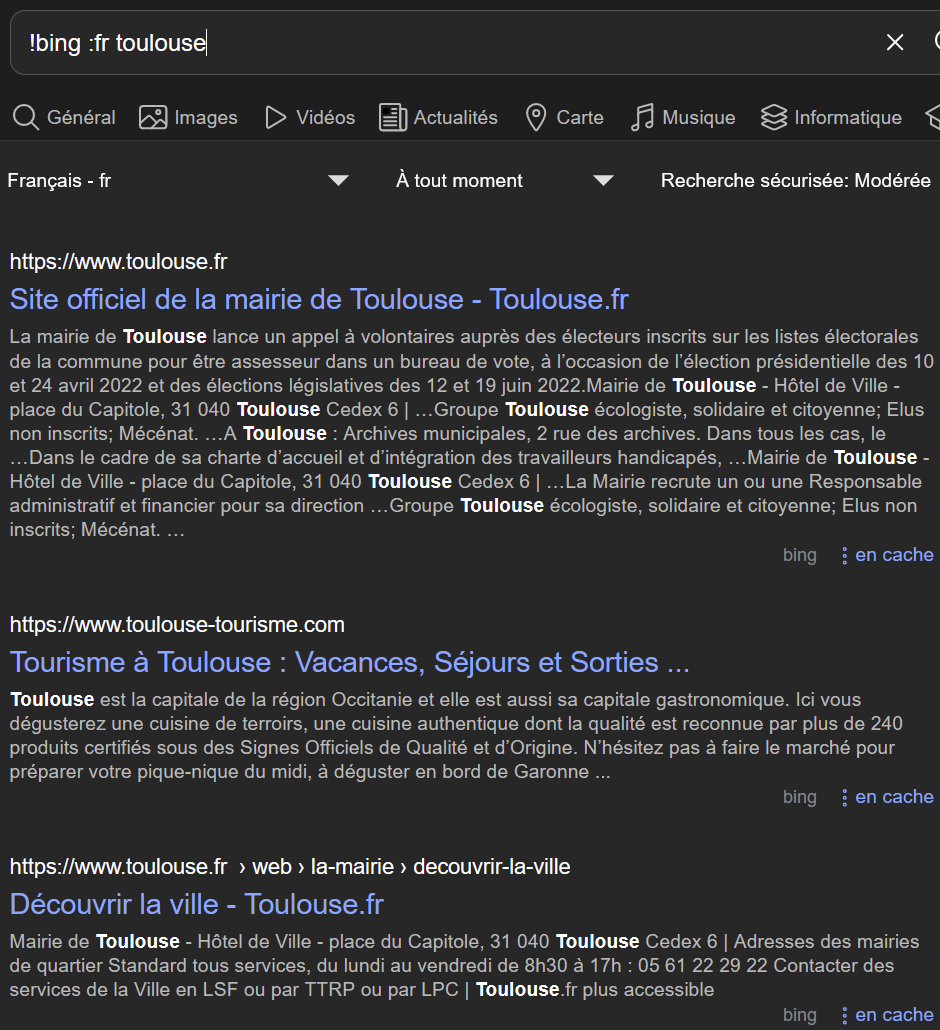 | 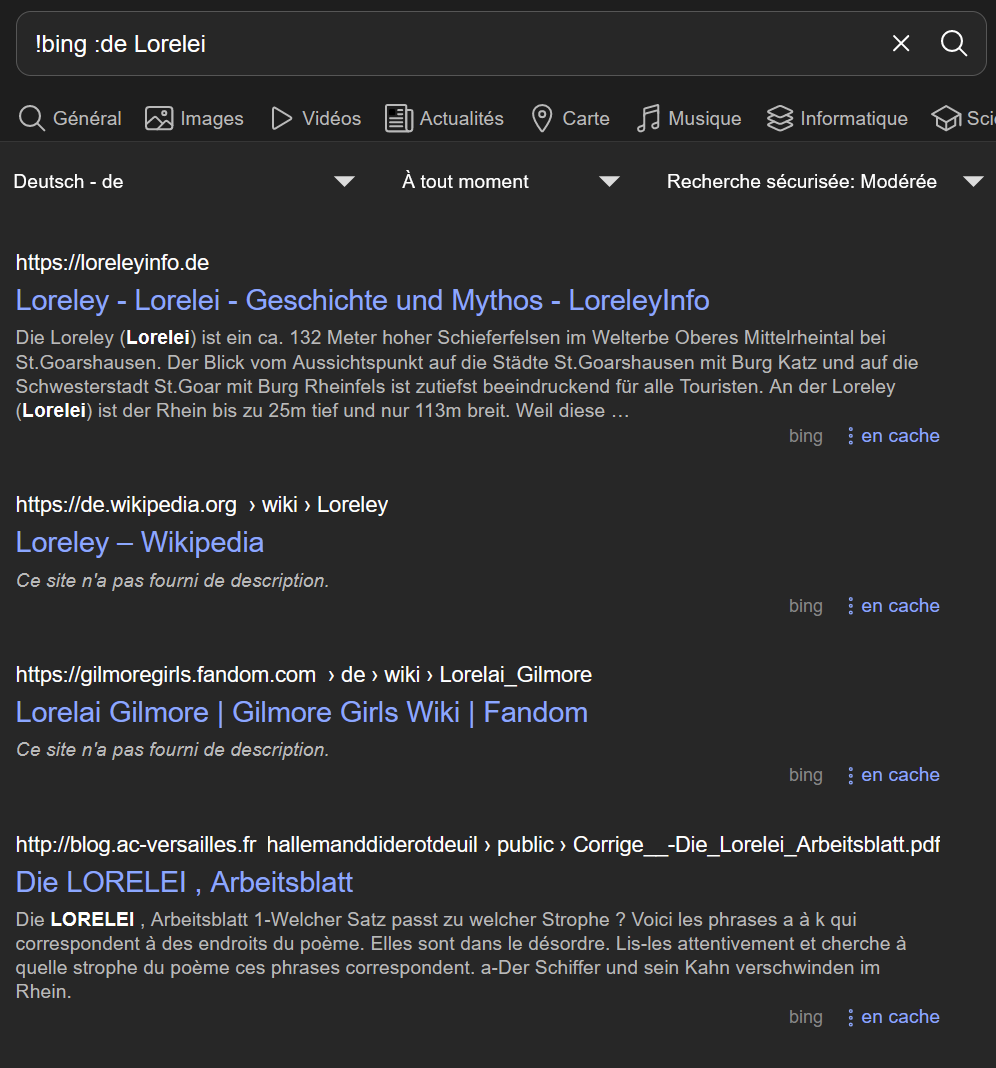 | But I've experienced some HTTP Connection Error
https://github.com/searxng/searxng/blob/61535a4c206aa247a6fa87697b70668048086e27/searx/query.py#L156 --> `value = raw_value[2:].lower()` should be enough (not tested) --- may be the same thing can be done for the SearXNG bang: https://github.com/searxng/searxng/blob/61535a4c206aa247a6fa87697b70668048086e27/searx/query.py#L183 --> `value = raw_value[1:].replace('-', ' ').replace('_',...
Most probably it can integrate with the mediawiki engine: https://github.com/searxng/searxng/blob/61535a4c206aa247a6fa87697b70668048086e27/searx/settings.yml#L542-L557 --- Side note: this is where I would to be able to create repository of additional engines ( https://github.com/searxng/searxng/issues/534 )....