pytorch
 pytorch copied to clipboard
pytorch copied to clipboard
Published
20 hours ago •
 csarofeen
csarofeen
HuggingFace BertForMaskedLM - Bad Loss Function Perf
🐛 Describe the bug
Benchmark Command:
python -u benchmarks/huggingface.py --training -d cuda --fast --backend nvprims_nvfuser --skip-accuracy-check --performance --only BertForMaskedLM --amp
Log_Softmax is notably not being fused even though we can fuse it as well as the rest of the loss function. This looks to be about a 3% perf improvement. Inductor is saving >2ms with this optimization.
With nvFuser:
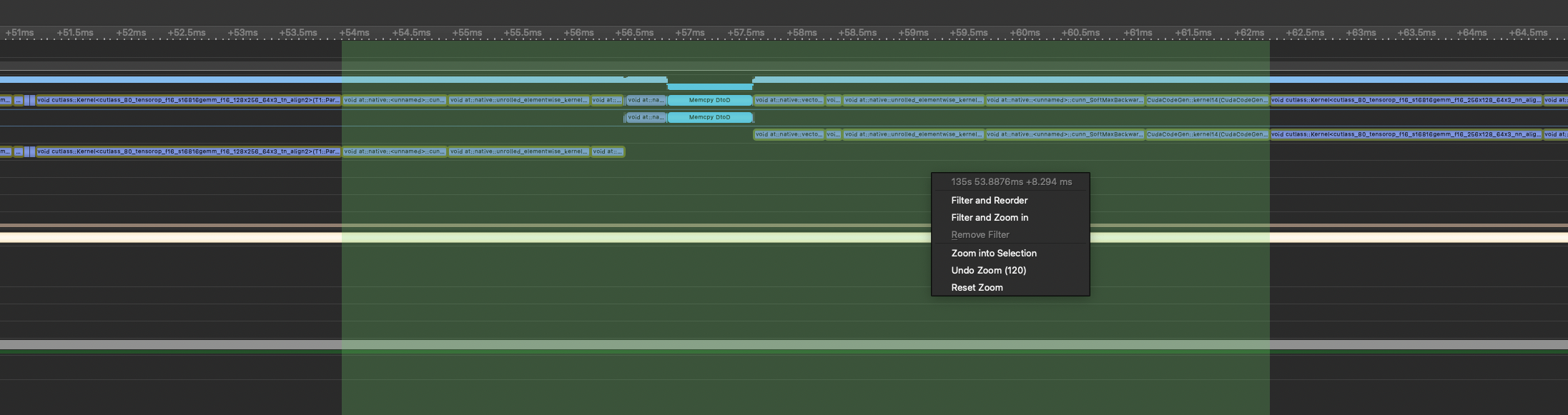
With Inductor:
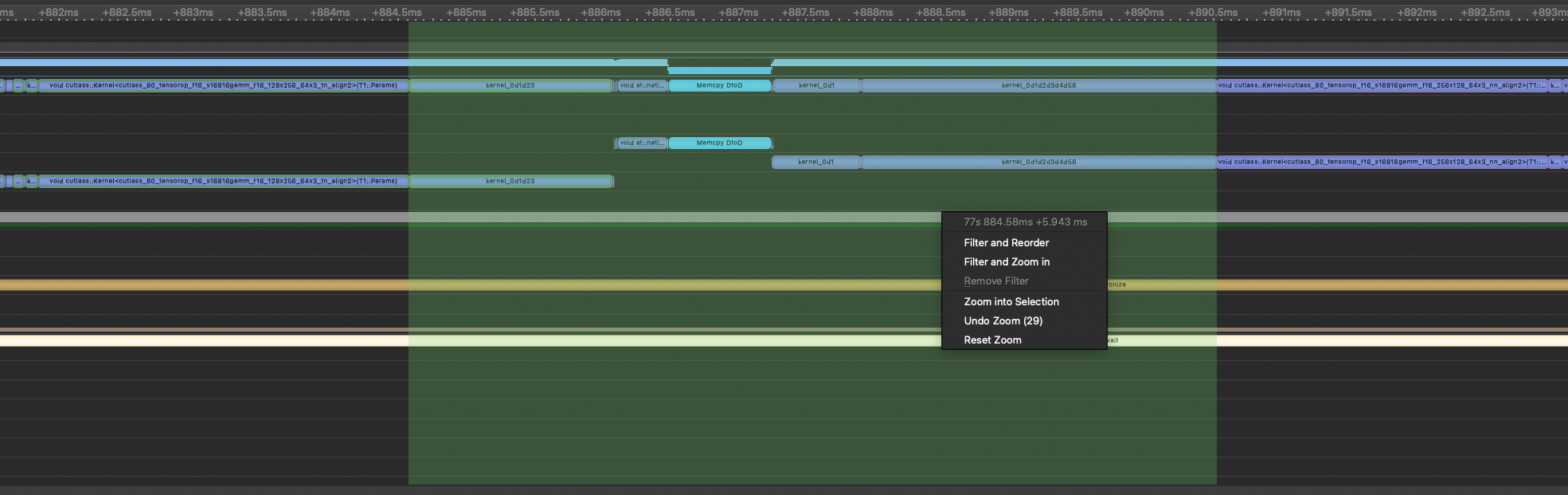
Versions
csarofeen/torchbenchPerf
We don't have the ability to fuse the loss function without supporting gather.
@register_decomposition(aten.nll_loss_forward)
def nll_loss_forward(
self: Tensor,
target: Tensor,
weight: Optional[Tensor],
reduction: int,
ignore_index: int,
) -> Tuple[Tensor, Tensor]:
assert self.dim() > 0 and self.dim() <= 2, "input tensor should be 1D or 2D"
assert (
target.dim() <= 1
), "0D or 1D target tensor expected, multi-target not supported"
no_batch_dim = self.dim() == 1 and target.dim() == 0
assert no_batch_dim or (
self.shape[0] == target.shape[0]
), f"size mismatch (got input: {self.shape}, target: {target.shape})"
n_classes = self.shape[-1]
assert weight is None or (
weight.dim() == 1 and weight.numel() == n_classes
), f"weight tensor should be defined either for all {n_classes} classes or no classes but got weight tensor of shape: {weight.shape}" # noqa: B950
# self can be [N, C] or [C]
# target can be [N] or []
n_dims = self.dim()
channel_dim = 1
if n_dims < 2:
channel_dim = 0
if weight is not None:
w = weight.unsqueeze(0) if n_dims > 1 else weight
self = self * w
target_ = target.unsqueeze(channel_dim)
# target can be [N, 1] or [1]
result = -torch.gather(self, channel_dim, target_).squeeze(channel_dim)
if ignore_index >= 0:
result = torch.where(target != ignore_index, result, 0)
if reduction == Reduction.NONE.value and n_dims > 1:
total_weight = self.new_full((), 0.0)
return result, total_weight
if weight is not None:
w = weight.unsqueeze(0).expand(self.shape) if n_dims > 1 else weight
wsum = torch.gather(w, channel_dim, target_).squeeze(channel_dim)
if ignore_index >= 0:
wsum = torch.where(target != ignore_index, wsum, 0)
total_weight = wsum.sum()
elif ignore_index >= 0:
total_weight = (target != ignore_index).sum().to(self)
else:
total_weight = self.new_full((), 1.0 * result.numel())
if reduction == Reduction.SUM.value:
result = result.sum()
elif reduction == Reduction.MEAN.value:
if weight is None:
result = result.sum() / total_weight if ignore_index >= 0 else result.mean()
else:
result = result.sum() / total_weight
return result, total_weight