chain-indexing
 chain-indexing copied to clipboard
chain-indexing copied to clipboard
Problem: Current projection design is not scalable
Currently, as Crypto.org Chain has more than 3 million blocks, it takes a long time for a newly indexing server to catch up the latest block height.
This will force us to spend a long time in:
- re-indexing existing projections
- deploying and testing newly introduced projections
One possible solution is to make use of EVENT_STORE mode. I think a more efficient way to catch up would be:
EVENT_STOREmode indexing server starts to fetch block data and write to DB.- Each projection creates multiple goroutines, to parallel handle these blocks.
- After catching up to the latest height, each projection may only need one goroutine to continue working.
The difficulty here I think is mainly on Step 2, as for some projections, we have the assumption that the blocks come in an ordered manner. So to fulfill the parallel handling purpose, these projections might need refactoring.
Copying the findings from last re-indexing here
Partial Re-index On Specific Projections
- Transaction
- AccountMessage
- AccountTransaction
- IBCChannel (IBCChannelTxMsgTrace for staging)
- IBCChannelMessage
Full Re-index On Clean DB
During the re-indexing, we found some performance issues on Crypto.org Chain mainnet indexing.
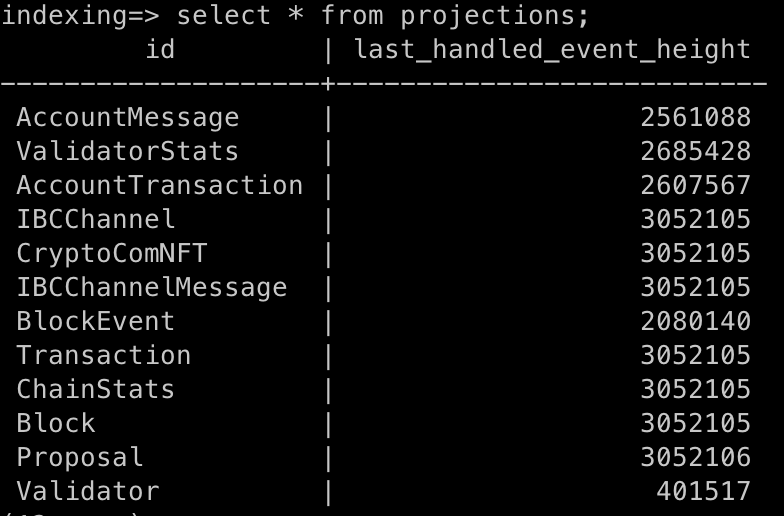
The above image shows that, starting from a clean DB, after around 2 days of running, some projections are still catching up the latest block height.
The slowest one is the
Validatorprojection, I already created a PR to improve it. #593There are some other projections could also be optimized, we might take a closer look into them later:
- AccountMessage
- BlockEvent
- AccountTransaction
- ValidatorStats