spark-excel
 spark-excel copied to clipboard
spark-excel copied to clipboard
[BUG] Cannot read files into dataframe in Databricks 9.1 LTS Runtime 3.1.2 Spark
Is there an existing issue for this?
- [X] I have searched the existing issues
Current Behavior
Below is my set up spark.conf.set("fs.azure.account.auth.type." + storageAccountName + ".dfs.core.windows.net", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type." + storageAccountName + ".dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id." + storageAccountName + ".dfs.core.windows.net", "" + appID + "") spark.conf.set("fs.azure.account.oauth2.client.secret." + storageAccountName + ".dfs.core.windows.net", "" + password + "") spark.conf.set("fs.azure.account.oauth2.client.endpoint." + storageAccountName + ".dfs.core.windows.net", "https://login.microsoftonline.com/" + tenantID + "/oauth2/token")
com.crealytics:spark-excel-2.12.17-3.1.2_2.12:3.1.2_0.18.1
tried to check %fs ls - files are getting listed as expected I can read csv files from the path on gen2 storage
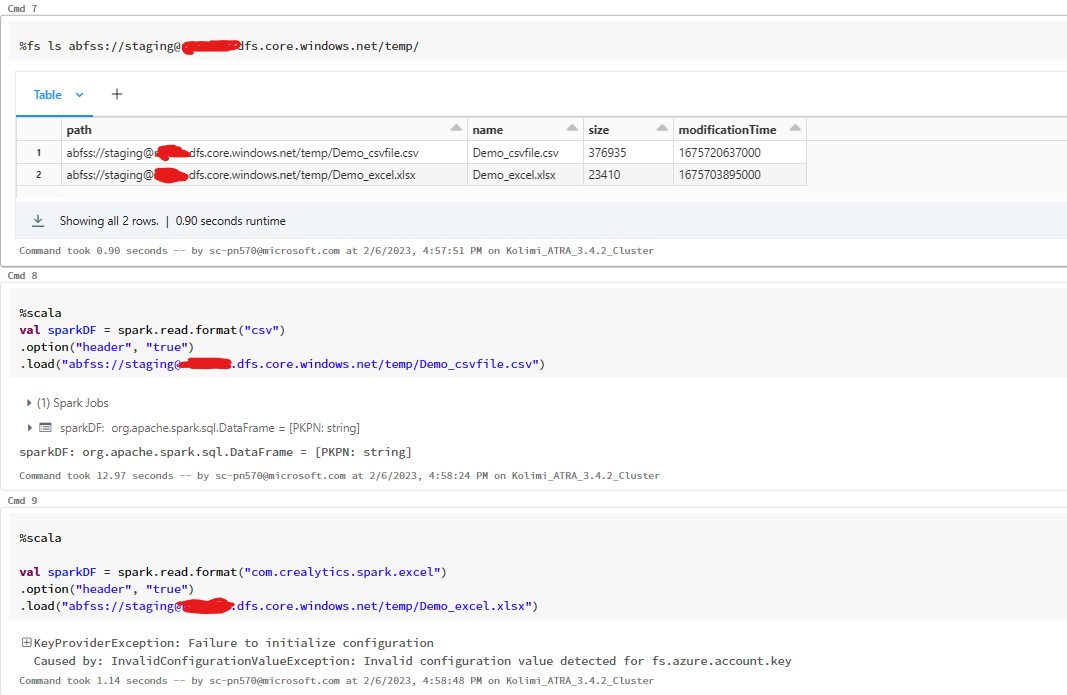
Expected Behavior
I would expect to read excel file into a dataframe and not get below error
get InvalidConfigurationValueException: Invalid configuration value detected for fs.azure.account.key
Steps To Reproduce
No response
Environment
- Spark version:3.1.2
- Spark-Excel version: com.crealytics:spark-excel-2.12.17-3.1.2_2.12:3.1.2_0.18.1
- OS: Windows 10
- Cluster environment : 9.1 LTS
Anything else?
No response
Please check these potential duplicates:
- [#682] [BUG] Cannot read files into dataframe in Databricks 11.3 LTS Runtime 3.3.0 Spark (75.91%) If this issue is a duplicate, please add any additional info to the ticket with the most information and close this one.
for what its worth (as i was troubleshooting similar yesterday and struggling to find anything other than actually using an account key or SAS key) This article provides a workaround https://stackoverflow.com/questions/73864385/invalid-configuration-value-detected-for-fs-azure-account-key-with-com-crealytic/73865969#73865969 which worked for us with com.crealytics:spark-excel-2.12.17-3.2.2_2.12:3.2.2_0.18.1 and using "excel"
replacing spark.conf.set with spark._jsc.hadoopConfiguration().set
eg
spark._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage-account>.dfs.core.windows.net", "OAuth")
spark._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage-account>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage-account>.dfs.core.windows.net", "<application-id>")
spark._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage-account>.dfs.core.windows.net", service_credential)
spark._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage-account>.dfs.core.windows.net", "https://login.microsoftonline.com/<directory-id>/oauth2/token")
Spark Version: 3.2.1 Databricks Runtime: 10.4LTS
In our scenario, setting a property on the spark context instead of the spark session is not an option. The same configs that work when setting on spark session for reading other files do not work with excel. Our setup may be a bit different because we are using a refresh token for authentication instead of client credentials, but nonetheless using spark session properties should still work.
spark.conf.set(f'fs.azure.account.auth.type', 'OAuth') spark.conf.set(f'fs.azure.account.oauth.provider.type', 'org.apache.hadoop.fs.azurebfs.oauth2.RefreshTokenBasedTokenProvider') spark.conf.set(f'fs.azure.account.oauth2.refresh.token', refresh_token) spark.conf.set(f'fs.azure.account.oauth2.refresh.endpoint', f'https://login.microsoftonline.com/{tenant_id}/oauth2/token') spark.conf.set(f'fs.azure.account.oauth2.client.id', client_id)
I tried setting the configs with and without storage account, but they seem to only work when set on spark context and not spark session. This issue persists in v1 and v2 of this library. @nightscape I plan on looking deeper at this, but would you be aware of any reason why the library is only working with configs from spark context instead of spark session?
@williamdphillips in this line we're passing the HadoopConfiguration to the WorkbookReader and then use it here to actually read from the filesystem.
There might be another way to read from the Hadoop filesystem that also takes into account parameters that were set on the SparkSession.
Could you check how this is done in other readers (e.g. Parquet, Avro, CSV)?
@nightscape I see some usage of sparkSession.sessionState.newHadoopConfWithOptions(options) here, although I'm not sure where the best place to implement that would be.
Found some more information about this method here.
I'm thinking we can probably update the instantiation of WorkbookReader to be like this:
val conf = sqlContext.sparkSession.sessionState.newHadoopConf()
val wbReader = WorkbookReader(parameters, conf)
Created a draft PR (haven't tested yet due to some SBT issues): https://github.com/crealytics/spark-excel/pull/726
@nightscape Realized that for reading the issue is fixed - but PR didn't address the issue when writing. Looking through spark source code and this repo's source code to try and find where to add a similar solution.
Edit - Here is PR: https://github.com/crealytics/spark-excel/pull/728