Unexpected extropolation behavior of a simple example
Hi, I am new to GPytorch. I was trying a very simple example with training data
import torch
import gpytorch
from matplotlib import pyplot as plt
train_x = torch.arange(0, 100)
train_y = 1000-train_x + torch.randn(train_x.size()) * 0.01
The training process is very similar to the tutorial except I used LBFGS optimizer.
class ExactGPModel(gpytorch.models.ExactGP):
def __init__(self, train_x, train_y, likelihood):
super(ExactGPModel, self).__init__(train_x, train_y, likelihood)
self.mean_module = gpytorch.means.ConstantMean()
self.covar_module = gpytorch.kernels.ScaleKernel(gpytorch.kernels.RBFKernel())
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)
# initialize likelihood and model
likelihood = gpytorch.likelihoods.GaussianLikelihood()
model = ExactGPModel(train_x, train_y, likelihood)
import os
smoke_test = ('CI' in os.environ)
training_iter = 2 if smoke_test else 50
# Find optimal model hyperparameters
model.train()
likelihood.train()
# Use the adam optimizer
optimizer = torch.optim.LBFGS(model.parameters(), lr=0.01) # Includes GaussianLikelihood parameters
# "Loss" for GPs - the marginal log likelihood
mll = gpytorch.mlls.ExactMarginalLogLikelihood(likelihood, model)
def closure():
optimizer.zero_grad()
# Output from model
output = model(train_x)
# Calc loss and backprop gradients
loss = -mll(output, train_y)
loss.backward()
return loss
for i in range(training_iter):
# Zero gradients from previous iteration
optimizer.step(closure)
print('Iter %d/%d - lengthscale: %.3f noise: %.3f' % (
i + 1, training_iter,
model.covar_module.base_kernel.lengthscale.item(),
model.likelihood.noise.item()
))
model.eval()
likelihood.eval()
# Test points are regularly spaced along [0,1]
# Make predictions by feeding model through likelihood
with torch.no_grad(), gpytorch.settings.fast_pred_var():
test_x = torch.arange(0, 1000)
observed_pred = likelihood(model(test_x))
with torch.no_grad():
# Initialize plot
f, ax = plt.subplots(1, 1, figsize=(4, 3))
# Get upper and lower confidence bounds
lower, upper = observed_pred.confidence_region()
# Plot training data as black stars
ax.plot(train_x.numpy(), train_y.numpy(), 'k*')
# Plot predictive means as blue line
ax.plot(test_x.numpy(), observed_pred.mean.numpy(), 'b')
# Shade between the lower and upper confidence bounds
ax.fill_between(test_x.numpy(), lower.numpy(), upper.numpy(), alpha=0.5)
# ax.set_ylim([-3, 3])
ax.legend(['Observed Data', 'Mean', 'Confidence'])
plt.show()
The extrapolation is very strange.

In contrast, MATLAB can give a reasonable prediction
x=(1:100)';
y=1000-x+randn(size(x))*0.01;
gprMdl = fitrgp(x,y);
x_test=(1:1000)';
[ypred,~,yint] = predict(gprMdl,x_test);
scatter(x,y,'r') ; hold on;
plot(x_test,ypred,'g') % GPR predictions
patch([x_test;flipud(x_test)],[yint(:,1);flipud(yint(:,2))],'k','FaceAlpha',0.1); % Prediction intervals

Is there anything wrong with the settings?
It appears your correlation length is very small. Did your loss converge?
If so, you may have just converged to a local minimum. It's good practice with GPs to run the optimization more than once from random starting points to attempt to avoid local minima.
Hi @mikegros , thanks for your reply. Yes, I did observe the convergence of loss (which is a negative value). I also run several times but the results were the same.
@deng-cy Did you randomly initialize the starting parameters for the optimization? If you started from the same spot, L-BFGS will always take you to the same minimum.
Another possible issue:
Are you working with the data as single or double precision floats? Single precision can cause issues that I think can manifest as very small optimal correlation lengths.
@mikegros Thanks. How do I initialize the starting parameters randomly?
I tried normalizing the training data but did not help much.
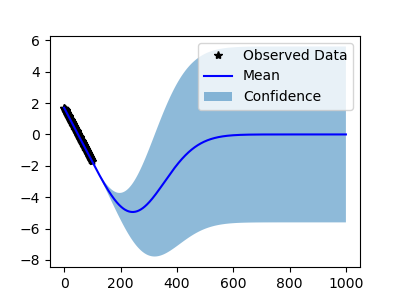
I tried double precision. The behavior is stranger: LBFGS does not converge, so gives the following
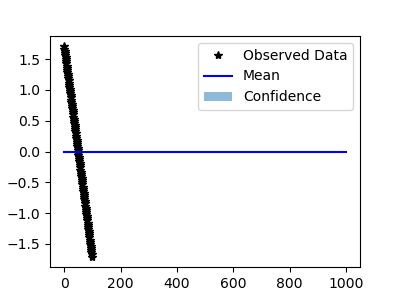
I also tried Adam, which is the same with single and double precisions.
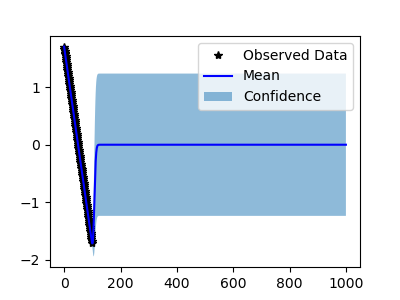
I don't think this is a random issue. The problem should be on the methodology side.
In general, this isn't "strange" extrapolation behavior for a Gp with an rbf kernel. This is a mean-reverting kernel, so you should arrive back at the mean function once you get far away from training data.
Is the matlab example using a zero mean function? The gpytorch example is using a constant mean function, with a learned constant value, which is why you are reverting to the 900-ish value
Your choice of kernel and mean function will dictate how the model extrapolates far away from training data.