Optimize multiline diff for (some metric of) edit-distance
I'm trying to use pretty-assertions for snapshot testing. I compare the snapshotted multiline-string with the new value using the PrettyString trick from #24.
When the actual result got indented (compared to the snapshot), the diff output became very confused:
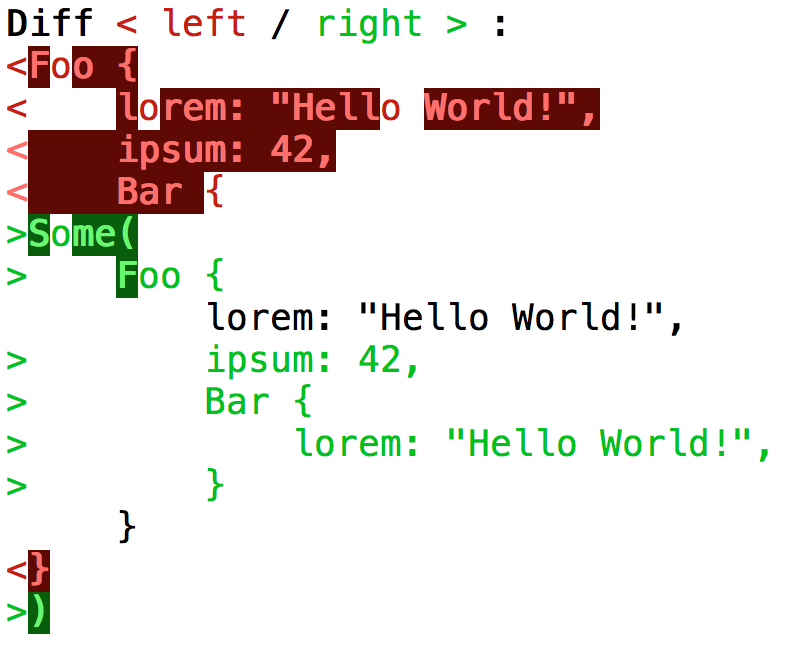
The reason is that two unrelated lines (Foo's and Bar's lorems) got matched up in the first (line-based) comparison pass, which should instead realize there's a new line Some(, followed by a few modified lines, followed by a new line ).
#[test]
fn test_multiline_diff() {
assert_eq!(PrettyString(r#"Foo {
lorem: "Hello World!",
ipsum: 42,
Bar {
lorem: "Hello World!",
}
}"#), PrettyString(r#"Some(
Foo {
lorem: "Hello World!",
ipsum: 42,
Bar {
lorem: "Hello World!",
}
}
)"#));
}
I agree, that the presentation is confusing - despite being a correct solution, it doesn´t seem to be an optimal solution.
You already mentioned, that the current heuristic algorithm is doing two passes and the first is line-based, while the second pass is character-based. Thats the problem: The first pass doesnt look at whitespaces (or any metric of edit-distance)...
I´m open for suggestions about a better algorithm. ^^ (This must have been solved before.. ;-))
I deleted a previous comment that was wildly inaccurate.
What we actually want here is
- A subjectively better diff algorithm than the
differencecrate's plain LCS, like Patience or Histogram, which is a faster version of Patience: look through the figures in https://rdcu.be/bWfbo for a sense of how much better it is than Myers, or tell Git to usediff.algorithm=histogramand try it out. - Whitespace-insensitivity in the first/line-based pass. A newtype wrapper over
&strthat implements ~~(Partial)Ord~~ (Partial)Eq by ignoring consecutive whitespace would do this without infecting the diff algorithm code. Is this desirable for all pretty-assertions, or would it need to be configurable? I would guess it could be applied everywhere. Any absolute differences in the entire debug string, including whitespace, should still cause test failure IMO. A 'no diff output, which indicates changes in whitespace only' message would help.
Edit: it would also need to implement Hash with the same whitespace-ignoring strategy to work with Histogram/Patience. Also that paper's on arXiv https://arxiv.org/abs/1902.02467